



Googles Imagen Model Better than DALLE-2?
Last Updated on May 30, 2022 by Editorial Team
Author(s): Mohit Varikuti
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Google's model seems to outperform OpenAI’s, or does it?
If you thought Dall-E 2 delivered impressive results, wait till you see what this latest Google Brain model can accomplish. Dalle-e is fantastic, but it frequently lacks realism, which the team sought to address using Imagen, a new model. On their project website, they publish a number of results as well as a benchmark that they created for evaluating text-to-image models, where they clearly surpass Dall-E 2 and earlier picture creation algorithms.
As we examine more and more text-to-image algorithms, it’s becoming increasingly impossible to compare the results — unless we assume the results are terrible, which we frequently do.
But this model, as well as Dell-e 2, defy the odds.
tl;dr: It’s a new text-to-image model that’s comparable to Dalle-E 2, but according to human testers, it’s more realistic.

So, similar to Dall-E, which I wrote about a month ago, this model takes text like “A golden Retriever dog wearing a blue checkered beret and red dotted turtle neck” and tries to make a photorealistic image out of it.
The major point here is that Imagen can grasp not only text but also the visuals it makes, which are more realistic than any prior efforts.
Of course, when I say understand, I’m referring to its own distinct understanding from ours. The model is unable to comprehend the text or image it creates. It undoubtedly knows something about it, but it mostly comprehends how this specific type of text including these items should be portrayed using pixels on an image. However, when we examine the results, it certainly appears like it understands what we send it!

You can obviously fool it with some bizarre sentences that don’t appear real, such as this one, but it occasionally outsmarts your imagination and makes something truly remarkable.
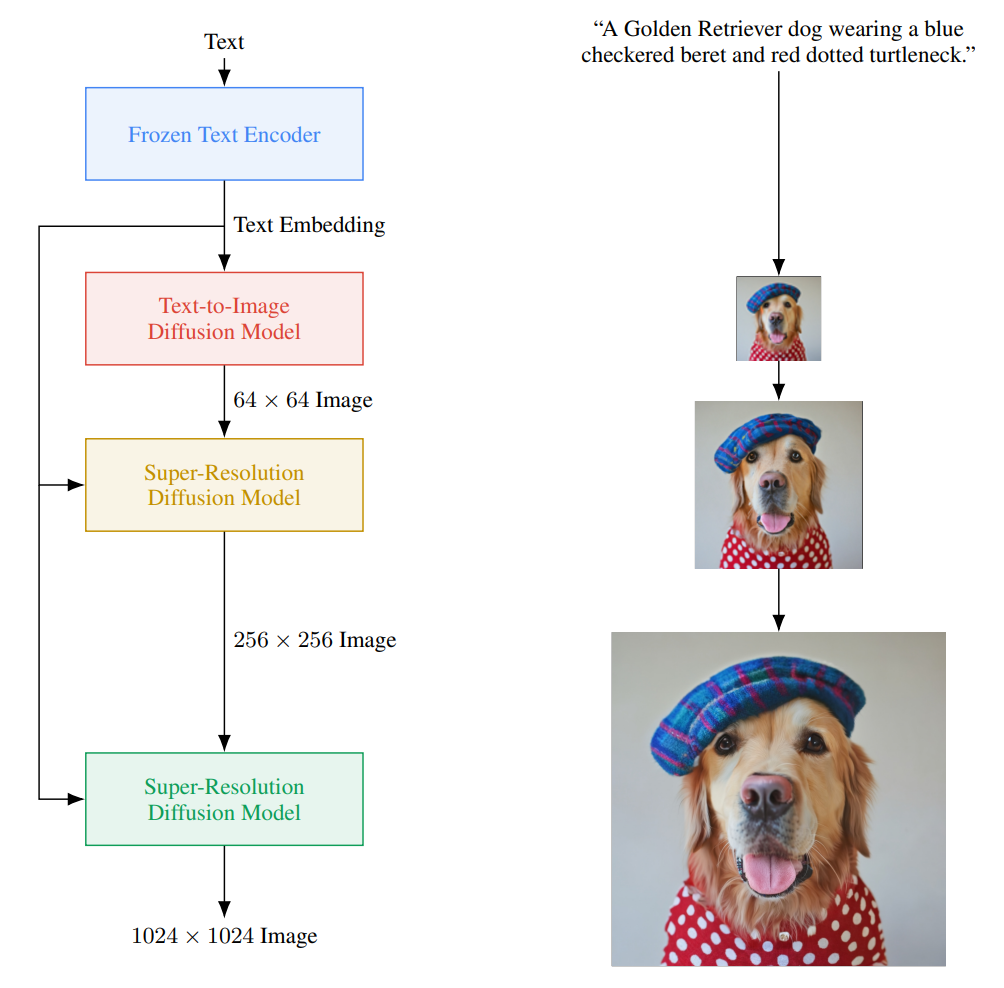
What’s more interesting is how it works utilizing a diffusion model, something I’ve never addressed on the channel. However, before we can use this diffusion model, we must first comprehend the text input. This is also the fundamental distinction between Dall-e and the others. To grasp the material as well as an AI system can, they employed a large text model akin to GPT-3. Rather than training a text model alongside the image generation model, they simply utilize a large pre-trained model that is frozen so that it does not change throughout the image generation model’s training. According to their research, this resulted in significantly higher outcomes, and the model appeared to have a better understanding of language.
So this text module is how the model understands text, and this knowledge is represented in encodings, which are what the model has been taught to do on massive datasets to convert text inputs into a space of information that it can utilize and comprehend. Now we must utilize this modified text data to create the picture, which they did use a diffusion model, as I previously said.
But, first and foremost, what is a diffusion model?
Diffusion models are generative models that learn how to reverse Gaussian noise repeatedly to transform random Gaussian noise into pictures. They’re effective models for super-resolution or other image-to-image translations, and they employ a modified U-Net architecture in this situation.

Essentially, the model has trained to denoise a picture from pure noise, which they orient using text encodings and a technique called Classifier-free guiding, which they claim is critical for the quality of the findings and is detailed in detail in their work. With the link in the references below, I’ll let you read it for further details on this strategy.
So now we have a model that can take random Gaussian noise and our text encoding and denoise it using the text encodings as guidance to get our image. But, as you can see in the diagram above, it’s not as straightforward as it appears. The image we just created is rather modest since a larger image would need a lot more computation and a much larger model, both of which are impractical. Instead, we create a photorealistic image using the diffusion model we just outlined, then incrementally increase the image’s quality using various diffusion models. Again, we want noise rather than a picture, so we contaminate this low-resolution image with some Gaussian noise and train our second diffusion model to enhance it.
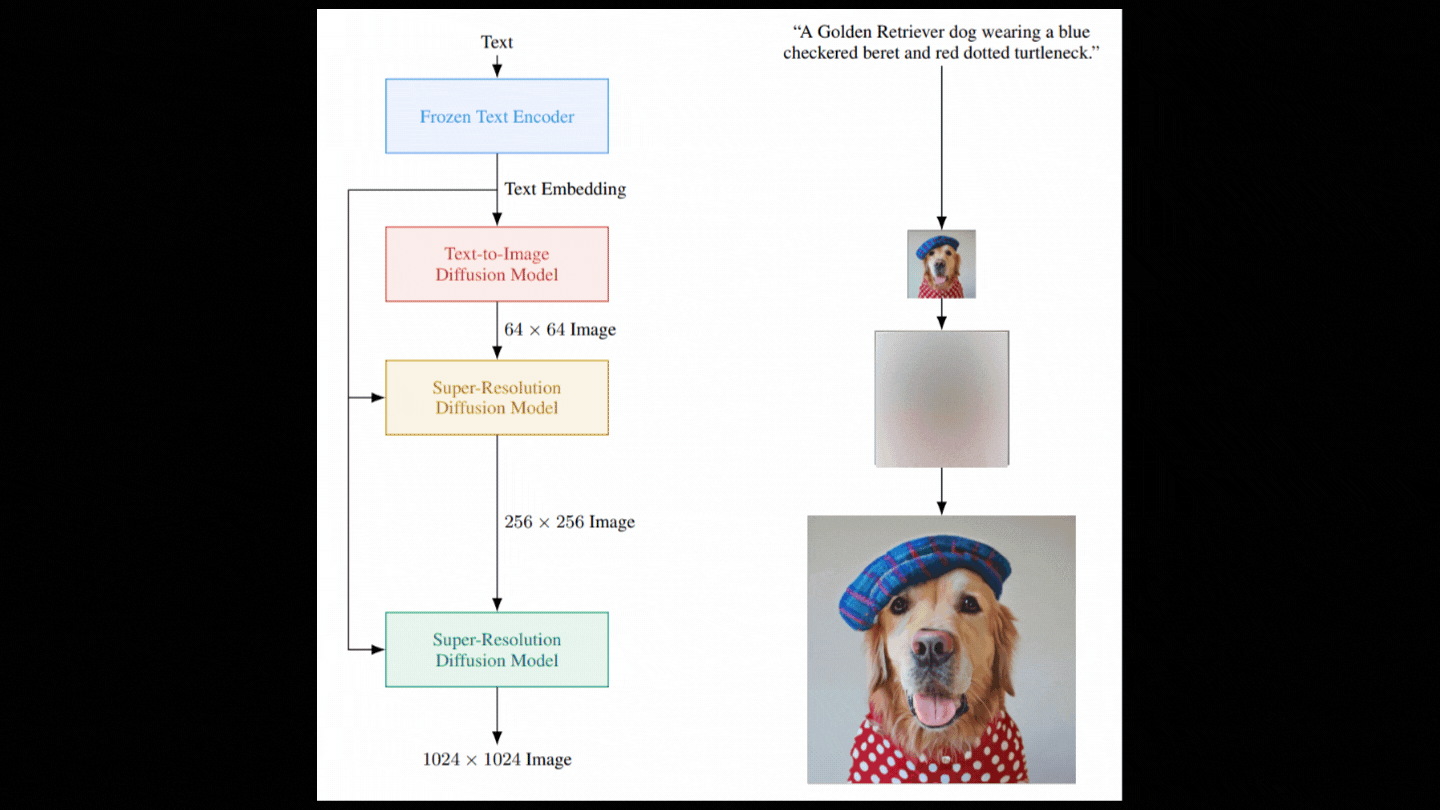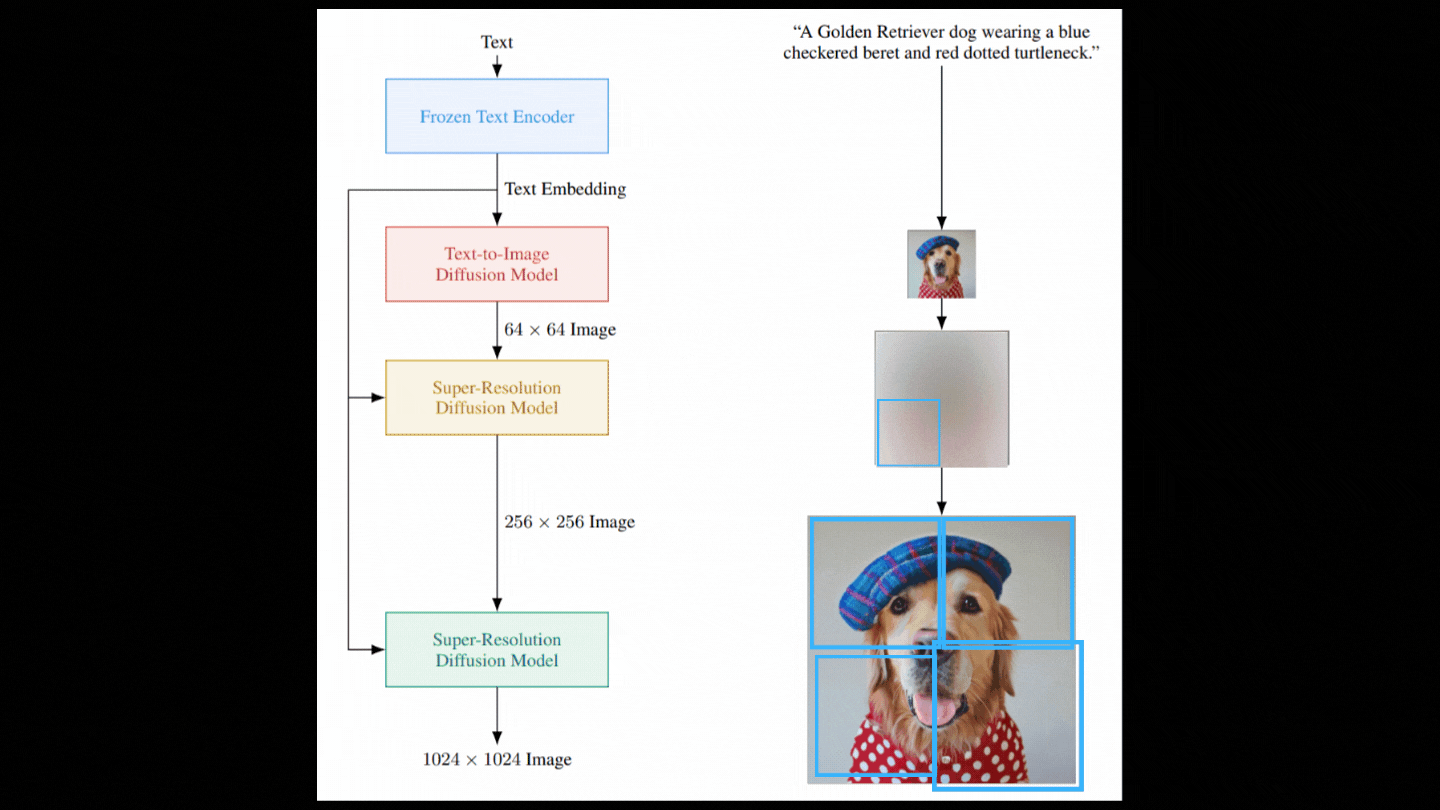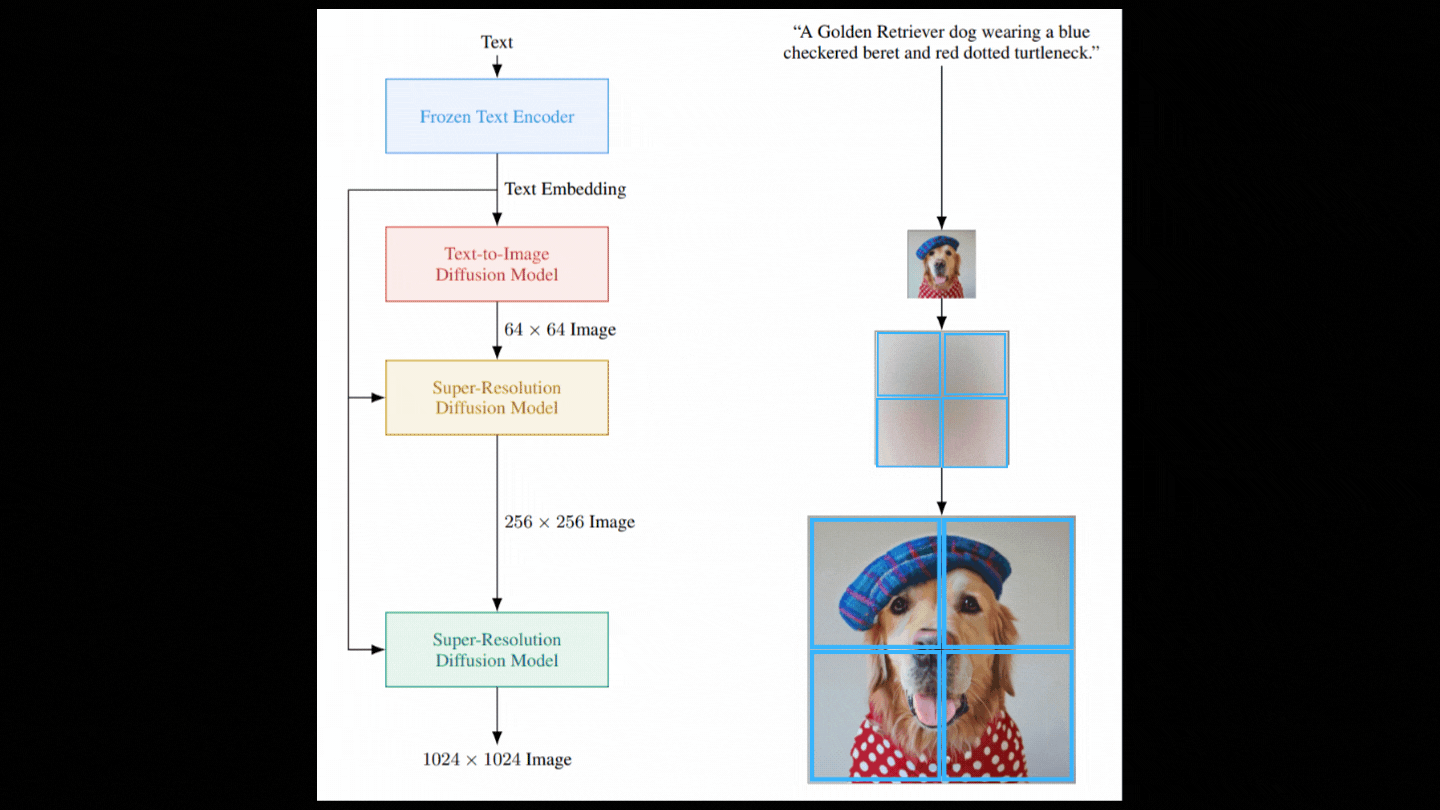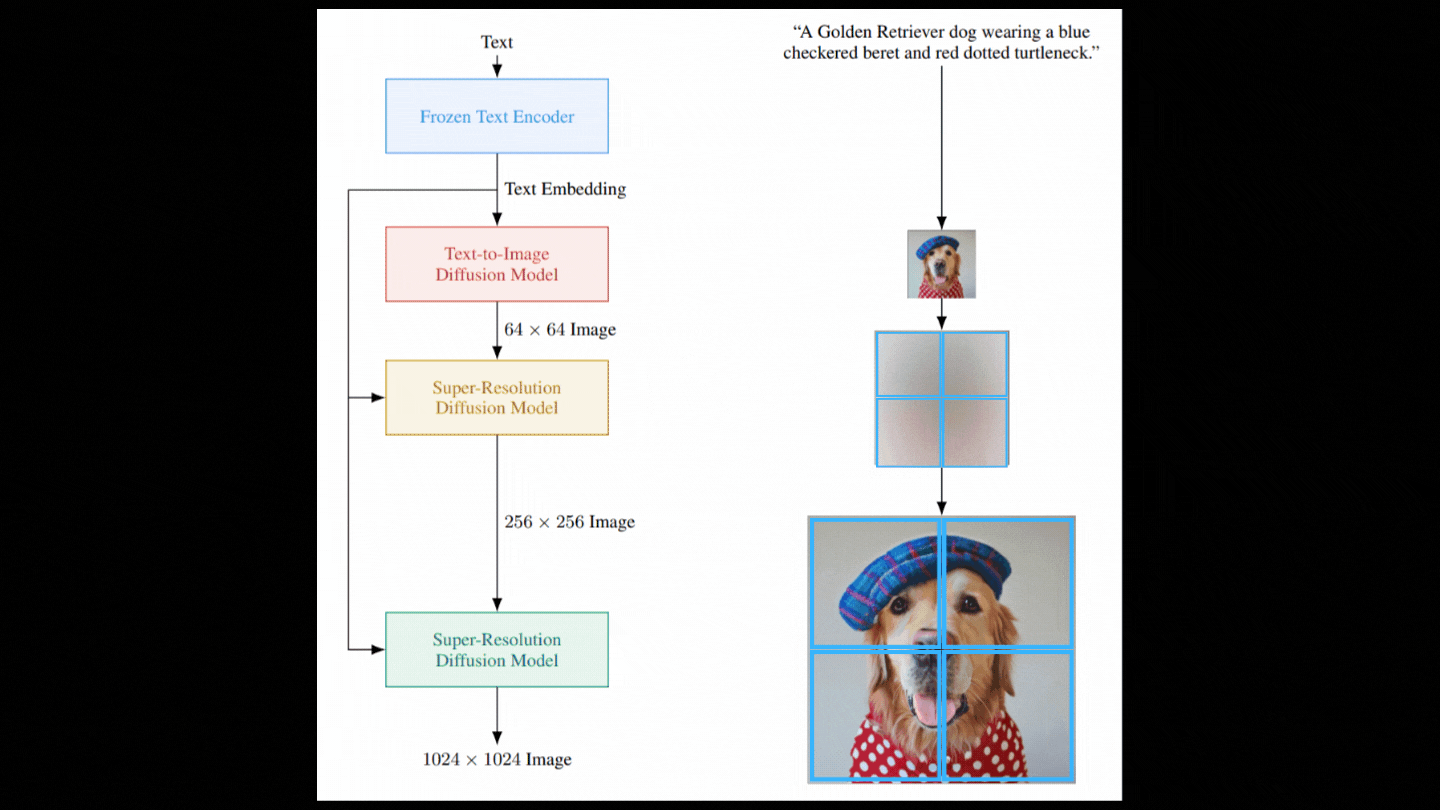
Then, with another model, we repeat these two stages, but this time using only portions of the picture to achieve the same upscaling ratio while remaining computationally feasible.
And there you have it! We get our photorealistic high-resolution image in the end!

Of course, this was only a quick rundown of this fascinating new model and its impressive findings. I strongly encourage you to read their excellent work for a better grasp of their methodology and a thorough examination of their findings.
Do you believe the results are equivalent to those of Dell-e 2? Is it for the better or for the worse? I believe that is now dall-major e’s competition. Please let me know what you think of this latest Google Brain release as well as the explanation.
Googles Imagen Model Better than DALLE-2? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

