



Deep Dive of TableNet
Last Updated on August 21, 2022 by Editorial Team
Author(s): Ankit Sirmorya
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Introduction
To obtain data for their own goals, humans rely largely on technology. With the increasing use of mobile phones and scanners to capture and upload documents in this modern age, the necessity for extracting information locked in unstructured document pictures such as shop receipts, insurance claim forms, and bank invoices is growing. One major hurdle to achieving this aim is that these pictures usually contain information in the form of tables, and extracting data from tabular sub-images provides a distinct set of issues. This comprises recognizing and extracting information from the identified table’s rows and columns after properly detecting the tabular region inside a picture [1]. While some progress has been made in table detection, extracting table contents remains difficult because it requires more fine-grained table structure (rows and columns) recognition.
TableNet, a unique end-to-end deep learning model for both table identification and structure recognition, is offered as a useful tool in this paper [1]. Previously, two different models were utilized to handle the table identification and structure recognition difficulties in a document. When parsing different table structures, these methods are stiff and usually demonstrate poor generalization. AI-based systems based on deep learning algorithms have emerged as a possible alternative to rule-based systems due to their capacity to learn and generalize [2]. Image recognition, natural language processing, and translation all employ the same algorithms. However, much of the work in table extraction is done in academia; there are few production-ready table extraction systems that can deliver dependable and precise extraction. TableNet is a deep-learning-based invoice table extraction solution that is ready for production [2].
TableNet is in the spotlight owing to its superior prediction of data on table information extraction. We can see from [3] that different table predictions are performed to display TableNet performance and discovered that TableNet could extract data in column and row format more correctly. This is why table data extraction is now a priority.
What is TableNet
TableNet is a revolutionary end-to-end deep learning network capable of detecting and recognizing tables [1]. The model takes use of the dependency between the twin objectives of table detection and table structure identification to separate out the table and column areas. TableNet is considered a sophisticated machine learning architecture introduced by a TCS Research team in 2019 [4]. The major purpose was to use mobile phones or cameras to retrieve data from scanned tables. They presented a strategy that comprises recognizing and extracting information from the discovered table’s rows and columns after properly detecting the tabular region inside a picture [4].
TableNet uses a single input image to generate two distinct semantically labeled output images for tables and columns. The model accomplishes this by using pretrained VGG-19 as the base network and then two decoder branches based on VGG-19 features [5]. One decoder branch is in charge of table region segmentation, while another is in charge of column region segmentation. The encoding layer of VGG19 is shared by both the table and column detectors, but the decoders for the two jobs are different. The shared common layers are trained repeatedly using gradients from both the table and column detectors, while the decoders are learned individually [7]. Semantic information regarding simple data kinds is then used to improve model performance even more. The use of the VGG-19 as a base network that has been pre-trained on the ImageNet dataset enables the exploitation of past knowledge in the form of low-level characteristics learned during ImageNet training [7]. Tesseract OCR can be used to extract tabular data after detecting the table and column region. Figure 2 shows how the model works to perform table and column masking.
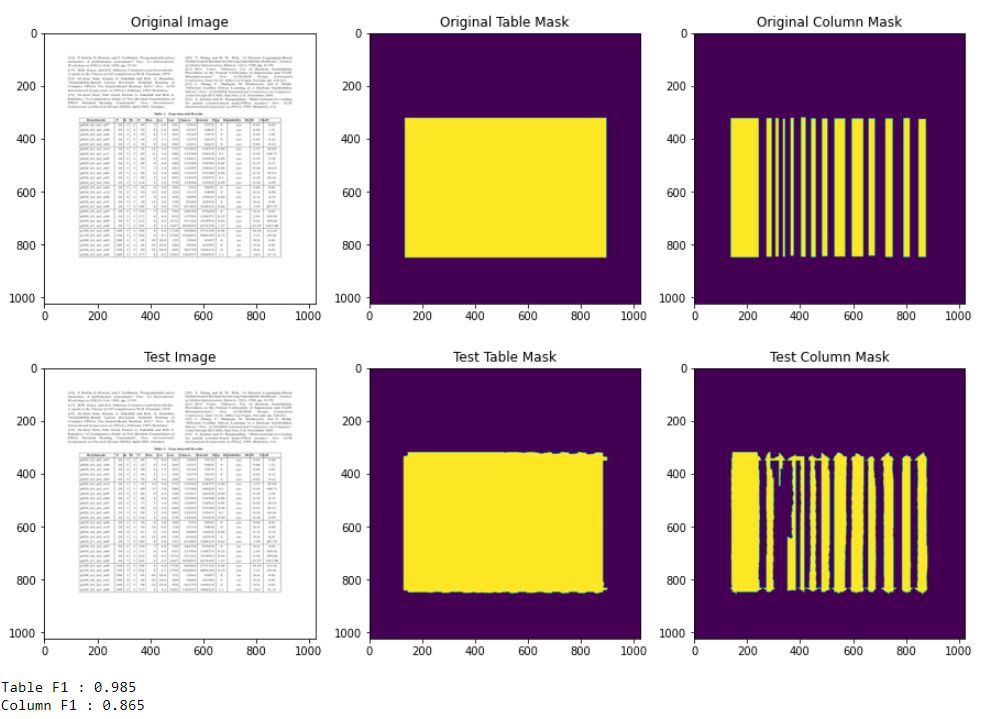
To extract table information from a given input picture, the table and column areas must first be segmented. Consider the scanned picture to be input and the table and column masks to be output [5]. As a result, we must classify each pixel to determine whether or not it belongs to a table. This challenge may be seen as a classification task (segmentation) [5]. TableNet visualizes table and column masks on an input picture in figure 2.
Structure for table data extraction using TableNet
TableNet is a machine-learning system made up of multiple neural networks that work together to [2] make feature maps out of low-level text rectangles (or ‘field names’). If there is a table boundary in the invoice, identify it, and determine the rows. and identify columns as well as their canonical identities (description, quantity, unit price, etc.).
This unique table extraction structure was inspired by how a human could approach interpreting a table from an invoice. It is performed through a sequence of logical steps rather than in a single step. The first step is to find the table within the invoice. This search often requires determining two critical anchors of a table: the table’s beginning (top anchor) and end (bottom anchor) (bottom anchor). When we locate a table, we focus just on the table portion in order to better grasp it, dismissing any other useless information. We learn about tables by dividing them into rows and columns. This dissection is based not just on a table’s physical attributes (such as line separations and spacing) but also on the semantics of text rectangles within the table. Then, within a table, we group related texts together to achieve a far more specific breakdown of rows and columns.
The first several neural network models offer a short summary of the text-rectangle level information and process it in a numeric format (feature map) that the last two models, RowNet and ColumnNet, can comprehend.
RowNet
RowNet then searches the invoice feature map for the table’s top and bottom anchors using a running convolutional filter. It can also recognize the rows in the table [2].
ColumnNet
Once a table is located, all other text rectangles on the feature map are eliminated, with the exception of those inside the top and bottom anchors. ColumnNet is then used to find and identify columns by employing a running convolutional filter (much like how we sweep the table with our eyes) [2].
TableNet model Architecture
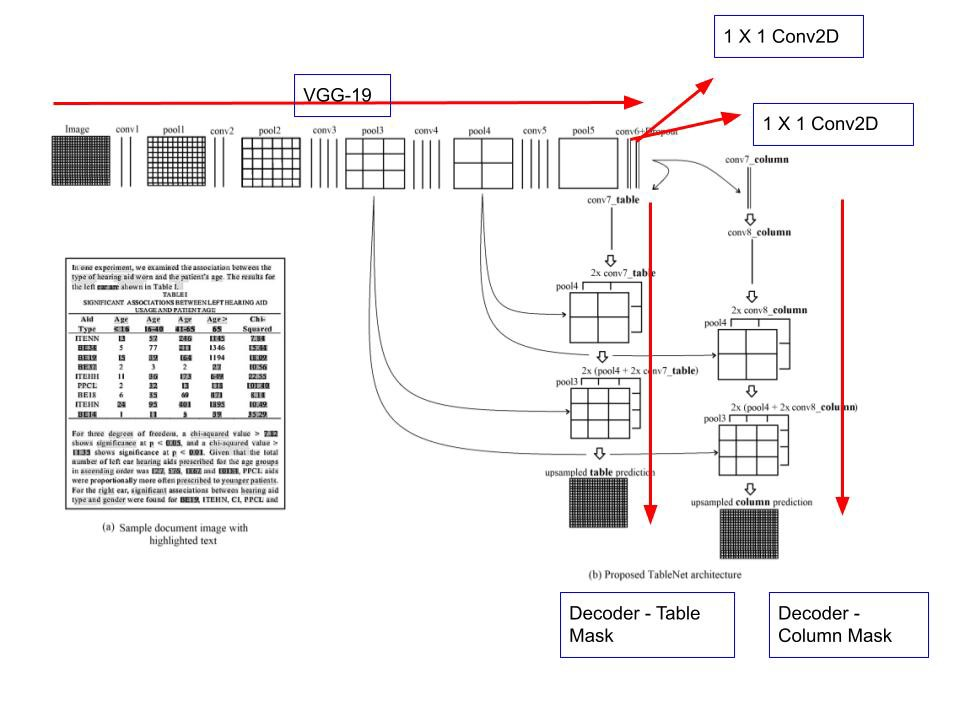
TableNet’s design is based on Long et al’s encoder-decoder approach for semantic segmentation [4]. The same encoder/decoder network as the FCN design is employed for table extraction. The photos are preprocessed and modified using Tesseract OCR. The TableNet model extracts features from input pictures using a pre-trained VGG-19 model [5], and the retrieved features are then processed via two decoder branches to provide masked output]. The picture will be downsampled by the encoder layer and upsampled by the decoder layer.
The challenge of finding tables on paper is comparable to the problem of detecting items in real-world photographs. The model’s input picture is first converted to RGB and then downsized to 1024 X 1024 resolution. This updated picture was created using tesseract OCR [9]. Because a single model generates both the output masks for the table and column areas, these two separate outputs have binary target pixel values depending on whether the pixel region belongs to the table/column region or the background. We used a technique to estimate table and column areas pixel by pixel. Recent work on semantic segmentation based on pixel-wise prediction has been quite effective. Long et al. [10] presented the FCN design to illustrate the accuracy of encoder-decoder network topologies for semantic segmentation. The FCN design employs the skip-pooling approach to merge the low-resolution feature maps of the decoder network with the high-resolution features of the encoder networks. In their model, VGG-16 is employed as the foundation layer, and fractionally-strided convolution layers are used to upscale the obtained low-resolution semantic map, which is then coupled with high-resolution encoding layers. For the encoder/decoder network, our model employs the same idea as the FCN design.
As illustrated in Figure 3, the basic network of our proposed model is a pre-trained VGG-19 layer. VGG-19’s fully linked layers (layers after pool5) are replaced by two (1×1) convolution layers. Each of these convolution layers (conv6) employs ReLU activation, followed by a dropout layer with a probability of 0.8 (conv6 + dropout, as seen in Figure 3). This layer is followed by two separate branches of the decoder network. This follows from the assumption that the column region is a subset of the table region. As a result, the single encoding network can more accurately filter out active areas by integrating characteristics from both table and column regions. The (conv6 + dropout) layer output is delivered to both decoder branches. Additional layers are added to each branch to filter out the active zones. In the table branch of the decoder network, an extra (1×1) convolution layer, conv7 table, is employed before upscaling the picture with a sequence of fractionally strided convolution layers. The output of the conv7 table layer is additionally up-scaled with fractionally strided convolutions before being added to the pool4 pooling layer of the same dimension. The combined feature map is similarly up-scaled, and the pool3 pooling is attached to it. The finished feature map is then upscaled to match the original picture dimension. There is an extra convolution layer (conv7 column) with a ReLU activation function and a dropout layer with the same dropout probability in the other branch for identifying columns. Following a (1×1) convolution (conv8 column) layer, the feature maps are upsampled using fractionally strided convolutions. The pool4 pooling layer is merged with the up-sampled feature maps, and the resultant feature map is up-sampled and mixed with the pool3 pooling layer of the same dimension. Following this layer, the feature map is scaled to match the original picture. Multiple (1×1) convolution layers are employed before the transposed layers in both branches. The idea behind using (1×1) convolution is to reduce the dimensions of feature maps (channels) that are used in pixel class prediction because the output layers (output of encoder network) must have channels equal to the number of classes (channel with the highest probability is assigned to corresponding pixels) that are later up-sampled. As a result, the outputs of the two computational graph branches produce the mask for the table and column areas.
TableNet generates masks for table and column areas after processing the documents. These masks are used to remove the image’s table and column sections. Because all word locations in the document have previously been determined (through Tesseract OCR), only word patches located within table and column areas are filtered out. A row may be defined as a collection of words from numerous columns that are at the same horizontal level using these filtered words. The lines in most tables with line demarcations segment the rows in each column. Every area between two vertically positioned words in a column is evaluated for the existence of lines using a Radon transform to detect probable line demarcation (rows). The use of horizontal line delineation neatly separates the row. If a row spans many lines, the table rows with the most non-blank items are designated as the starting point for a new row. In a multicolumn table, for example, certain columns may have entries that span just one line (such as amount), whereas others may have multi-line entries (like description, etc.). As a result, each new row begins when all of the entities in each column have been filled. In tables with no line demarcations and all columns entirely filled, each line (level) can be seen as a distinct row.

The Marmot [8] table recognition dataset was leveraged to train the model. The dataset was annotated manually by identifying the bounding boxes around each column within the tabular section. The manually annotated improved dataset for table structure identification is freely published under the name Marmot Extended [7].
A. Providing Semantic Information
As demonstrated in Figure 3, spatial semantic information has been introduced by illuminating the words with patches. Histogram equalization is applied to the document pictures first. The word blocks are retrieved using tesseract OCR after preprocessing. The color of these word patches is determined by their fundamental data type. The changed photos that result are sent into the network. The TableNet model takes the input picture and creates distinct binary mask images for the table and columns. The obtained result is filtered using rules defined by the identified table and column masks. Figure 4 depicts an example of the generated output.
B. Training Data Preparation for TableNet
The word patches are color-coded to give the model basic semantic type information. To obtain all of the word patches in the picture document, the image is first processed with tesseract OCR. The words are then parsed using regular expressions to determine their data type. The idea is to color the word boundary boxes in order to provide both semantic and geographical information to the network. Each data type has its own color, and the bounding boxes of words with comparable data kinds are tinted in the same color. To eliminate false detections, word bounding boxes are filtered out. These altered document pictures are then utilized for instructional purposes [7].
The TableNet Model is made up of three major components [5].
- The encoder (VGG-19)
- Decoder (Table Mask Generator)
- Decoder (Column Mask Generator)
Encoder
The model accepts input with the dimensions 1024*1024*3. The input image is then passed through a pre-trained VGG-19 model with no fully connected layers, yielding a feature vector that is then passed to two decoder branches [5].
The input image is then downsampled and passed through two 1×1 conv2D layers. The idea behind using (1×1) convolution is to reduce the dimensions of feature maps (channels) used in pixel class prediction.
Decoder (Table Mask Generator)
The downsampled images were processed again through one 1×1 conv2D layer after passing through two conv2D layers. The low-resolution feature maps of the decoder network are then combined with the high-resolution features of the encoder networks using the skip-pooling technique.
We will get an output table mask with the shape (1024*1024*2) after upsampling [5]. Because we have two class labels, the output image has two channels (background, masked region). To predict the output value of a pixel value, we must select the class with the highest predicted probability.
Decoder (Column Mask Generator)
The feature vector from the 1×1 conv2D layer is passed to the decoder (column mask), but unlike the table decoder, the input feature vector is processed through two 1*1 conv2D layers before being upsampled using the skip-pooling technique. Column decoder output is 1024*1024*2 [5].
For training, TableNet requires both table and structure annotated data. The Marmot [8] table detection data was utilized, and the structural information was manually annotated. There are a total of 1016 papers with tables comprising both Chinese and English texts, 509 of which are annotated and utilized for training. The suggested deep model was built in Tensorflow and tested on a system with an Intel(R) Xeon(R) Silver CPU with 32 cores and 128 GB of RAM, as well as a Tesla V100-PCIE-1 GPU with 6GB of GPU memory. Tables include the outcomes of these investigations. The system takes 0.3765 seconds on average for each document picture [7]; and the fact that the model is end-to-end means that further gains may be achieved with richer semantic information and extra branches for learning row-based segmentation.
Example
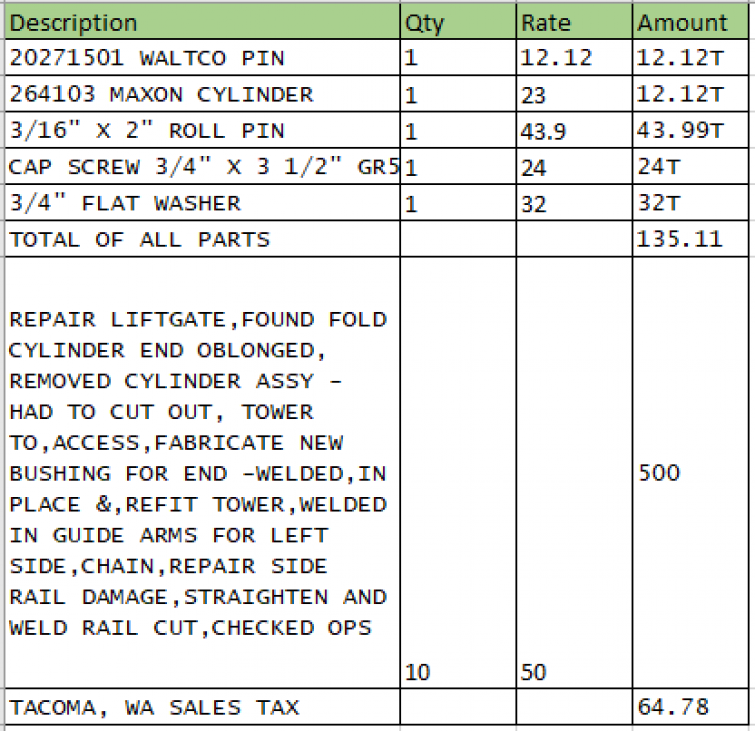
The following example of a table with no defined lines [2] demonstrates the difference. A clear table is seen when a person looks at this invoice. A closer look reveals that the last line item contains some freeform content.
Table reading algorithms, in general, may struggle with this. TableNet, on the other hand, can accurately read the table. This is due to the fact that TableNet was particularly created and trained to understand invoices [2].
TableNet accurately detects the table, rows, and columns and comprehends the semantic meaning of texts in each column.

Conclusion
TableNet is a revolutionary deep learning network that was trained on end-to-end table identification and structure recognition tasks [1]. Existing information extraction algorithms treat detection and structure identification as distinct challenges that must be handled independently. TableNet is the first model to perform both goals at the same time by capitalizing on the intrinsic interdependence of table detection and table structure identification [6]. TableNet may demonstrate transfer learning by transferring information from previously mastered tasks to newer, related ones. This is especially helpful when training data is scarce.
The question addressed by these TableNet tests is what more semantic knowledge may be contributed for greater model performance; potentially, using other abstract data types, such as currency, nation, or city, could be advantageous [1]. This is the research challenge we must undertake in order to make TableNet more efficient in appropriately extracting table data.
Reference
[6] https://ai.nsu.ru/attachments/download/3690
[7] https://arxiv.org/pdf/2001.01469.pdf
[9] An Overview of the Tesseract OCR Engine — Google Research
Deep Dive of TableNet was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


