


")
Forecast the Future in a Timeseries Data With Deep Java Library (DJL)
Last Updated on July 17, 2023 by Editorial Team
Author(s): Kexin Feng
Originally published on Towards AI.
A demonstration of the M5forecasting dataset
Authors: Junyuan Zhang, Kexin Feng
Time-series data are everywhere in the real world, e.g., the price change of assets in a market, the sales of commodities, the number of air passengers, and so on. Mining the pattern of these time-series data has many useful applications. For example, by forecasting the future sales of flight tickets, the price can be adjusted accordingly. Forecasting the sales of a grocery item can help decide inventory management. It also helps build an automatic monitoring system to detect anomalies away from the regular historical pattern.
In the era of deep learning, many powerful models have been invented to for time-series data mining with great performance. In this blog post, we will demonstrate with DeepAR model and show how it is applied to the unit sales data of Walmart retail goods and how to make forecasts with this model in a Java application.
This DeepAR model is easily accessible in the time-series package in DeepJavaLibrary (DJL). This is a deep-learning framework designed for Java developers. It is compatible with the existing popular deep learning engines, like PyTorch, MXNet, and TensorFlow, and enables users to easily train and deploy deep learning models in their Java application. The package contains the following two major features.
- It integrates DJL with gluonTS, a powerful time-series python package. With this feature, the pretrained models in gluonTS, either with MXNet or PyTorch, can both be directly loaded into DJL for inference and deployment in a Java environment. [Source code]
- It contains training features so that users can directly build and modify time-series deep learning models in DJL within a Java environment. [Source code].
In this blog post, we will focus on the inference feature. It is structured as follows.
- A simple demonstration with air passenger data
- M5 Forecasting dataset
- DeepAR model
- Inference with pretrained DeepAR model.
- Summary
1. A simple demonstration with air passenger data
We start with a simple demonstration of the DeepAR model applied to the [air passenger data], to get a sense of its performance. The dataset consists of a single time series containing monthly international passengers between the years 1949 and 1960, a total of 144 values (12 years times 12 months). The model is pretrained in gluonTS and then directly loaded into DJL. The source code is here.
The result is shown in the graph below. It has the same performance as shown on gluonTS website. We can see the historical pattern is effectively learned as manifested in its forecast. Next, you will see how to easily apply this model to more realistic data in the M5 forecasting task.

2. M5 Forecasting dataset
This demonstration is based on the Kaggle M5 Forecasting competition. The dataset contains 42,840 hierarchical time-series data of the unit sales of Walmart retail goods. “Hierarchical” here means that we can aggregate the data from different perspectives, including item level, department level, product category level, and state level. Also, for each item, we can access information about its price, promotions, and holidays. As well as sales data from Jan 2011 all the way to June 2016.
Note. In the original M5 forecasting data, the time series data is very sparse, containing many zero values. These zero can be seen as inactive data. So we aggregate the sales by week to train and predict at a coarser granularity, which focuses on only the active data. To also predict the inactive data, another model may be needed to be combined. The data aggregation is done with a python script m5_data_coarse_grain.py. This script will create weekly_xxx.csv files representing weekly data in the dataset directory you specify.
3. DeepAR model
DeepAR forecasting algorithm is a supervised learning algorithm for forecasting scalar (one-dimensional) time series using recurrent neural networks (RNN). Unlike traditional time series forecasting models, DeepAR estimates the future probability distribution instead of a specific number. In retail businesses, probabilistic demand forecasting is critical to delivering the right inventory at the right time and in the right place. Therefore, we choose the sales data set in the real scene as an example to describe how to use the time-series package for forecasting.
Also, take a look at the python example m5_gluonts_template for the demonstration of the DeepAR model. Our convention of the parameter names is the same as theirs.
4. Inference feature: inference with pretrained DeepAR model
Setup
To get started with the DJL time series package, add the following code snippet defining the necessary dependencies to your build.gradle file.
plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
implementation "org.apache.logging.log4j:log4j-slf4j-impl:2.17.1"
implementation platform("ai.djl:bom:0.21.0")
implementation "ai.djl:api"
implementation "ai.djl.timeseries"
runtimeOnly "ai.djl.mxnet:mxnet-engine"
runtimeOnly "ai.djl.mxnet:mxnet-model-zoo"
}
Define your dataset
In order to realize the preprocessing of time series data, we define the TimeSeriesData as the input of the Translator, which is used to store the feature fields and perform corresponding transformations.
So for your own dataset, you need to customize the way you get the data and put it into TimeSeriesData as the input to the translator. In this demo, we use M5Datasetwhich is located in M5ForecastingDeepAR.java.
The dataset path is set in the following code.
Repository repository = Repository.newInstance("local_dataset", Paths.get("YOUR_PATH/m5-forecasting-accuracy"));
NDManager manager = NDManager.newBaseManager();
M5Dataset dataset = M5Dataset.builder().setManager(manager).optRepository(repository).build();
Configure your translator and load the local model
The inference workflow consists of input pre-processing, model forward, and output post-processing. DJL encapsulates input and output processing into the translator and uses Predictor to do the model forward.
DeepARTranslator provides support for data preprocessing and postprocessing for probabilistic prediction models. Similar to GluonTS, this translator is specifically designed for the timeseriesData, which fetches the data according to different parameters, like frequency, which are configured as shown below. For any other GluonTS model, you can quickly develop your own translator using the classes in transform modules (etc. TransformerTranslator).
Here, the Criteria API is used as search criteria to look for a ZooModel. In this application, you can customize your local pretrained model path: /YOUR PATH/deepar.zip.
String modelUrl = "YOUR_PATH/deepar.zip";
int predictionLength = 4;
Criteria<TimeSeriesData, Forecast> criteria =
Criteria.builder()
.setTypes(TimeSeriesData.class, Forecast.class)
.optModelUrls(modelUrl)
.optEngine("MXNet") // or PyTorch
.optTranslatorFactory(new DeferredTranslatorFactory())
.optArgument("prediction_length", predictionLength)
.optArgument("freq", "W")
.optArgument("use_feat_dynamic_real", "false")
.optArgument("use_feat_static_cat", "false")
.optArgument("use_feat_static_real", "false")
.optProgress(new ProgressBar())
.build();
Note: Here the arguments predictionLength and freq decide the structure of the model. So for a specific model, these two arguments cannot be changed, such that the translator is compatible with the models in terms of the tensor shapes.
Also note that, for a model exported from MXNet, the tensor shape begin_state may be problematic, as indicated in this issue. As described there, you need to change every begin_state’s shape to (-1, 40). Otherwise, the model would not allow batch data processing.
Prediction
Now, you are ready to use the model bundled with the translator created above to run inference.
Since we need to generate features based on dates and make predictions with reference to the context, for each TimeSeriesData you must set the values of its StartTime and TARGET fields.
try (ZooModel<TimeSeriesData, Forecast> model = criteria.loadModel();
Predictor<TimeSeriesData, Forecast> predictor = model.newPredictor()) {
data = dataset.next();
NDArray array = data.singletonOrThrow();
TimeSeriesData input = new TimeSeriesData(10);
input.setStartTime(startTime); // start time of prediction
input.setField(FieldName.TARGET, array); // target value through whole context length
Forecast forecast = predictor.predict(input);
// Save data for plotting
NDArray target = input.get(FieldName.TARGET);
target.setName("target");
saveNDArray(target);
// Save data for plotting.
NDArray samples = ((SampleForecast) forecast).getSortedSamples();
samples.setName("samples");
saveNDArray(samples);
}
Results
The Forecast are objects that contain all the sample paths in the form of NDArray with dimension (numSamples, predictionLength), the start date of the forecast. You can access all this information by simply invoking the corresponding function.
You can summarize the sample paths by computing, including the mean and quantile, for each step in the prediction window.
logger.info("Mean of the prediction windows:\n" + forecast.mean().toDebugString());
logger.info("0.5-quantile(Median) of the prediction windows:\n" + forecast.quantile("0.5").toDebugString());
> [INFO ] - Mean of the prediction windows:
> ND: (4) cpu() float32
> [5.97, 6.1 , 5.9 , 6.11]
>
> [INFO ] - 0.5-quantile(Median) of the prediction windows:
> ND: (4) cpu() float32
> [6., 5., 5., 6.]
We visualize the forecast result with mean, prediction intervals, etc. The plot function is in a python script plot.py.
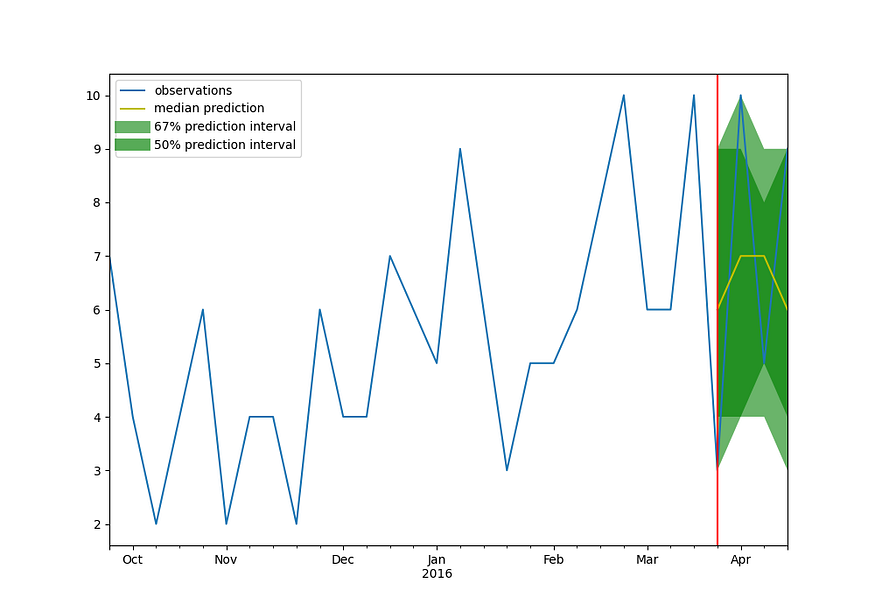
Metrics
We use the following metrics to evaluate the performance of the DeepAR model in the M5 Forecasting competition.
> [INFO ] - metric: Coverage[0.99]: 0.92
> [INFO ] - metric: Coverage[0.67]: 0.51
> [INFO ] - metric: abs_target_sum: 1224665.00
> [INFO ] - metric: abs_target_mean: 10.04
> [INFO ] - metric: NRMSE: 0.84
> [INFO ] - metric: RMSE: 8.40
> [INFO ] - metric: RMSSE: 1.00
> [INFO ] - metric: abs_error: 14.47
> [INFO ] - metric: QuantileLoss[0.67]: 18.23
> [INFO ] - metric: QuantileLoss[0.99]: 103.07
> [INFO ] - metric: QuantileLoss[0.50]: 9.49
> [INFO ] - metric: QuantileLoss[0.95]: 66.69
> [INFO ] - metric: Coverage[0.95]: 0.87
> [INFO ] - metric: Coverage[0.50]: 0.33
> [INFO ] - metric: MSE: 70.64
Here, we focus on the metric Root Mean Squared Scaled Error, ie. RMSSE. The detailed formula is here. It is different from the Root-mean-square error RMSE in that RMSSE is based on the variation between two contiguous data points. So this metric is scale-invariant and suitable for time-series data.
As you can see, in the result metric above, the model has RMSSE = 1.00. This means that, on average, the error between the prediction and the actual data is around 1.00 multiple of the average variation of the time series. This is also seen in the resulting graph above: the predicted intervals are about the same as the data varies over time. If the predicted interval were smaller, then the prediction would be more accurate, like the plot with the air passenger data in the second next section. In the Kaggle contest learderboard, the best model can reach RSSSM = 0.5.
5. Summary
In this blog post, we have shown the DJL time-series package with M5 Forecasting data. We focus on the inference feature, but the training feature is also available here, where you can build your own time-series model in DJL. With these features in DJL, users can now start mining the time-series data conveniently in Java.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

