


")
Data Science Essentials — AI Ethics (III)
Last Updated on January 6, 2023 by Editorial Team
Last Updated on July 10, 2022 by Editorial Team
Author(s): Nitin Chauhan
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Data Science Essentials — AI Ethics (III)
This article is the third part of the AI Ethics for Data Science essential series. If you haven’t read AI Ethics (II), I will encourage you to have a read where I have discussed the importance of identifying Bias and how to eradicate it from predictions. In this article, I will continue with AI Ethics, and focus on creating a fair AI.
What’s a Fair AI?
We can define what we might look for in a fair machine learning (ML) model in many different ways. For example, we are considering a model that approves or denies credit card applications. Is it:
- Would it be fair if the approval rate were equal between ethnic groups?
- Is it better to remove ethnicity from the dataset and hide it from the model?
In this article, we’ll cover four criteria that we can use to determine if a model is fair. We will then apply what you have learned in a hands-on exercise where you will run code to train several models and evaluate the fairness of each model.
What are the fairness criteria?
In addition to these four fairness criteria, there are many other ways to formalize fairness, which you should explore.
Assume we are working with a model that selects individuals to receive a specific outcome. For example, the model may choose those who should receive a loan, admission to a university, or employment. Hence, models that perform tasks such as facial recognition or text generation will not be considered.)
A. Demographic Parity
A model is deemed fair if the composition of those selected by the model matches the percentages of applicants who belong to particular groups.
In an international conference organized by a nonprofit, 20,000 people registered. The organizers write a machine learning model to select 100 potential speaker candidates. Since 50% of the attendees (10,000 out of 20,000) will be women, they designed the model such that 50% of the selected speaker candidates are women.
B. Equal Opportunity
It ensures that the model’s true positive rate (TPR) or sensitivity is the same for every group of individuals that should be selected by the model (positives).
To identify patients at risk of developing severe medical conditions, doctors use a tool to identify patients who require extra care. (This tool is used only to supplement the doctor’s practice as a second opinion.) The TPR is designed to be equal for each demographic group.
C. Equal Accuracy
It is also possible to verify that the model is equally accurate for each group. In other words, the percentage of incorrect classifications (individuals who should be denied and denied and individuals who should be approved and approved) should be equal for each group. If the model is 98% accurate for one group of individuals, it should also be 98% accurate for other groups.
The approval process for a loan is based on a model used by the bank. As a result of the model, the bank avoids approving applicants that should be rejected (which is financially damaging to both the bank and the applicant) and does not leave applicants that should be approved (which would result in a failed opportunity for the applicant as well as a loss of revenue for the bank).
D. Group Unawareness
To make the model fairer to different gender groups, we can remove gender information. Similarly, we can release information regarding race and age.
One complication of implementing this approach in practice is that one must be cautious to identify and remove proxies for the group membership data. Using Zip codes instead of race in cities that are racially segregated. Thus, the ML application should also remove the zip code data when the race data is removed; otherwise, the application may still be able to infer a person’s race from the data. Moreover, unaware group fairness does not adequately address historical bias.
Business Use-Case Example
A confusion matrix will be used to illustrate the differences between the four types of fairness. This is a standard tool used to assess the performance of machine learning models. In the example below, the model is shown as being 80% accurate (eight out of ten people were correctly classified) and having an 83% true positive rate (five out of six “positives” were correctly classified).
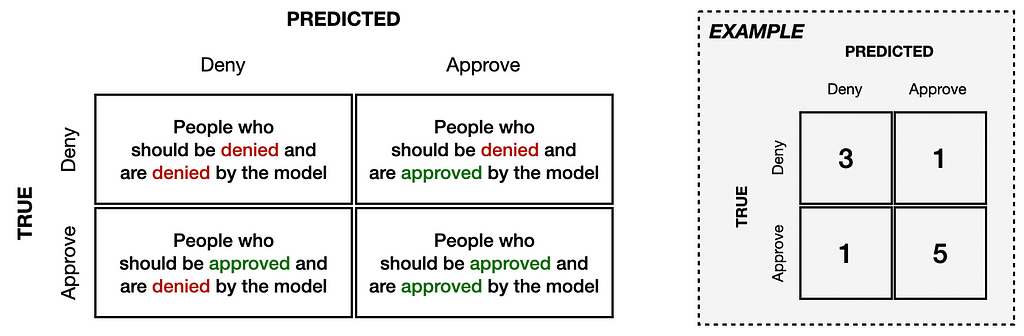
We can construct a different confusion matrix for each group to help understand how the model’s performance varies across groups. In this small example, we will assume that we have data on 20 individuals evenly divided between two groups (10 from Group A and ten from Group B).
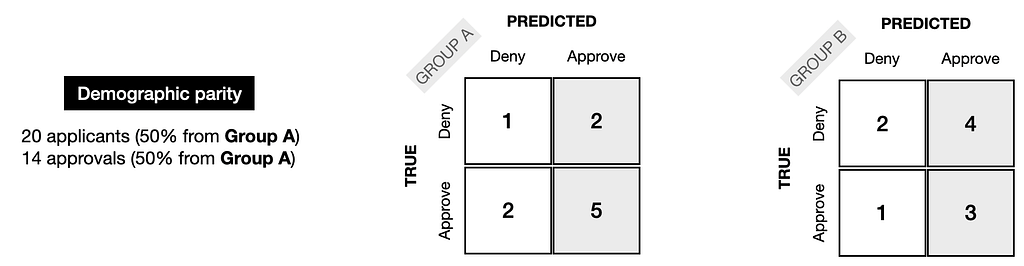
It is shown in the following image how the confusion matrixes would look if the model met demographic parity fairness requirements. The model considered ten people from each group (50% from Group A, 50% from Group B). The model also approved 14 people who were equally split between groups (50% from Group A and 50% from Group B).
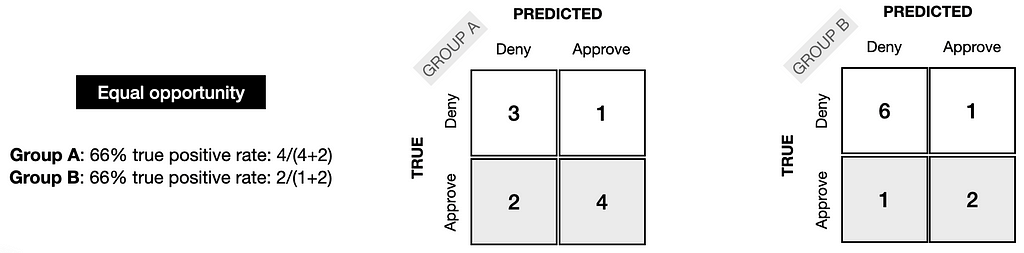
Accordingly, the TPR for each group should be the same; in the example below, it is 66% in each case.
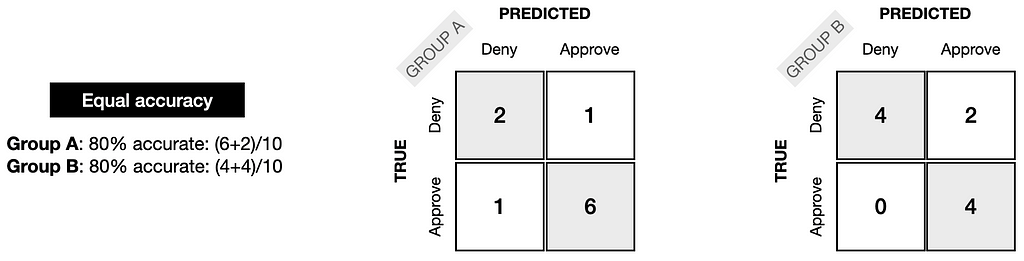
As a result, we can see how the confusion matrices might appear for equal accuracy and fairness. For each group, the model had an accuracy of 80%.
The confusion matrix cannot detect unaware group fairness, as it is concerned with removing information about group membership from the dataset rather than detecting it.
Consider these toy examples, and use them to establish your intuition for the differences between the different types of fairness. How does the model change if Group A has twice the number of applicants as Group B?
The examples do not satisfy more than one type of fairness; for example, demographic parity does not satisfy equal accuracy or equal opportunity. Please verify this now. In practice, optimizing a model for more than one type of fairness is impossible: learn more about this by exploring the Impossibility Theorem of Machine Fairness. If you can satisfy only one fairness criterion, which one should you choose? As with most ethical questions, the answer is not always straightforward, and selecting a measure should be a team effort.
Real-world projects will have much larger data sets. In this case, confusion matrices can still be helpful for analyzing model performance. However, it is essential to note that real-world models will not necessarily be able to satisfy every definition of fairness perfectly. Therefore, if “demographic parity” is selected as the fairness metric and a model is expected to choose 50% men, the final model may select something close to, but not exactly 50% (for example, 48% or 53%).
Why Model Cards?
A model card is a short document that contains vital information about a machine learning model. Model cards increase transparency by communicating information about trained models to a broad audience.
As part of this tutorial, you will learn which audiences to write a model card for and which sections a model card should contain. The following exercise will allow you to apply what you have learned to some real-world scenarios.
What’s a Model Cards?
While artificial intelligence systems are becoming increasingly important in all industries, few people clearly understand how they function. To inform people who use AI systems, those who are affected by AI systems, and those in other fields, AI researchers are exploring a variety of ways to communicate critical information about models.
In a 2019 paper, model cards were introduced as a means for teams to communicate critical information about their model to a broader audience, such as its intended uses, how it works, and how it performs in various situations.
A model card may be compared to a nutritional label on packaged foods.
General Implementation
It may be helpful to briefly review some examples of model cards before we proceed.
- Model cards for Salesforce
- GPT-3 model card from Open AI
- Examples of model cards from Google Cloud
Business Application
Model cards should balance providing important technical information and being easy to understand. When writing a model card, you should consider your audience: those groups of people who are most likely to read your model card. These groups will vary according to the purpose of the AI system.
Medical professionals, scientists, patients, researchers, policymakers, and developers of similar AI systems will likely read a model card that helps medical professionals interpret x-rays to better diagnose musculoskeletal injuries. Consequently, some knowledge of health care and artificial intelligence systems may be assumed in the model card.
Role of Model Card
Following the original paper, a model card should contain the following nine sections. Organizations may add, subtract, or rearrange sections according to their needs (and you may have noticed this in some of the examples above).
You are encouraged to review the two examples of model cards from the original paper as you read about each section. Please open each of the examples in a new window before continuing:
A. Model Details
- Include background information, such as developer and model version.
B. Intended Use
- What use cases are in scope?
- Who are your intended users?
- What use are cases out of scope?
C. Factors
- What factors affect the impact of the model? For example, the smiling detection model’s results vary by demographic factors like age, gender, or ethnicity, environmental factors like lighting or rain, and instrumentation like camera type.
D. Metrics
- What metrics are you using to measure the performance of the model? Why did you pick those metrics?
- For classification systems — in which the output is a class label — potential error types include false-positive rate, false-negative rate, false discovery rate, and false omission rate. The relative importance of each of these depends on the use case.
- For score-based analyses — in which the output is a score or price — consider reporting model performance across groups.
E. Evaluation Data
- Which datasets did you use to evaluate model performance? Provide the datasets if you can.
- Why did you choose these datasets for evaluation?
- Are the datasets representative of typical use cases, anticipated test cases, and/or challenging cases?
F. Quantitative Analyses
- How did the model perform on the metrics you chose? Break down performance by essential factors and their intersections. For example, in the smiling detection example, performance is broken down by age (e.g., young, old), gender (e.g., female, male), and then both (e.g., old-female, old-male, young-female, young-male).
G. Ethical Considerations
- Describe ethical considerations related to the model, such as sensitive data used to train the model, whether the model has implications for human life, health, or safety, how risk was mitigated, and what harms may be present in model usage.
Use-Case Applications
Since many organizations do not wish to reveal their processes, proprietary data, or trade secrets, it can be challenging to use detailed model cards. During such situations, the developer team should consider how model cards can be helpful and empowering without including sensitive information.
In addition to using FactSheets, some teams collect and log information about ML models in other formats.
Key Takeaways
I have attempted to explain the concept of Fair AI in three articles. The first step was understanding the importance of designing a Human-Centered Design AI system — AI Ethics (I). This approach to problem-solving is commonly used in the design, management, and engineering frameworks to develop solutions to problems by involving the human perspective throughout the process. Our next step was identifying and eliminating the BIAS from the Artificial Intelligence system — AI Ethics (II). This Netflix movie, Coded Bias, looks at today’s applications that are prone to bias. Lastly, we looked at the concept of categorizing the fairness of AI and how Model cards can be leveraged when designing a Fair AI system.
Statistics indicate that the AI market will reach $190 billion by 2025. By 2021, global expenditures on cognitive and AI systems will reach $57.6 billion, and 75% of enterprise applications will incorporate AI.
Lastly, if you like this article, drop me a follow for more relevant content. Your support motivates me to drive forward. For a new blog, or article alerts click subscribe. Also, feel free to connect with me on LinkedIn, and let’s be part of an engaging network.
Data Science Essentials — AI Ethics (III) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





