



Give me 5 minutes, I’ll give you a DeepFake!
Last Updated on April 3, 2021 by Editorial Team
Author(s): Daksh Trehan
Computer Vision, Machine Learning
How to produce DeepFakes without writing any code.
Do you like performers and artists? Do you want to imitate them? Well, now you can!
Do you want to get viral on TikTok but are afraid of your dance moves? Well, AI got your back. All you need is your still image and a video of your favorite artist performing some moves. And, BOOM! you’re an internet sensation.
To imitate the above workflow we implement Image animation, which uses neural networks that helps us to wrap the source image on the motion of an object in the video sequence. In this article, we’ll see how easy image animation is, and how one can employ it without writing a single code!
How does it works?
The model presented in “First Order Motion Model for Image Animation” is a novel approach to replace the object in the driving video with the source image without any additional information about the object.
Before constructing our sequence, it is really important to understand what’s going on under the hood!
The model implements a neural network that helps in reconstructing the driving video where the object in the video is replaced by the object in the source image. During the test time, the model tries to predict how the object in the source image moves according to the frames depicted in the driving video. Using the above process, the model can track every minutiae detail in driving video ranging from head movement to talking.

The WorkFlow
The training is done on a large collection of videos. To reconstruct training videos model extracts frame pairs and tries to learn a latent representation of the motion in the video, using the extracted information it learns to encode motion as a mixture of motion-specific key point displacements and native affine transformations[1].
At test time, the model regenerates the video sequence by wrapping the object of the source image to each frame of driving video and hence performing image animation.
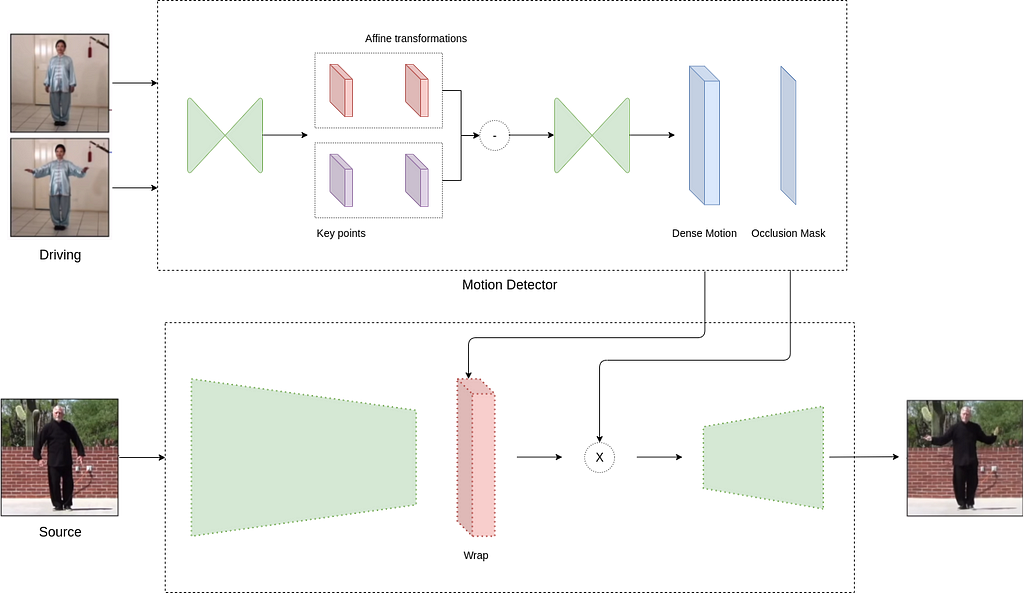
The framework is implemented using a motion estimation module and image generation module.
The goal of the motion estimator is to learn a latent representation of motion in the video. In simple words, it tries to track the movement in the sequence and encode them as motion-specific key point displacements and local affine transformations. The output includes a dense motion field and an occlusion mask. The mask defines relevant parts of the driving sequence object to be wrapped by the source image (e.g. front side of the face).

For instance, in the given gif, the back of the lady isn’t animated and that’s determined by a motion estimator.
Lastly, the output of the motion estimator is inputted to the image generator along with the source image and driving video. The image generator generates frames of driving video with wrapped source image object and the frames are joined together to create a sequence of video.
Creating DeepFakes
The source code of the paper can be easily found on Github. There are two methods to create a deepfake:
Old-School Technique:
- Download the repository in zip format.
2. Extract the files.
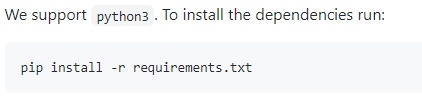
3. Use the terminal in the extracted folder and download all the required packages using the following command.
4. Download a pre-trained checkpoint.

Download any checkpoint based on your preference.
5. Copy source image, driver video, and pre-trained checkpoint to the extracted folder.
6. Open the terminal and use the following command:

Replace “config/dataset_name.yml”, “path/to/driving”, “path/to/source”, “path/to/checkpoint” to dataset name, driving sequence path, source image path and checkpoint path respectively.

Run the amended command and don’t forget to add “ — cpu” if you don’t have a GPU.
7. You’ll get your DeepFake video in the same extracted folder.
Google-Colab Technique:
- Visit https://colab.research.google.com/github/AwaleSajil/DeepFake_1/blob/master/first_order_model_demo(Youtube)_new_audioV5_a.ipynb
- Create a copy of this ipynb file.
- Configure your model.

4. Train your model on training data.


5. Add your source and driving video.

6. Enjoy your DeepFake.

References:
[1] First Order Motion Model for Image Animation (nips.cc)
[2] AliaksandrSiarohin/first-order-model: (github.com)
[3] First order model (aliaksandrsiarohin.github.io)
[4] How to Produce a DeepFake Video in 5 Minutes | by Dimitris Poulopoulos | Towards Data Science
[5] From Zero to Deepfake. Exploring deepfakes with DeepFaceLab | by Jarrod Overson | Medium
[6] (51) How To Create Deepfake Videos In 5 Minutes (Hindi) — YouTube
Feel free to connect:
Portfolio ~ https://www.dakshtrehan.com
LinkedIn ~ https://www.linkedin.com/in/dakshtrehan
Follow for further Machine Learning/ Deep Learning blogs.
Medium ~ https://medium.com/@dakshtrehan
Want to learn more?
Are You Ready to Worship AI Gods?
Detecting COVID-19 Using Deep Learning
The Inescapable AI Algorithm: TikTok
GPT-3 Explained to a 5-year old.
Tinder+AI: A perfect Matchmaking?
An insider’s guide to Cartoonization using Machine Learning
Reinforcing the Science Behind Reinforcement Learning
Decoding science behind Generative Adversarial Networks
Understanding LSTM’s and GRU’s
Recurrent Neural Network for Dummies
Convolution Neural Network for Dummies
Cheers
Give me 5 minutes, I’ll give you a DeepFake! was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")