



Deep Reinforcement Learning for Cryptocurrency Trading: Practical Approach to Address Backtest…
Last Updated on February 1, 2023 by Editorial Team
Author(s): Berend
Originally published on Towards AI.
Deep Reinforcement Learning for Cryptocurrency Trading: Practical Approach to Address Backtest Overfitting
This article, written by Berend Gort, details a project he worked on as a Research Assistant at Columbia University. The project will be generously donated to the open-source AI4Finance Foundation, which aims to establish a foundation similar to Linux and Apache in the cutting-edge field of AI and finance.
The article will discuss Berend’s recently published paper. Inspired after reading the book Advances in financial machine learning by Marcus Lopez de Prado [1][2], Berend set out to find novel frameworks for measuring overfitting in deep reinforcement learning. The resulting paper was presented at the ICAIF ’22 workshop and will be further showcased at AAAI ’23. In addition, this article will provide a comprehensive guide on how to reproduce the results outlined in the paper, with the open-source framework readily available at the provided link:
Imagine you’re a pirate on the high seas of the crypto market, searching for treasure (AKA profits). But, just like any treasure hunt, there are obstacles to overcome. One big problem is the market’s volatility — it’s like a stormy sea that can sink your ship at any moment. Previous researchers have tried using deep reinforcement learning methods (think of them as treasure maps) to navigate the market and found some success in their backtesting (a practice run of the treasure hunt). But here’s the catch: these maps may not be accurate because they can be affected by something called overfitting (like a fake treasure map).
That’s where we come in! We have a solution to help you avoid overfitting and increase your chances of success on your crypto treasure hunt. We use a method called hypothesis testing (like a treasure map authenticity checker) to detect overfitting, then train our DRL agents (treasure maps) and reject any that fail the test. After that, we put our method to the test. And guess what? Our less overfitted DRL agents had a higher return compared to more overfitted agents, an equal weight strategy and even the market benchmark. This gives us confidence that our approach can be used in the real market (finding real treasure).
The main motivation for addressing the issue of overfitting in machine learning is the fact that models can easily become too specific to the data they were trained on. This is particularly problematic in financial machine learning, as the performance of models must be tested in the future market rather than on the same distribution as the training data. In image classification, for example, the overfitting issue is less severe due to the availability of large datasets like ImageNet. However, in financial machine learning, it is crucial to ensure that models are able to generalize and perform well in the future market rather than just on historical data. To address this issue, techniques such as regularization and cross-validation can be used to prevent overfitting and improve the generalization of models.
So, pack your bags, grab your treasure map, and set sail on the crypto market with our approach, and you may just strike it rich!
Introduction
In our paper, we aimed to address the problem of overfitting in deep reinforcement learning (DRL) methods for cryptocurrency trading. Overfitting occurs when a model is trained too well on the training data and performs poorly on new, unseen data. We proposed a practical approach to detect and address overfitting using hypothesis testing. We tested our method using 10 different cryptocurrencies over a period of time where the market experienced two crashes and found that the less overfitted DRL agents had a higher return compared to more overfitted agents, an equal weight strategy, and the S&P DBM Index (market benchmark). This gives us confidence that our approach can be used in the real market. In summary, our paper aims to provide a method to ensure that DRL practitioners’ chosen agents do not overfit during the training period, making their results more reliable and trustworthy.
Related Works
Why did the DRL agent need a backtest? To prove it wasn’t just a one-hit wonder!
Our paper discusses different methods for backtesting the performance of a deep reinforcement learning (DRL) agent for financial trading.
The first method, called the Walk-Forward (WF) method, is the most widely applied practice. However, it has the potential to overfit, meaning it may not generalize well to future market situations.
The second method, called k-fold cross-validation (KCV), aims to alleviate the overfitting problem by partitioning the dataset into k subsets and training the agent on different subsets. However, this method still has risks of overfitting and informational leakage.
To address these issues, we suggest a third method called combinatorial purged cross-validation (CPCV), which simulates a wider variety of market situations to reduce overfitting and controls for leakage.
In the context of backtesting a DRL agent, information leakage refers to the situation where knowledge from the testing set (which is supposed to be unseen by the agent during training) influences the training of the agent. This can happen if the testing set and the training set are not properly separated or if the evaluation metric used in testing is also used during training. This can lead to an overfitting problem where the agent performs well on the test set but not on new unseen data.
Looks like this DRL agent passed its backtest with flying colors. Just don’t ask it to perform on a rainy day!
Model the Cryptocurrency Trading Task
Markov Decision Process
We use a method called Markov Decision Process (MDP) to model this problem. In this method, the program’s current state is represented by information such as the cash amount in the account, the shareholdings of different currencies, the prices at a given time, and a bunch of technical indicators that give us an idea of how the market is doing.
Assuming that there are D cryptocurrencies and T time stamps, t = 0, 1, …, T − 1. We use a deep reinforcement learning agent to make trading actions, which can be either buy, sell, or hold. An agent observes the market situation, e.g., prices and technical indicators, and takes actions to maximize the cumulative return. We model a trading task as a Markov Decision Process (MDP):

We consider 15 features that are used by existing papers but filter a few out. As shown in Fig. 1, if two features have a correlation exceeding 60%, we drop either one of the two. Finally, 6 uncorrelated features are kept in the feature vector, which are trading volume, RSI, DX, ULTSOC, OBV, and HT.

Building Market Environment
The explanations below are implemented in the Alpaca Environment.
Why did the DRL agent filter out correlated features? To keep its trading strategy as fresh as a daisy!
We build a market environment by replaying historical data, following the style of OpenAI Gym. A trading agent interacts with the market environment in multiple episodes, where an episode replays the market data (time series) in a time-driven manner from t = 0 to t = T − 1. At the beginning (t = 0), the environment sends an initial state s 0 to the agent that returns an action a 0. Then, the environment executes the action a t and sends a reward value r t and a new state s t+1 to the agent, for t = 0, …, T − 1. Finally, s T −1 is set to be the terminal state. The market environment has the following three functions:

Transaction fees. Each trade has transaction fees, and different brokers charge varying commissions. For cryptocurrency trading, we assume that the transaction cost is 0.3% of the value of each trade. Therefore, (2) becomes

The transaction fee can be found in the Alpaca Environment fou (around lines 131 and 148). Moreover, there cannot be a negative balance or sell; therefore, in the environment, some asserts are placed to make sure the environment is bug-free.
Backtest Overfitting Issue
A Backtest uses historical data to simulate the market and evaluates the performance of an agent, namely, how an agent would have performed should it have been run over a past time period. Researchers often perform backtests by splitting the data into two chronological sets: one training set and one validation set. However, a DRL agent usually overfits an individual validation set that represents one market situation. Thus, the actual trading performance is in question.
Backtest overfitting occurs when a DRL agent fits the historical training data to a harmful extent. The DRL agent adapts to random fluctuations in the training data, learning these fluctuations as concepts. However, these concepts do not exist, damaging the performance of the DRL agent in unseen states.
Why did the DRL agent fail its backtest? It was too busy overfitting!
Practical Approach to Address Backtest Overfitting
We propose a practical approach to address the backtest overfitting issue. First, we formulate the problem as a hypothesis test and reject agents that do not pass the test. Then, we describe the detailed steps to estimate the probability of overfitting, p in the range [0,1].
Hypothesis Test to Reject Overfitted Agents
We formulate a hypothesis test to reject overfitted agents. Mathematically, it is expressed as follows:
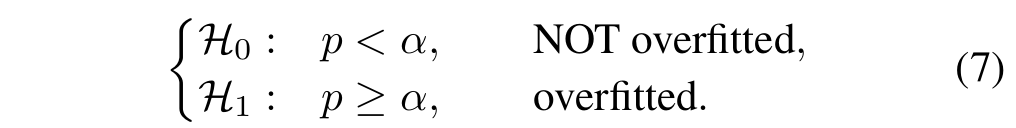
Where α > 0 is the level of significance. The hypothesis test (7) is expected to reject two types of false-positive DRL agents. 1) Existing methods may have reported overoptimistic results since many authors were tempted to go back and forth between training and testing periods. This type of information leakage is a common reason for backtesting overfitting. 2). Agent training is likely to overfit since DRL algorithms are highly sensitive to hyper-parameters. For example, one can train agents with PPO, TD3, or SAC algorithm and then reject agents that do not pass the test.
The DRL agent took a hypothesis test, and it was a real overfitting buster!
Estimating the Probability of Overfitting
The explanations below are implemented in the CPCV class.
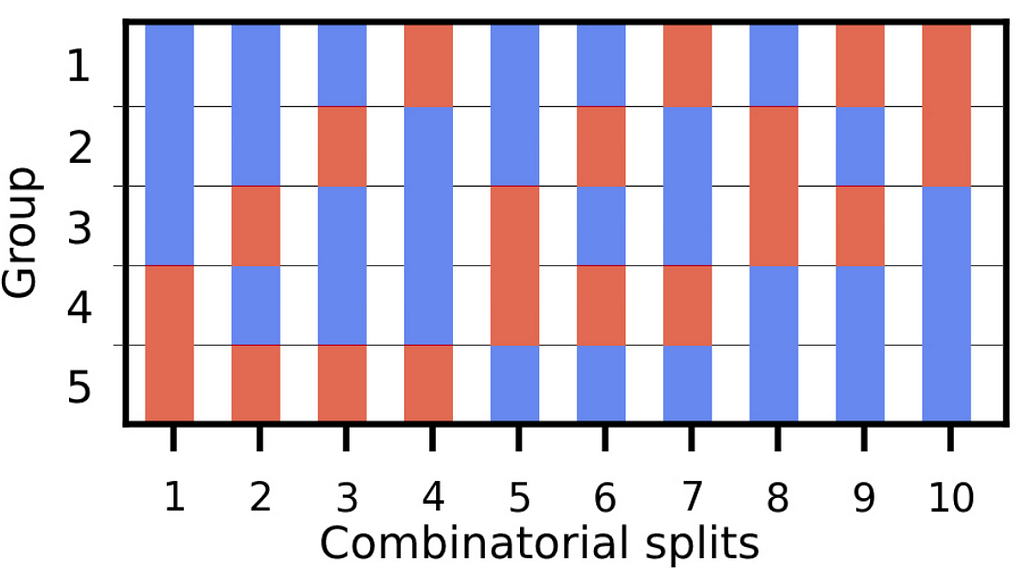
Combinatorial Cross-validation allows for training and validation in different market situations. Given a training time period, the following steps are performed:
Step 1 (Training-validation data splits): See Fig. 2; Divide the training period with T data points into N groups of equal size. K out of N groups construct a validation set, and the rest of N-k groups as a training set, resulting in J = (N/N-k) combinatorial splits. The training and validation sets have (N-k)(T/N) and T’ = k(T/N) data points, respectively.
Step 2 (One trial of hyperparameters): Set a new set of parameters for hyperparameter tuning.
Step 3: In each training-validation data split, we train an agent using the training set and then evaluate the agent’s performance metric for each validation set, i = 1, …, H. After training on all splits, we take the mean performance metric overall validation sets.
Step 2) and Step 3) constitute one hyperparameter trial. Loop for H trials and select the set of hyperparameters (or DRL agent) that performs the best in terms of mean performance metric overall splits. This procedure considers various market situations, resulting in the best-performing DRL agent over different market situations. However, a training process involving multiple trials will result in overfitting.
Therefore, we want to have a metric for overfitting…
Probability of Overfitting
The explanations below are implemented in the PBO class.
We estimate the probability of overfitting using the return vector. The return vector is defined as Rt = v(t)- v(t-1), where v(t) is the portfolio value at time step t. We estimate the probability of overfitting via three general steps:
Step 1: For each hyperparameter trial, average the returns on the validation sets (of length T’) and obtain R_avg in R^T’.
Step 2: For H trials, stack R_avg into a matrix M in R^T’xH.
Step 3: Based on M, we compute the probability of overfitting p
Pick the number of splits, the more splits, the more accurate the probability of overfitting will be. With 16 splits or higher, the probability of overfitting will have a > 95% confidence interval. For simplicity, we take splits S = 4:
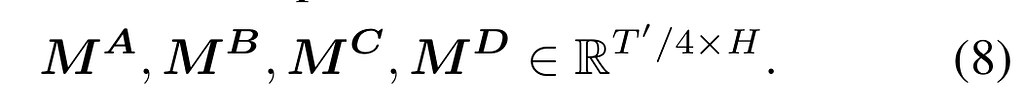
Now we create all possible combinations between the splits, where without a bar indicates the in-sample set, and with a bar, the out-of-sample sat.

Let's only take the example with subscript 1 and perform the PBO computation. First, form the train set (without a bar) and the test set (withWe use a method called Markov Decision Process (MDP) to model this problem. In this method, the program’s current state is represented by information such as the cash amount in the account, the shareholdings of different currencies, the prices at a given time, and a bunch of technical indicators that give us an idea of how the market is doing.
Assuming that there are D cryptocurrencies and T time stamps, t = 0, 1, …, T − 1. We use a deep reinforcement learning agent to make trading actions, which can be either buy, sell, or hold. An agent observes the market situation, e.g., prices and technical indicators, and takes actions to maximize the cumulative return. We model a trading task as a Markov Decision Process (MDP):
Image by Author. We consider 15 features that are used by existing papers but filter a few out. As shown in Fig. 1, if two features have a correlation exceeding 60%, we drop either one of the two. Finally, 6 uncorrelated features are kept in the feature vector, which are trading volume, RSI, DX, ULTSOC, OBV, and HT. bar):
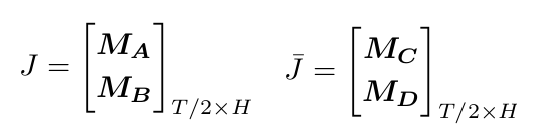
Then, we compute the Sharpe ratio (or whatever metric you prefer) and amount rank the resulting columns based on the Sharpe ratio. Note that the amount of columns is equal to the number of hyperparameter trials. Imagine the ranking constitutes the following two vectors:
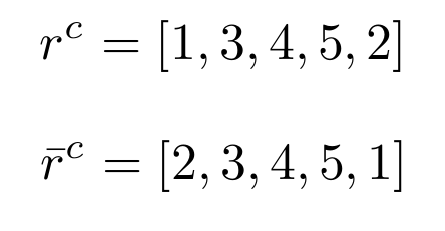
Then we check the second vector at that index 3, which is 5. Now we can compute the relative rank:
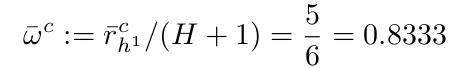
The formula uses (N + 1) as the denominator for w̄, to avoid w̄ = 1.0. This would lead to infinity in logits. One cannot be 100% sure because all of the samples have outperformed one.
Now we use the logit function to convert these occurrences to a probability:
We have performed this now only for one sample, namely sample 1! We gather these logits from every sample c1 — c6, and then we simply count the number of logits < 0 divided by the total number of logits. This is our probability of overfitting. This is what constitutes the next formula:

Performance Evaluations
For the first case, we use the walk-forward method to train a conventional agent using the PPO algorithm and a training-validation-testing data split. We then calculate the probability of overfitting (p) for this agent. Next, we train another conventional agent using the PPO algorithm and the k-fold cross-validation method with k=5.
For the second case, we use the probability of overfitting to measure the likelihood that an agent is overfitted when tuning the hyperparameters for three different agents: TD3, SAC, and PPO. We calculate p for each agent with each set of hyperparameters for H=50 trials.
To measure an agent’s performance, we use three metrics: cumulative return, volatility, and probability of overfitting. The cumulative return measures the profits, volatility measures the degree of variation of a trading price series over time, and the probability of overfitting measures the likelihood that an agent is overfitted.
We also compare the performance of our proposed method to two benchmark methods: an equal-weight portfolio and the S&P Cryptocurrency Broad Digital Market Index (S&P BDM Index). The equal-weight strategy distributes the available cash equally among all available cryptocurrencies at time t0, while the S&P BDM index tracks the performance of cryptocurrencies with a market capitalization greater than $10 million.
Rejecting Overfitted Agents
In this section, we investigate the performance of conventional and deep reinforcement learning (DRL) agents. We use a logit distribution function to measure the probability of overfitting, represented by the area under the curve for the domain [-\infty, 0].
Fig. 4 below shows the results for conventional agents, where we compare our PPO approach to the WF and KCV methods. We find that the WF method has a higher probability of overfitting at 17.5%, while the KCV method has a lower probability at 7.9%. Our PPO approach has an even lower probability of overfitting at 8.0%.
Fig. 5 presents the results for DRL agents, specifically PPO, TD3, and SAC. We find that the SAC method has the highest probability of overfitting at 21.3%, while PPO and TD3 have lower probabilities at 8.0% and 9.6%, respectively. Table \ref{tab: hyperparameters_per_agent} shows the specific hyperparameters used for each agent.
Overall, these results suggest that our PPO and TD3 methods have lower probabilities of overfitting compared to conventional and other DRL methods and could be more suitable for use in practical applications.

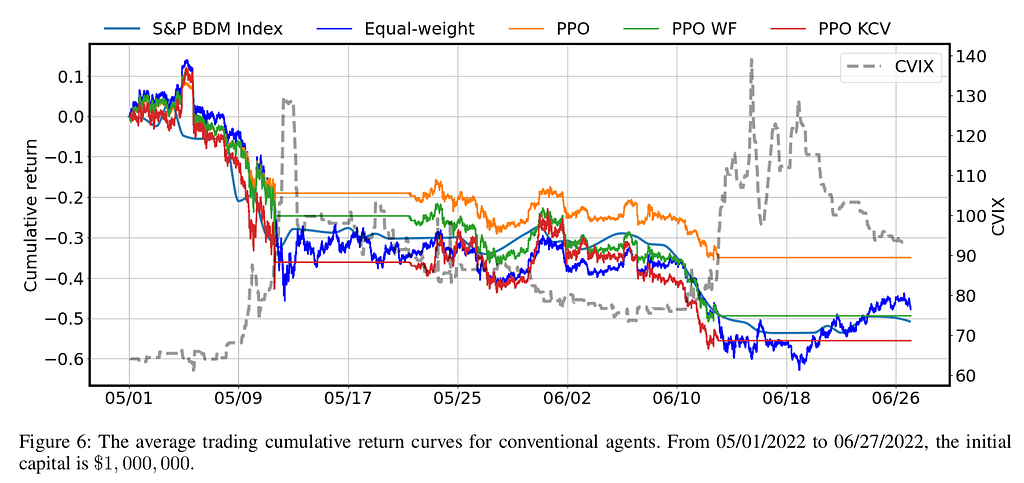
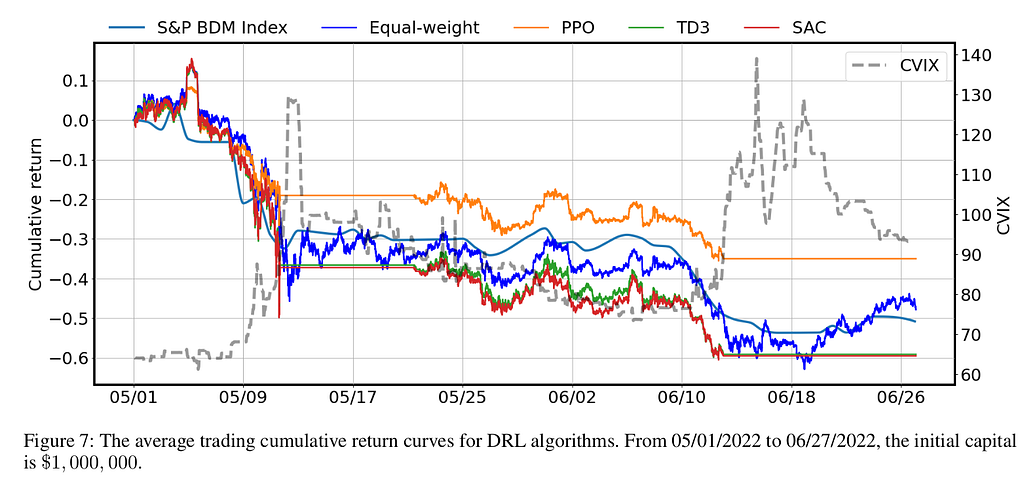
Backtest Performance
In this section, we present the results of our backtest performance. We utilized two figures, Fig.6 and Fig. 7, to show the results of our agent’s performance. Our agent utilizes a CVIX indicator, which, when surpassing $90$, causes the agent to stop buying and selling all cryptocurrency holdings. We compare the performance of our agent with conventional agents, market benchmarks, and our approach. The results show that our method significantly outperforms the other two agents, PPO WF and PPO KCV, with at least a 15% increase in cumulative return. Additionally, our method also demonstrates lower volatility, indicating that it is more robust to risk. Furthermore, when comparing our approach to the DRL agents, TD3 and SAC, our PPO agent outperforms them with a significant increase in cumulative return (>24%) and lower volatility. Finally, when compared to the benchmarks, our approach outperforms in terms of cumulative return and volatility. Based on these results, we conclude that the PPO agent is the superior agent among those tested.

Conclusion
Ahoy mateys! In this here paper, we set sail on a journey to uncover the treasure of addressing the backtesting overfitting issue in cryptocurrency trading with deep reinforcement learning. And let me tell ye. We struck gold! Our findings show that the PPO agent (with its trusty combinatorial CV method) outperforms all the other landlubbers, including the conventional agents, other DRL agents, and even the S&P DBM Index in both cumulative return and volatility. And let’s not forget. It’s mighty robust too!
As for future voyages, we are plannin’ on 1). huntin’ for the evolution of the probability of overfitting during training and for different agents; 2). testin’ limit order setting and trade closure; 3). explorin’ the vast seas of large-scale data, such as all currencies corresponding to the S&P BDM index; and 4). takin’ on more booty, such as fundamentals and sentiment features for the state space. So, hoist the anchor and set sail for the high seas of cryptocurrency trading with us!
~ Thanks for Reading 😉
Berend Gort
Reference
- Bailey, D. H., Borwein, J. M., López De Prado, M., & Zhu, Q. J. (2017). The probability of backtest overfitting. Journal of Computational Finance, 20(4), 39–69. https://doi.org/10.21314/JCF.2016.322
2. Prado, M. L. de. (2018). Advances in financial machine learning.
Deep Reinforcement Learning for Cryptocurrency Trading: Practical Approach to Address Backtest… was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts


")



