



GAN: Is Diffusion All You Need?
Last Updated on June 21, 2022 by Editorial Team
Author(s): Kevin Berlemont, PhD
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Eight years ago, emerged one of the most promising approaches to generative modeling: Generative Adversarial Networks (GAN) [1]. Since then, a commensurate amount of progress has been made in the technics and results obtained. These models went from generating blurry faces to high-definition realistic pictures having different constraints.

If these improvements are impressive, such models are still not ready for wide-public utilization. Indeed, for such models to be successful, they should meet the generative learning trilemma [4]:
- They need to generate high-quality sampling rapidly, for example, GAN is applied to image synthesis.
- They need good mode coverage and sample diversity as it reduces the negative social negative impacts of such models.
- They need a fast and inexpensive sampling for the applications of real-time image editing or real-time synthesis for example.
I will first give an overview of what a GAN consists of with the advantage and inconveniences of such models. In the second part, I will explain a new trend in deep generative models: diffusion models. And finally, I will highlight very recent research results that propose a new approach to mixing GAN with diffusion models.
What is a GAN?
The goal of GAN is to generate new unseen data from a specific dataset. It does so by trying to learn a model of the true, unknown underlying data distribution from the samples. In another word, these networks are implicit models that try to learn a specific statistical distribution [6].
What was innovative about GAN was the way they learn to achieve this goal. Indeed, they generate data by learning an implicit model through a two-player game. The structure is the following:
- A Discriminator that learns to distinguish between real and generated data
- A Generator that learns to generate data fools the discriminator.
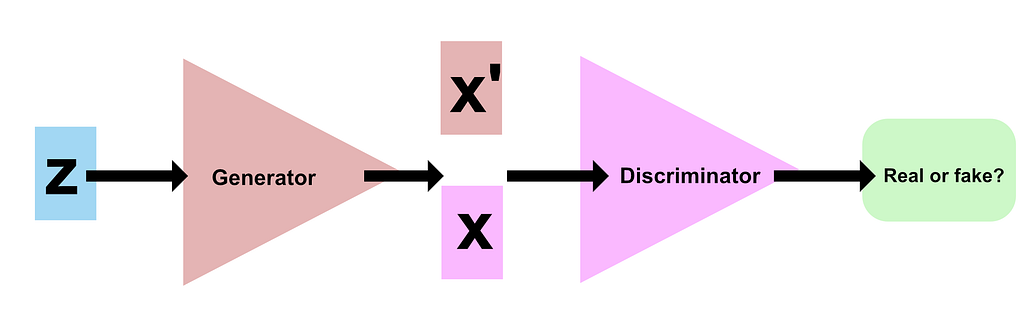
In other words, the generator has to design a high-resolution image to be able to fool the discriminator as the discriminator acts like a teacher network. One big difference with autoencoder models is that these generators are not trained using any distribution as output.
The loss function of the model can be decomposed in two terms:
- a part that quantifies if the discriminator correctly predicts real data is real
- a part that correctly predicts generated data is generated
This loss function is then minimized on the best possible discriminator:

Thus, generative models can be seen as distance minimization models and, if the discriminator is optimal, as divergence minimization between the true and generated distribution. In practice, multiple divergences can be used and give rise to different training for GANs.
However, while the loss function of GANs can be easily controlled it is hard to follow the learning dynamics as it consists of a trade-off between the generator and the discriminator. In addition, there are no guarantees of convergence of learning. Thus, it is challenging to train a GAN model as it is common to encounter issues such as vanishing gradient and mode collapsing (when there is no diversity in the generated samples).
Diffusion Models
Diffusion models have been designed with the goal of solving the issue with the training convergence of GANs. The idea behind these models is that a diffusion process equates to a loss of information due to gradual intervention of noise (a gaussian noise is added at every timestep of the diffusion process).
The goal of such a model is to learn the impact of noise on the information available in the sample, or in other words how much the diffusion process reduces the information available. If a model can learn this, then it should be able to reverse the loss of information that happened and retrieve the original sample. A denoising diffusion model does exactly this. It consists of a two steps process: a forward and a reverse diffusion process. In the forward diffusion process, Gaussian noise (i.e. diffusion process) is introduced successively until the data is all noise [7]. The reverse diffusion process then trains a neural network to learn the conditional distribution probabilities to reverse the noise.
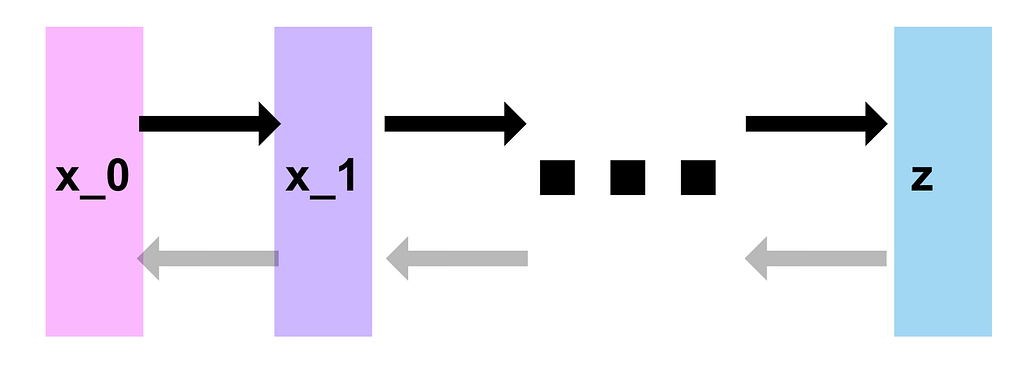
These types of networks have been successful in solving the generative process, as can be seen in the following figure (model from [3]):

However, in order to generate the sample, the reverse diffusion chain has to be traversed a multitude number of times. This is very computationally expensive making these models inefficient to generate samples. Despite their ability to generate high-quality realistic images, their real-world adoption is thus limited.
Diffusion-GAN
Various methods have been suggested to reduce the generative cost of diffusion-based models. One of the most intuitive ways to reduce this cost is to reduce the number of denoising steps of the reverse process of the diffusion models [4]. Generative diffusion models typically assume that the denoising distribution can be modeled by a Gaussian distribution. The issue is that this assumption holds only for small denoising steps, which lead to a huge number of denoising steps in the generative process and thus is not practical to use.
The most recent approach combines deep-generative models (GAN) and diffusion models in the following way. Instead of minimizing the divergence between real and diffused data at the end of the process, it minimizes the divergence between the diffused real data distribution and the diffused generator distribution over several timesteps t. In other words, during training, the generator is updated by backpropagating the gradient first through the forward diffusion chain and then through the discriminator (Figure below). Moreover, instead of injecting a naïve instance noise to corrupt the data sent to the discriminator, Diffusion-GAN injects a diffusion-based Gaussian mixture distribution [5], allowing the denoising process to approximate several steps at a time. This specific training process leads to the fact that the generator maps the noise to a generated sample in a single step, meaning that Diffusion-GAN can generate samples almost as quickly as classical GAN. The samples are generated from noise using the denoising diffusion GAN.
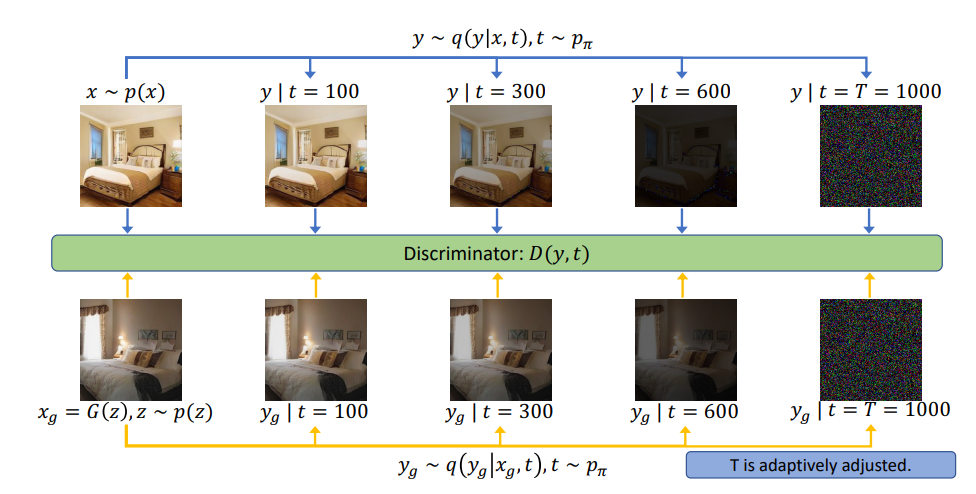
This technic allows the GAN “to learn an accelerated reverse denoising process by representing the denoising distributions through time as multimodal distributions” [8]. In adaption to speeding up the generation process, by breaking up the process into several conditional denoising steps, the discriminator is less likely to overfit as the diffusion process will have smoothened the data distribution. This type of model exhibits better training stability as well as sampling diversity. This variation of diffusion models seems very promising in terms of fast deep generative learning and could find practical use not only in picture and video processing but in another field such as drug discovery.
References
[1] Goodfellow, Ian, et al. “Generative adversarial nets.” Advances in neural information processing systems 27 (2014).
[2] Shoshan, Alon, et al. “Gan-control: Explicitly controllable gans.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021.
[3] Rombach, Robin, et al. “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[4] Xiao, Zhisheng, Karsten Kreis, and Arash Vahdat. “Tackling the generative learning trilemma with denoising diffusion gans.” arXiv preprint arXiv:2112.07804 (2021).
[5] Wang, Zhendong, et al. “Diffusion-GAN: Training GANs with Diffusion.” arXiv preprint arXiv:2206.02262 (2022).
[6] DeepMind x UCL | Deep Learning Lectures | 9/12 | Generative Adversarial Networks https://youtu.be/wFsI2WqUfdA
[8] Improving Diffusion Models as an Alternative To GANs, Part 2 | NVIDIA Technical Blog
GAN: Is Diffusion All You Need? was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

