



DIAYN: Diversity Is All You Need
Last Updated on July 20, 2023 by Editorial Team
Author(s): Sherwin Chen
Originally published on Towards AI.
Diving Into DIAYN U+007C Towards AI
An Unsupervised Information-Based Method to Learn Diverse Skills
Introduction
We discuss an information-based reinforcement learning method that explores the environment by learning diverse skills without the supervision of extrinsic rewards. In a nutshell, the method, namely DIAYN(Diversity Is All You Need), establishes the diversity of skills through an information-theoretic objective, and optimizes it using a maximum entropy reinforcement learning(MaxEnt RL) algorithm(e.g., SAC). Despite its simplicity, this method has been demonstrated to be able to learn diverse skills, such as walking and jumping, on a variety of simulated robotic tasks. Moreover, it is able to solve a number of RL benchmark tasks even without receiving any task reward. For more interesting experimental results, please refer to their project website.
Preliminaries
We define a Markov Decision Process(MDP) by the tuple (S, A, P, r, γ), where S is the set of state, A is the set of actions, P: S × A → S is the transition function, r is the reward function, and γ is the discounted factor. An RL algorithm aims to maximize the discounted sum of the expected rewards defined as

In DIAYN, we do not consider the reward signal from the environment. Instead, we define task-independent rewards based on information theory as we will see soon.
Diversity Is All You Need
In DIAYN, we define a skill as a latent-conditional policy that alters the state of the environment in a consistent way. Mathematically, a skill is denoted by the conditional policy p(aU+007Cs, z), where z is a latent variable sampled from some distribution p(z). The method is mainly built upon three ideas (For those not familiar with the concept of mutual information, I recommend referring to the second section of this post to gain some intuition first):
- For skills to be useful, we want the skill to dictate the states that the agent visits. Different skills should visit different states, and hence be distinguishable. To achieve this, we maximize the mutual information I(S; Z) between states S and skills Z.
- We want to use states, not actions, to distinguish skills, because actions that do not affect the environment are not visible to an outside observer. This is done by minimizing the mutual information I(A; ZU+007CS) between actions A and skills Z given the state S.
- We encourage exploration and incentivize the skills to be as diverse as possible by learning skills that act as randomly as possible. As done in maximum entropy reinforcement learning, this is achieved by maximizing the policy entropy H(AU+007CS).
If we put together all three objectives, we will get
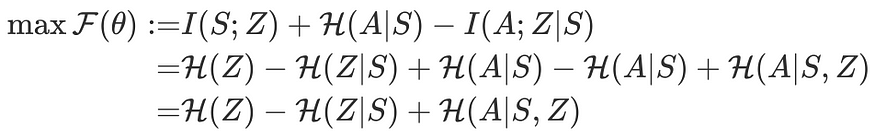
We now develop some intuitions on each term. The first term encourages our prior distribution p(z) to have high entropy. For a fixed set of skills, we set p(z) to be a discrete uniform distribution guaranteeing that it has maximum entropy. Minimizing the second term suggests that it should be easy to infer the skill from the current state. The third term indicates that each skill should act as randomly as possible.
We can easily maximize the third term with some MaxEnt RL method(e.g. SAC with temperature 0.1 used in their experiments). As for the first two terms, the authors propose incorporating them into a pseudo-reward:

where a learned discriminator q_ϕ(zU+007Cs) is used to approximate p(zU+007Cs), which is valid since
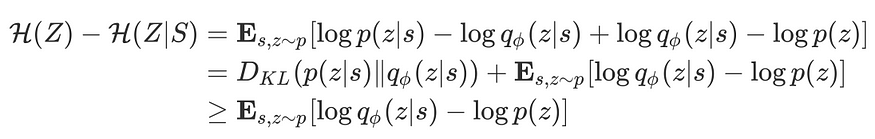
Note that the constant log p(z) in the reward function helps encourage the agent to stay alive if q_ϕ(zU+007Cs) ≥ p(z), which should always be held when the agent succeeds learning the skill p(aU+007Cs, z). On the other hand, removing log p(z) results in negative rewards, which tempts the agent to end the episode as quickly as possible.
Algorithm
Until now we have defined the unsupervised MDP and specified the reinforcement learning method, it is easy to figure out the whole algorithm:

Incorporating DIAYN into Hierarchical Reinforcement Learning
Networks learned by DIAYN can be used to initialize a task-specific agent, which provides a good way for initial exploration. Another interesting application of DIAYN is to use the learned skills as low-level policies of a Hierarchical Reinforcement Learning(HRL) algorithm. To do so, we further learn a meta-controller that chooses which skill to execute for the next k steps. The meta-controller has the same observation space as the skills and aims to maximize the task reward.

The authors experiment with the HRL algorithm on two challenging simulated robotics environments. On the cheetah hurdle task, the agent is rewarded for bounding up and over hurdles, while in the ant navigation task, the agent must walk to a set of 5 waypoints in a specific order, receiving only a sparse reward upon reaching each waypoint. The following figure demonstrates how DIAYN outperforms some state-of-the-art RL methods.

It is worth noting that plain DIAYN struggles on the ant navigation task like the others. This can be remedied by incorporating some prior knowledge into the discriminator. Specifically, the discriminator instead takes as input f(s) that computes the agent’s center of mass and the HRL method is left as it is. ‘DIAYN+prior’ shows this simple modification to the discriminator significantly improves the performance.
References
Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, Sergey Levine. Diversity is All You Need: Learning Skills without a Reward Function. Presented at ICLR 2019.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

