



Exploring LLM Strategies: A Journey through Prompt Engineering, Functional Calling, RAG, and Fine-Tuning
Last Updated on May 7, 2024 by Editorial Team
Author(s): Selina Li
Originally published on Towards AI.
What they are, how they are related and how to select one for your use case
· Introduction
· Recap on how LLM works
· What are the strategies, and how are they related to each other?
∘ 1. Pure Prompt
∘ 2. Agent + Function Calling
∘ 3. RAG (Retrieval Augmented Generation)
∘ 4. Fine Tuning
· When to use which strategy?
· Enjoyed This Story?
Introduction
In the ever-evolving landscape of Generative AI, certain buzzwords have become commonplace: “Prompt Engineering,” “Functional Calling,” “RAG,” and “Fine-Tuning.” Perhaps you have encountered them in discussions, blog posts, or conference presentations. Like you, I’ve heard about these concepts repeatedly over the past year, but until recently, they remained as separate dots in my mind.
Recently these separate dots got connected after I attended a virtual training provided by Prof. Zhigang Sun, the creator of the open-source project ChatAll and founder of AGIClass.ai. I cannot wait to share this newfound clarity with you.
This article will describe what each LLM strategy does and how they are related to each other, also simply covering how we can choose among them for our best use case.
Recap on how LLM works
Before we go further, let’s briefly recap on how LLM works to generate results.
In layman’s terms, it is like finishing a cloze test:
- Given a sequence of words, LLM refers to all words in the dictionary, and evaluates the likelihood of seeing each of them coming as the next
- The word with the highest likelihood will be chosen and filled into the space
- The above steps repeat until there is no more space to fill in
Going deeper, in order to work on these “cloze test”, LLMs have gone through a training process to read through all human knowledge and record the likelihood of seeing each token* as the next. (Note: 1 token represents one or several words)
The process in which LLMs generate results for the “cloze test” is inference.
Training and Inference are the two core processes that enable LLM to work as expected.
This explains why sometimes LLM confidently speaks wrong — the human knowledge that it was trained on might not include sufficient information about the topics that we want it to talk about.
Therefore, to enable LLM to function as desired, we will need to supply LLM with more context useful information about the topics.
All the strategies including Function Calling, RAG and Fine tuning are around this. They are different approaches to provide more context useful information to LLMs.
What are the strategies, and how are they related to each other?
1. Pure Prompt

The first strategy is pure prompting. By name it explains how this strategy works:
- You issue a query to the LLM
- The LLM provides a response
This is simply “chatting”. You chat with LLM like chatting with another human.
We use this strategy every day when we chat with LLM-powered ChatBots such as ChatGPT, Gemini, and Copilot.
2. Agent + Function Calling

The second strategy is Agent plus Function Calling.
This is how this strategy works:
- You issue a query to the LLM
- Instead of answering you in a straight way, the LLM will refer to a given toolkits, and select a tool from it to perform some tasks first
Why would the LLM do so? Could be because it needs some extra information, or it was educated to fulfil some pre-requisites before answering your questions.
The toolkits here are a list of pre-written functions or API calls
The LLM will decide on the tool that it wants to use, and return the name of the tool (i.e. function name)
- Upon receiving the tool name (function name), you use the tool (i.e. call the function) to perform the task as desired by the LLM, and get some useful information
- You pass the useful information back to the LLM, and the LLM uses it to generate a response to your original query
If this still sounds abstract, let’s take an example:
- You issue a query to the LLM as a travel agent e.g. “Plan me a trip for the incoming Christmas holiday in Bali island”
- The LLM decides that in order to plan a good trip for you, it requires your budget information first. It refers to a given toolkit that includes multiple tools including
get_budget(),get_destination_info(),get_weather()and so on, and decides it will use the tool namedget_budget() - Upon receiving the suggested tool name, you (as the application) call the function
get_budget(). Let's say it returns you a budget of AUD1000. - You pass the AUD1000 budget information to the LLM, and the LLM generates a list of travel plan for you based on your budget
Note: function calling is definitely not limited to a single function. In this example, the LLM may decide it also requires the weather information and the destination information, thus it may select the other tools get_destination_info() and get_weather() as well. What functions and how many functions will be called depending on different factors, including:
- What functions are given in the toolkit
- Context including system prompt, user prompt and historical user information
- etc.
As you might have noticed, this process involves LLM (which provides any possible answers) as well as functions/API calls (which comes with preset logics).
Different from the traditional approach to use hard-coded logics (e.g. if else) to decide when to call which function/API, this process utilises the power of LLM to dynamically decide when to call which, depending on the context.
And different from pure prompting, this process enables LLM to integrate with external systems through function/API calling.
3. RAG (Retrieval Augmented Generation)
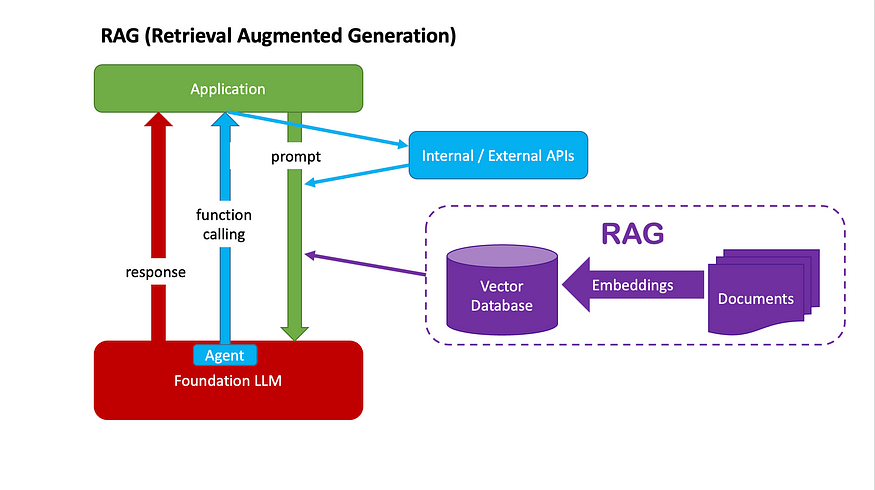
The third strategy is RAG.
On top of the toolkit of functions/APIs as mentioned in above Agent + Function Calling, we can also supply a knowledge base to the LLM. The knowledge base is generally implemented through a vector database.
To build the knowledge base:
- We collect documents that are related to certain topics that we want to enable LLMs to talk about in an accurate manner
- We break them into smaller chunks
- We then create embeddings (i.e. numeric representations) for each of the chunks, and store them in the Vector Database
Then this is how this strategy works:
- You issue a query to the LLM
- The application will retrieve information from the knowledge base which are most relevant to the user query. This is the process of “retrieval”
- The retrieved information will be part of the final prompt that gets passed to the LLM. This is the process of “augment” (augmenting of the prompt)
- LLM generates responses based on the final prompt. This is the process of “generation”
4. Fine Tuning

The forth strategy is Fine Tuning.
Just like when you write a function, you have two ways to pass a variable to it –
- first, pass in the variable from the argument so it can be picked up during run time;
- second, bake it in as a local variable within the function.
Similarly, the context knowledge that we pass in as run-time prompt in above RAG strategy, as an alternative can be baked it in during the model training. This is the case of fine tuning.
Imagine that a company specialised in pharmacy might have a huge knowledge base which are not being aware of publicly. In such a case, the company can choose a foundation LLM and fine tune it by embedding the knowledge base as part of the new model itself.
When to use which strategy?
Despite the “case by case” golden answer, we would like to provide some more clues here as shared by Prof. Zhigang Sun.
Below diagram is not a golden rule but can provide some guidance:

Although Fine-tuning looks like the ultimate solution, it is generally more costly with much more effort.
You might find RAG sufficient to resolve 70% to 80% of use cases given its core advantages:
- Easy to keep up-to-date, as we just need to keep the documents and vector database up-to-date
- Lower cost
Scenarios where fine-tuning might be considered:
- The stability of model output is of great significance
- With a large number of users, optimizing inference costs is of great significance
- The generation speed of LLMs is of great significance
- Private hosting is a must
Enjoyed This Story?
Selina Li (Selina Li, LinkedIn) is a Principal Data Engineer working at Officeworks in Melbourne Australia. Selina is passionate about AI/ML, data engineering and investment.
Jason Li (Tianyi Li, LinkedIn) is a Full-stack Developer working at Mindset Health in Melbourne Australia. Jason is passionate about AI, front-end development, and space-related technologies.
Selina and Jason would love to explore technologies to help people achieve their goals.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



