



Detect Malicious JavaScript Code Using Machine Learning
Last Updated on January 6, 2023 by Editorial Team
Last Updated on June 28, 2022 by Editorial Team
Author(s): Maria Zorkaltseva
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
In this article, we will consider approaches to detect obfuscated JavaScript code snippets using machine learning.
Introduction
Most websites use JavaScript (JS) code to make dynamic content; thus, JS code becomes a valuable attack vector against browsers, browser plug-ins, email clients, and other JS applications. Among common JS-based attacks are drive-by-download, cross-site scripting (XSS), cross-site request forgery (XSRF), malvertising/malicious advertising, and others. Most of the malicious JS codes are obfuscated in order to hide what they are doing and to avoid being detected by signature-based security systems. In other words, the obfuscation technique is a sequence of confusing code transformations to compromise its understandability, but at the same time to save its functionality.

Conventional antiviruses and Intrusion Detection Systems (IDS) employ heuristic-based and signature-based methods to detect malicious JS code. But this analysis can be inefficient in case of zero-day attacks. Machine learning (ML) applications, which are currently being actively developed in various industries, have also found their place in cybersecurity. ML has shown its effectiveness against zero-based attacks. When it comes to detecting malicious JS code, there are different approaches from the field of Natural Language Processing (NLP), standard ML that uses tabular data, and deep learning models.
The input data for ML models will vary due to the fact that there are two methods to analyze the behavior of the program: static and dynamic code analysis. The static method analyzes the data without running the source code and is based on source code only. For instance, this can be archived by traversing the code Abstract Syntax Tree. In opposite, dynamic code analysis requires source code to be executed. In this post, we will consider only cases of static analysis.
In this article, we will look at some related work to get an idea of what researchers offer for obfuscated JS code detection. And also will consider the task of classifying benign /malicious JS code snippets using a combination of NLP features and the standard ML approaches.
Related work
In “Detecting Obfuscated JavaScripts using Machine Learning” the authors used a dataset of regular, minified, and obfuscated samples from a content delivery network jsDelivr, the Alexa top 500 websites, a set of malicious JavaScript samples from the Swiss Reporting and Analysis Centre for Information Assurance MELANI. Authors showed that it is possible to distinguish between obfuscated and non-obfuscated scripts with precision and recall around 99%. The following set of features has been used:
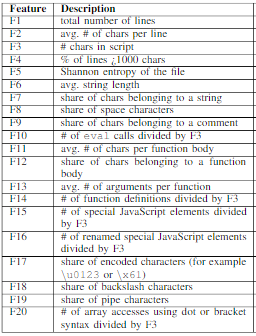
The extracted set of feature vectors was utilized to train and evaluate three different classifiers: Linear Discriminant Analysis (LDA), Random Forest (RF), and Support Vector Machine (SVM).
In “A machine learning approach to detection of JavaScript-based attacks using AST features and paragraph vectors” the authors used another approach to extract features from JS codes. They employed Abstract Syntax Tree (AST) for code structure representation and used it as input to the Doc2Vec method. Drive-by-download data by Marionette for malicious JS codes and the JSUNPACK plus Alexa top 100 websites datasets for benign JS codes were used as datasets for training. For the purpose of constructing AST authors used Esprima, a syntactical and lexical analyzing tool.
While the previous approaches rely on lexical and syntactic features, the approach considered in “Malicious JavaScript Detection Based on Bidirectional LSTM Model” leverages semantic information. Along with AST features, the authors constructed the Program Dependency Graph (PDG) and generated JS code semantic slices which were transformed into numerical vectors. Then these vectors were fed into Bidirectional Long Short-Term Memory (BLSTM) neural network. BLSTM model showed performance with 97.71% accuracy and 98.29% F1-score.
To sum up here can be identified several common approaches to feature JS code in case of static analysis:
- Approach 1 (natural language): consider JS code as natural language text. Features can be represented as a collection of characters statistics, file entropies, special functions count, number of special symbols, etc.
- Approach 2 (lexical features): regex expressions to extract plain-JS text elements (like [a-z]+ and removing special characters such as ∗,=, !, etc.) combined with NLP featurization method applications like Bag-of-Words (BOW), TF-IDF, Doc2Vec, LDA, embeddings, and etc.
- Approach 3 (syntactic features): AST features plus NLP featurization;
- Approach 4 (semantic features): get AST features -> construct Control Flow Graph (CFG) -> build Program Dependency Graph (PDG) -> get semantic slices -> transformation to numerical vectors.
Coding section: Classification of benign /malicious JS code
For this purpose, let's use a dataset from Machine learning for the cyber security cookbook. For simplicity, I will use approach 1, mentioned above.
Data downloading

Data cleansing
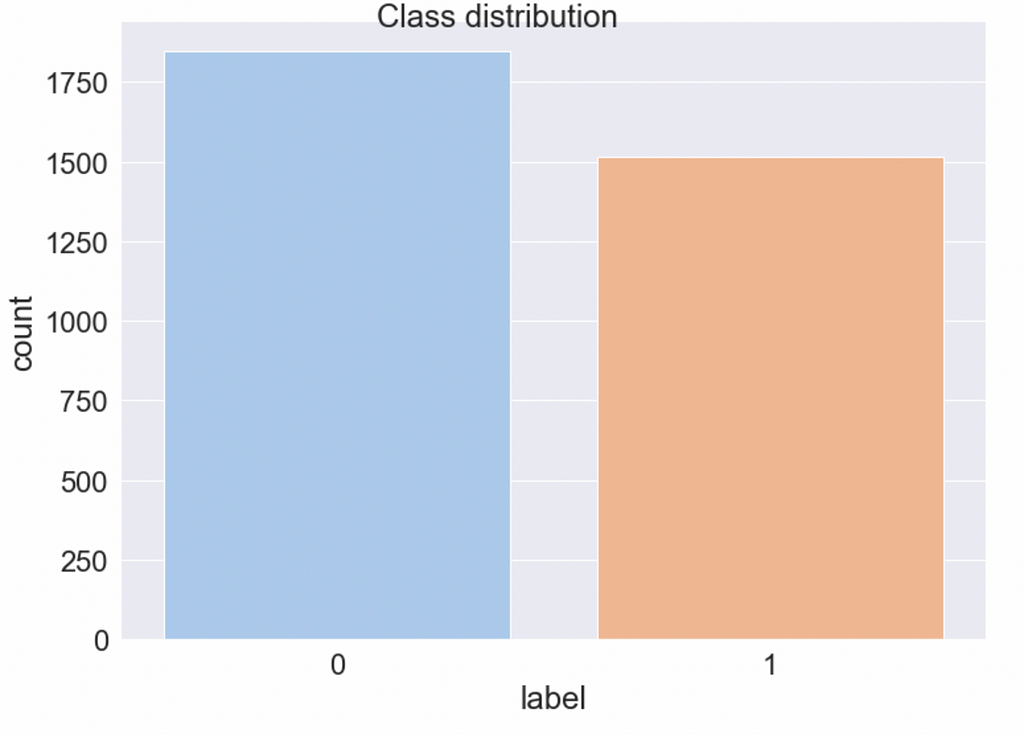
0-label — normal code, 1-label — obfuscated code

Feature engineering
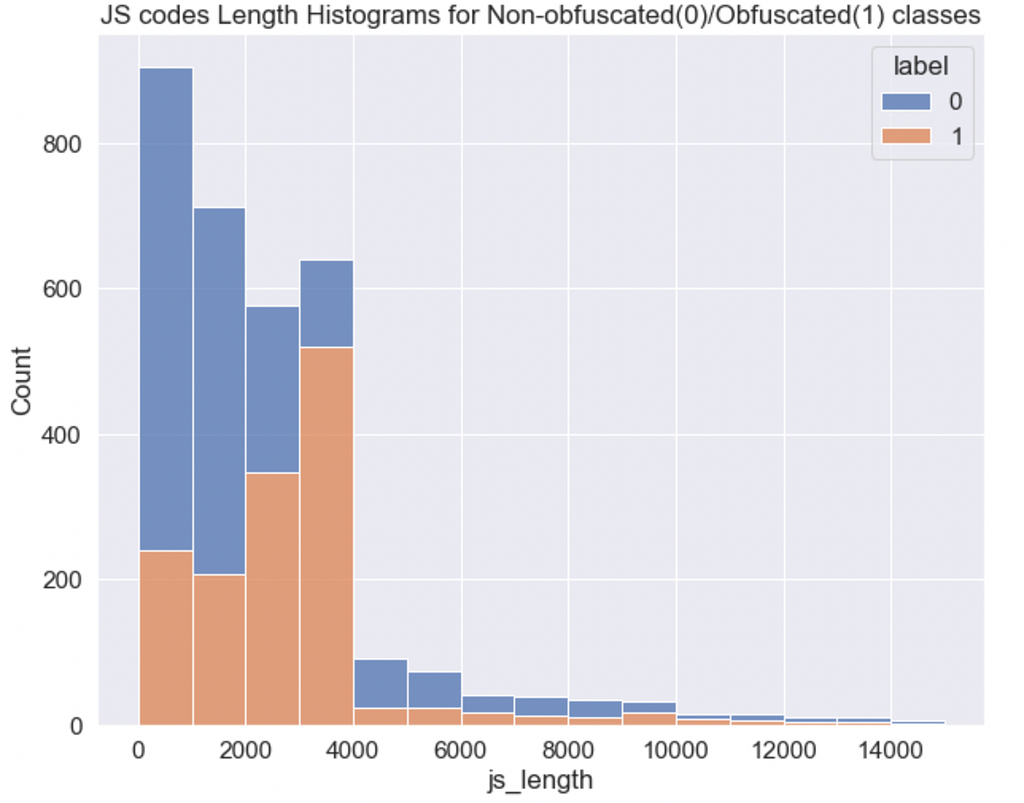
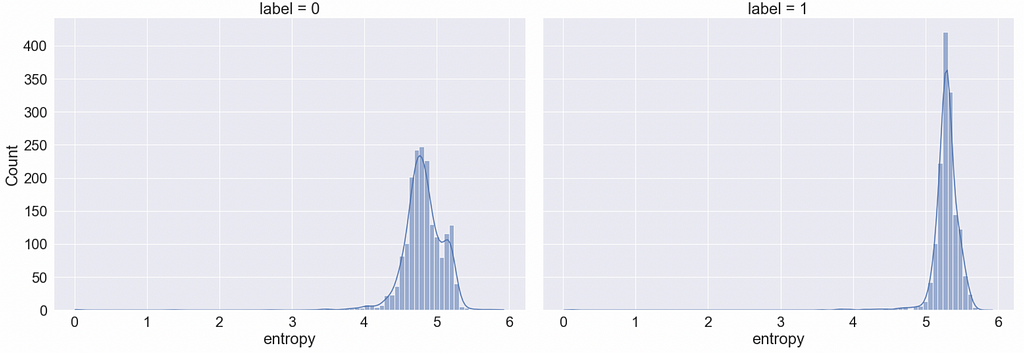
For other features ideas I used the following list of JS functions that are frequently used in malicious JS codes:





Train/test data split
Random Forest Model
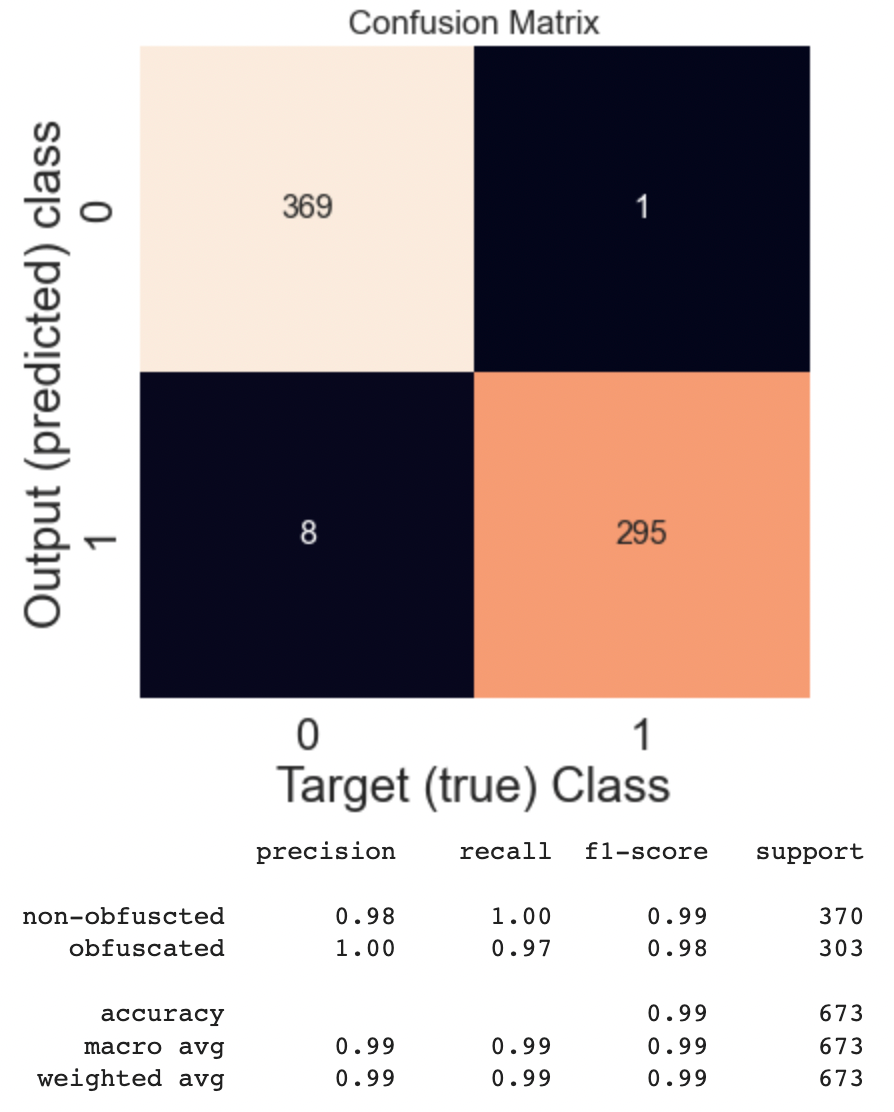
Metrics results
👉🏻 Full code is also accessible through my GitHub.
Further reading
[1] S. Aebersold et al., Detecting Obfuscated JavaScripts using Machine Learning (2016), ICIMP 2016: The Eleventh International Conference on Internet Monitoring and Protection
[2] S. Ndichu et al., A machine learning approach to detection of JavaScript-based attacks using AST features and paragraph vectors (2019), Applied Soft Computing
[3] A. Fass et al., JAST: Fully Syntactic Detection of Malicious (Obfuscated) JavaScript (2018), DIMVA
[4] X. Song et al., Malicious JavaScript Detection Based on Bidirectional LSTM Model (2020), Applied Sciences
Detect Malicious JavaScript Code Using Machine Learning was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


