


Google Just Published a Decoder-Only Model for Time-Series Forecasting With Zero-Shot Learning!!
Last Updated on February 20, 2024 by Editorial Team
Author(s): Saleha Shaikh
Originally published on Towards AI.
Time series forecasting drives most of the business today, and at the moment, it has been predicted using conventional ML/NN models, but Google just published a TimesFM model, which can make time series predictions with zero-shot learning!!
Time series prediction holds importance for businesses as it enables them to make decisions by utilizing past information and future projections. By analyzing data, companies can enhance their planning, optimize resource allocation, and mitigate issues.
In the finance sector, it helps in making investment decisions and avoiding challenges. Supply chain management benefits from predictions in determining inventory levels to minimize costs. In terms of marketing and sales, it assists in identifying the timing for promotions to attract customers and maximize profits. Ultimately time series prediction empowers businesses to make choices. Maintain competitiveness in an ever-evolving world.
Time Series Prediction
Time series prediction is very important for businesses as it enables them to make decisions by leveraging historical data and future projections. By analyzing trends, companies can enhance their planning, optimize resource allocation, and mitigate challenges.
In the finance sector, it empowers investors to make choices and steer clear of pitfalls. In supply chain management it helps in maintaining inventory levels to minimize costs. In marketing and sales, it assists in determining the timing for promotions to attract customers and boost revenue. Overall, time series prediction serves as a tool for businesses to enhance decision-making capabilities and remain competitive in an evolving world.
Conventional way of time series prediction
At present, for time series prediction, there are different approaches that are used in industry and academic research. The method chosen usually depends on the characteristics of the data and the specific prediction task at hand. In today's market, there are cutting-edge models that are widely used. Let’s revise some state-of-the-art models:
1. ARIMA (AutoRegressive Integrated Moving Average)
ARIMA is a classical statistical model. It combines autoregressive (AR) and moving average (MA). It yields good performance for time series data with a strong seasonality or trend.
2. LSTM (Long Short-Term Memory) Networks
LSTM is a type of recurrent neural network (RNN). LSTM is a deep learning model designed to capture long-term dependencies in sequential data.
3. Prophet
FBProphet was developed by Facebook. Prophet is a forecasting tool designed for time series data that exhibits patterns on different time scales. It handles missing data and outliers well.
4. XGBoost (Extreme Gradient Boosting)
XGBoost is an ensemble learning algorithm. It used the predictions from multiple weak models and combined the results to generate the final prediction. It is very good in finding complex relationships in the time series data.
It depends on which models to use based on the type of data. However, it is worth noticing that while using these models, a considerable amount of time is spent on finalizing these models. To solve this problem and to make use of recent advancements in LLMs (generative AI), Google has launched a new model, “TimesFM,” which is a decoder-only foundation model that can perform time series prediction with zero-shot learning!!!
Google TimesFM: A decoder-only foundation model for time-series forecasting
TimesFM is designed as a pre-trained forecasting model with just 200 million parameters, leveraging a large time-series corpus of 100 billion real-world time-points.
Unlike large language models (LLMs) that are typically trained in a decoder-only fashion for natural language processing, TimesFM adapts the decoder-only architecture to time-series forecasting. The model employs stacked transformer layers treating contiguous time-points as tokens. A unique feature is the use of a multilayer perceptron block with residual connections to convert time-series patches into tokens. During training, the model learns to forecast subsequent time-points, with the output patch length potentially exceeding the input patch length. This architecture allows for efficient forecasting with fewer generation steps during inference.
To enhance the model’s performance, a combination of synthetic and real-world data is used for pretraining. Synthetic data aids in grasping fundamental temporal patterns, while a curated corpus of 100 billion time-points, including data from Google Trends and Wikipedia Pageviews, provides real-world flavor, helping the model generalize across diverse domains.
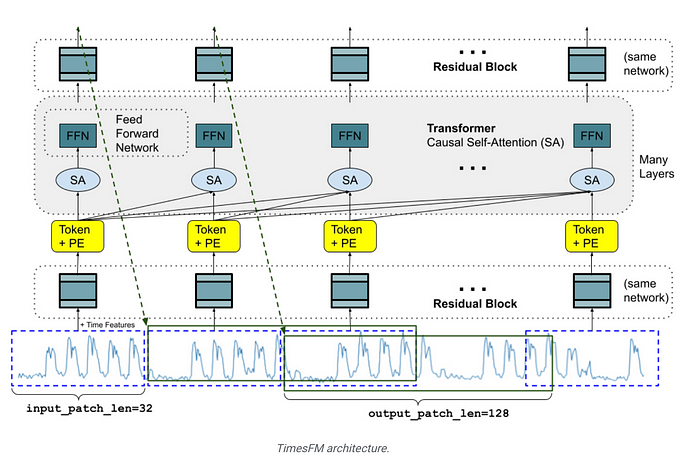
Model architecture
Transformers has shown promising results in adapting to a different context length. Model breaks down the time-series into several patches during training.A patch of a time series is a natural analog for a token in language models and has been shown to improve performance. Moreover, this improves inference speed as the number of tokens being fed into the transformer is reduced by a factor of the patch length.
TimesFM is a decoder-only model, meaning that for a given sequence of input patches, the model predicts the next patch as a function of all past patches. This model has a preprocessing unit in the form of input layers. It converts time series into input tokens. First, break the input into contiguous non-overlapping patches. Then each patch is processed by a Residual Block into a vector of a model dimension size. A binary padding mask is supplied along with input layer. The Residual Block is essentially a Multi-layer Perceptron (MLP) block with one hidden layer with a skip connection.
This model has a stack of transformer layers which are placed on top of each other. Each of these layers has the standard multi-head self-attention (SA) followed by a feedforward network (FFN). The model uses causal attention. That is, each output token can only attend to input tokens that come before it in the sequence (including the corresponding input token). This can be described by the equation:
o_j = StackedTransformer((t_1, m˙ 1), · · · ,(tj , m˙ j )), ∀j ∈ [N]
Performance
To measure the prediction of model, MSE (mean squared error) metric is used. It quantifies the closeness between actual and predicted values.
TimesFM is evaluated through zero-shot testing on various time-series benchmarks, showcasing superior performance compared to statistical methods like ARIMA and DL models like DeepAR and PatchTST. The model’s effectiveness is demonstrated on the Monash Forecasting Archive and popular benchmarks for long-horizon forecasting, outperforming both supervised and zero-shot approaches.
Conclusion
The research presents a promising decoder-only foundation model for time-series forecasting, exhibiting impressive zero-shot performance across different domains and granularities.
The proposed TimesFM architecture, despite its smaller size, proves to be a powerful tool for accurate and efficient forecasting in diverse applications. The work represents a collaboration across Google Research and Google Cloud, involving several individuals contributing to the development and evaluation of TimesFM.
In my thoughts, this is a promising approach to minimize development time and increase model performance for time series predictions.
Related reads and important information
Later this year, Google is planning to make this model available for external customers in 𝗚𝗼𝗼𝗴𝗹𝗲 𝗖𝗹𝗼𝘂𝗱 𝗩𝗲𝗿𝘁𝗲𝘅 𝗔𝗜.
- Research paper: A decoder-only foundation model for time-series forecasting
- Google AI’s blog about this paper
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

