


Explaining Attention in Transformers [From The Encoder Point of View]
Last Updated on November 6, 2023 by Editorial Team
Author(s): Nieves Crasto
Originally published on Towards AI.
In this article, we will take a deep dive into the concept of attention in Transformer networks, particularly from the encoder’s perspective. We will cover the following topics:
- What is machine translation?
- Need for attention.
- How is attention computed using Recurrent Neural Networks (RNNs)?
- What is self-attention, and how is it computed using the Transformer’s encoder?
- Multi-headed attention in the Encoder.
Machine Translation
We will look at Neural machine translation (NMT) as a running example in this article. NMT aims to build and train a single, large neural network that reads a sentence and outputs a correct translation. This is achieved using sequence-to-sequence models, like Recurrent Neural Networks (RNNs), where you have a sequence as an input to the model and it produces another sequence as the output.

Figure 1 shows an example of French to English-translation. The model contains two parts: the encoder and the decoder. The encoder will process the sentence word by word (technically token by token as per Natural Language Processing (NLP) terminology). The encoder produces a context that is fed into the decoder. The decoder will then produce the output one word at a time.

To further illustrate in Figure 2, the encoder produces a hidden state at each time instance, and the last hidden state (hidden state #3) is fed as the decoder input.
Processing a sentence word-by-word can have detrimental effects, especially as the sentence gets long. The last hidden state of the sentence might not be able to encode all the necessary information, which can result in forgetting the beginning of the sentence. This a well-known issue that RNNs have faced. There have been various ways proposed to overcome this; Long Short Term Memory (LSTM) being one of them. However, each of these methods has its share of pros and cons. Attention was proposed as a way to address this problem (Bahdanau et al).
What is attention?

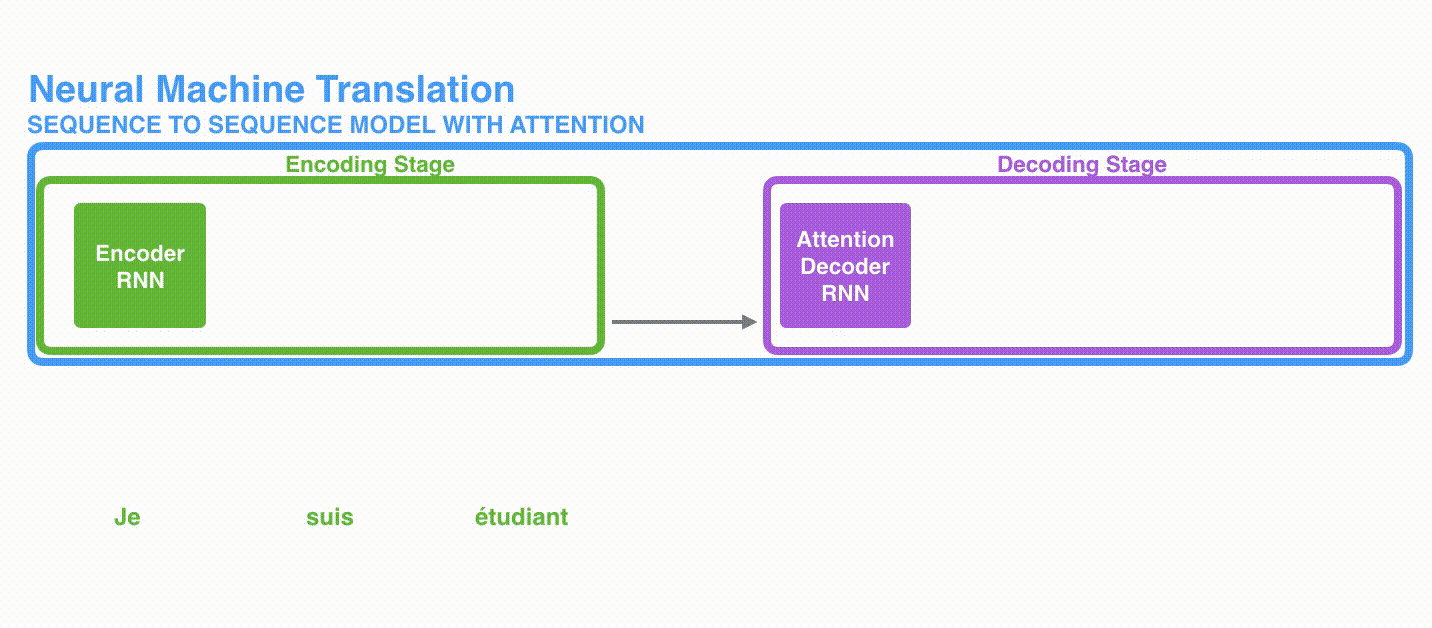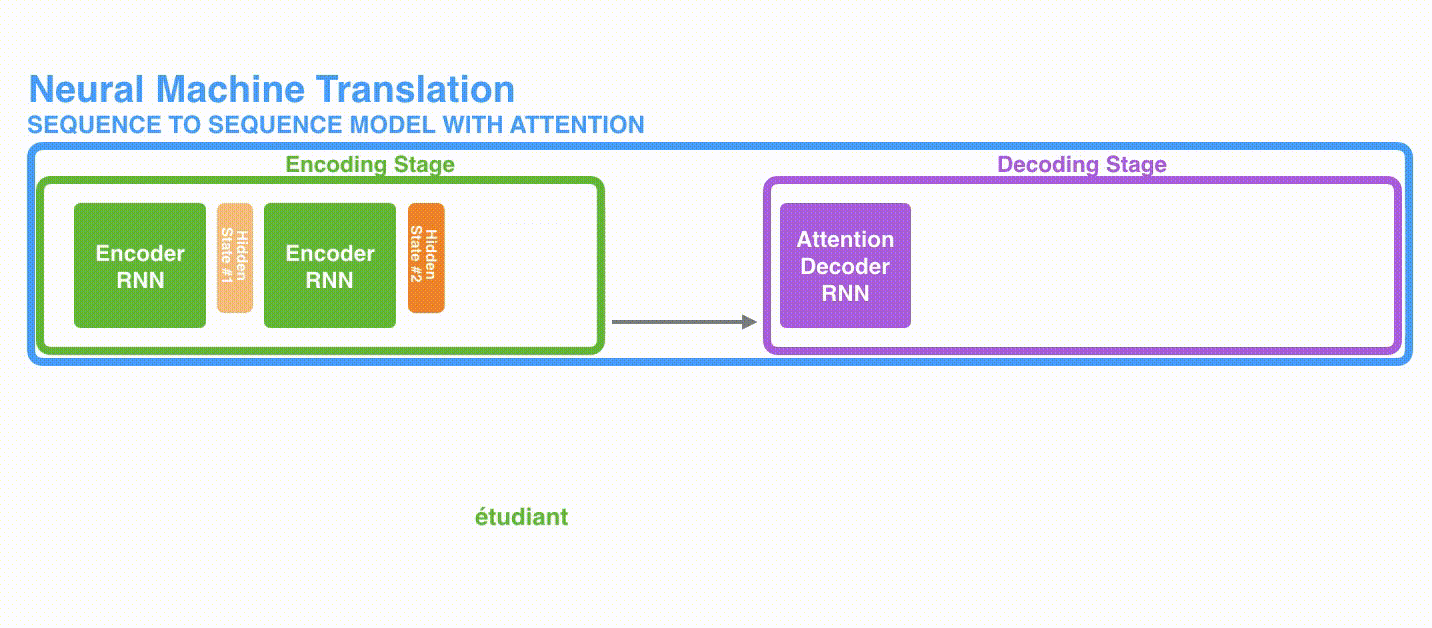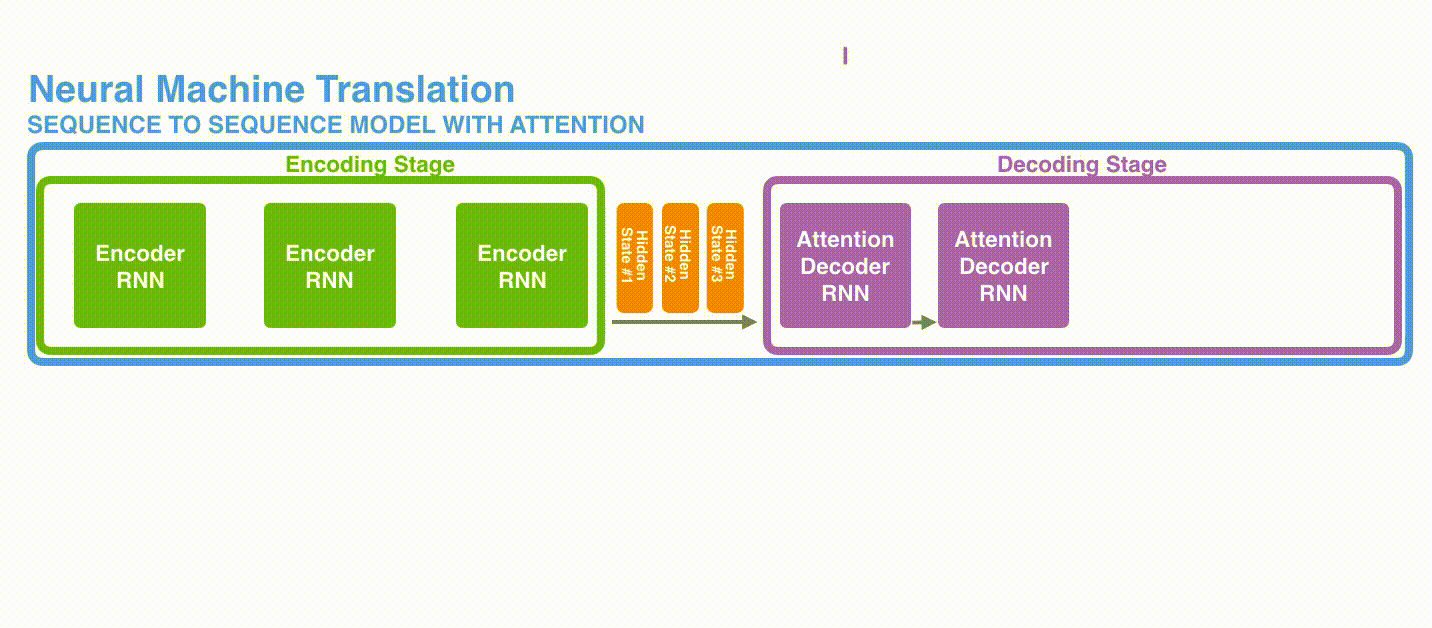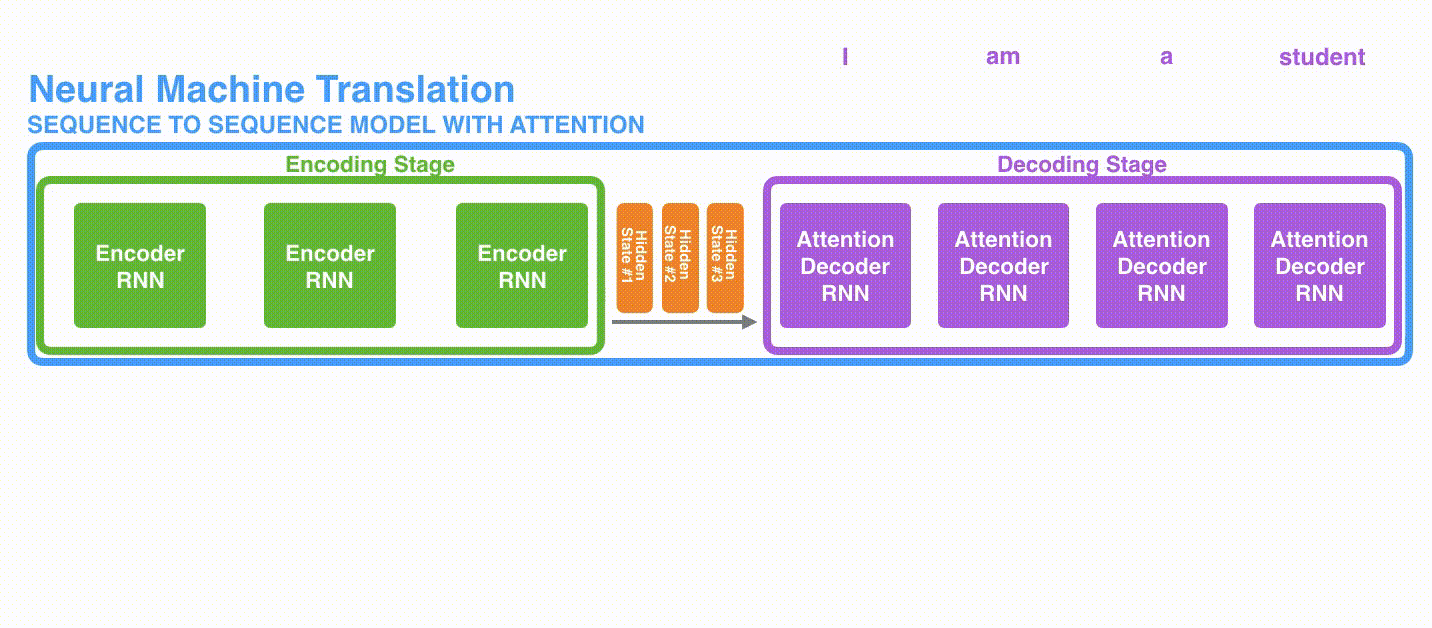
In Figure 3, let’s consider all three hidden states produced by the encoder. Instead of just relying on the last hidden state, the decoder now has access to all the hidden states produced by the encoder. The decoder generates output one word at a time, hence, we need a mechanism that informs the decoder which hidden state to prioritize to produce the output at each time step. For instance, to generate the first word “Je”, hidden state #1 will be most important, for second word “suis”, hidden state #2 is more important, and so on.
Basically, at each time step, we need a different weighting scheme for the hidden states. This will tell the decoder which part of the input sentence it needs to focus on, in order to produce the output. In short, attention can be formulated as a weighted sum of the hidden states.

The above sentence “Je suis etudiant” is pretty straightforward with a one-to-one mapping between the words for the input and output sentences. In the sentence below (Figure 4), we observe for the words “European Economic Area”, the mapping of the words from France to English is reversed. In such cases, attention proves important in order to learn the correct mapping of words from one language to another.

To summarize, the encoder processes the sentence word-by-word and stores the corresponding hidden states. These hidden states are then fed to the decoder where the attention mechanism is applied.
Note: The attention weights are changed per time-step.
Self-Attention
Attention is a weighing scheme to learn the mapping between input and output sequence, i.e. which part of the input is going to be important to produce the output at the current time step. Now, let’s look at the sentences below.


We need to know what does “it” refer to. Is it street or animal? This is crucial, especially in translating English into a gendered language, like French.
Self-attention is a means to encode the relationship between words in the input sentence. In the first sentence in the example above, we look at all the words in the sentence and encode “it” in such a way that gives more weight to either animal or street than the other words.
Now, let’s look at the Transformer Architecture to understand how self-attention is implemented.
Transformer Architecture
The first transformer was introduced in a paper in 2017.
As it was developed for machine translation, it has an encoder and a decoder architecture. The encoder and decoder are made up of stacks of encoders and decoders, respectively.

We are going to focus on the Multi-Head Attention block of the Encoder.
To begin with, we generate vectors for each word (token) in a sentence using the word2vec model. The model takes a word as input and produces a vector that represents the meaning of the word. The vectors generated by the word2vec model tend to put words that are similar in meaning to be closer in the vector space, i.e. the words “chair” and “table” would be closer together compared to, let’s say “chair” and “tiger”. These vectors are then fed into the attention module.
How is self-attention computed? (Query, Key, Value)
Previously, we calculated attention as a simple weighted summation of the hidden states in the RNN. Here, we are going to compute self-attention in a different way, using Query, Key, and Value.
This is based on the concept of databases, where you have a lookup table, consisting of a key and a corresponding value. When someone queries the database, you match the query to the key and get some value based on the match. Let’s consider a small database (see Table 1 below) with three keys: Apple, banana, chair, and a value associated with each key (10, 5, 2).

If we have query = apple, then we get the output 10. But if we have query = fruit, what do we do? If we look at the table, the key “fruit” doesn’t exist. We either throw an error or do something smarter. Can we relate fruit to the other keys in the data set? The word fruit is related in some way to apple and banana and not related to the chair. So let’s say, fruit is related (0.6) times to apple, (0.4) times to banana, and (0.0) times to chair. These are essentially your attention values. Therefore, if we now have query = fruit, we get the output as 0.6 * 10 + 0.4 * 5 + 0.0 * 2 = 8.
But how do we calculate the attention values? Let’s begin by representing our query with a 4D vector.

Similarly, we also represent the keys (apple, banana, chair) with a matrix using corresponding vector values.
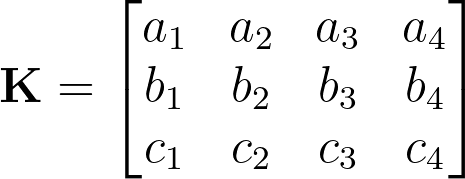
The attention scores can then be computed as
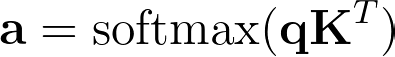
Now let’s go a bit deeper into how this is implemented in the encoder.
Let’s start with a simple sentence, “Thinking machines”. First, we generate fixed-length embeddings for each of these words;

For each word, we need to compute the query, key, and value vector, using the following equations.
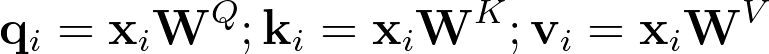

We can also represent the inputs as a matrix, in our case,

and the corresponding query, key, and value matrices as,


Now, we can compute the attention values as,


Multi-Head Attention
Now let’s go back to our sentence, “The animal didn’t cross the street because it was too tired”. Here we see the adjective “tired” is also related to the animal. In the figure below, we see two attention heads; the first (orange) relates the query “it” to “animal” while the second (green) relates the query “it” to “tired”. Thus together, the two heads form a better representation that links the words “it”, “animal” and “tired”.

Therefore, with two attention heads, we have

These produce 2 different scores;
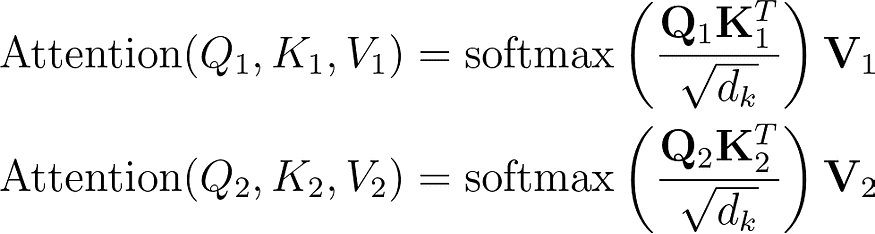
The final score is computed by concatenating the scores from both the attention heads and projecting it back to the D dimensions of the original input.

By default, the transformer model uses 8 attention heads.
With this, we have completed the understanding of attention from the encoder point of view of the transformer. The decoder uses a slightly different multi-head attention with masking. I will cover this in my subsequent posts.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

