



Cross-Validation Types and When to Use It
Last Updated on January 7, 2023 by Editorial Team
Last Updated on April 22, 2022 by Editorial Team
Author(s): Parth Gohil
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A better way to test your models
Overview
Building machine learning models is a great process that includes several steps
- Collection of data
- Data Preparation & Preprocessing
- Expletory Data Analysis
- Feature Engineering and Selection
- Model Building and Evaluation
- Cross-Validation is one of the most important parts of Model Building and Evaluation.
- Before experimenting with Cross-Validation, let’s see what it is and why we should worry about using it.
Why Cross Validation?
- Let’s say we have 10000 rows ( sample ) dataset and We want to build a model with it. A simple way would be doing a train test split of data and making a model with it. right??
- But when we do train test split, we assign random_state= some value. It can be anything 0,42,69,100. And every time you will change the value of random_state you will get a different train and test dataset ( feel free to check it out but you can take my words ).
- And you will get different accuracy performance on each different split so how can you be sure about choosing the right random_state when each has different results.
- This is where Cross Validation comes in handy, We use Cross-Validation to make different splits of our data to train and test our model and we average the accuracy overall this iteration to see the overall performance of our model.
What is Cross-Validation?
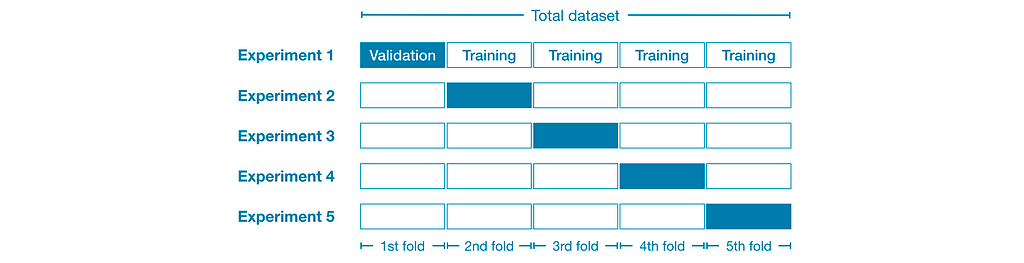
- We divide our dataset into different chunks of data. If we have 10000 rows and want to have 5 iterations. We can have the first 8000 rows as train data and the last 2000 rows as test data ( assume an 80/20 split ).
- In the next iteration, we can have the first 6000 and last 2000 rows as train data and the rest of the 2000 rows as test data.
- We make different 5 holds of data that have different train and test data by doing the same process.
- Here is a great visualization of Cross-Validation. ( Source: Kaggle )
Types of Cross-Validation
Mainly There are 5 types of Cross-Validation
- Hold Out Validation Approach
- Leave one out Cross-Validation
- K Fold Cross-Validation
- Stratified K Fold Cross-Validation
- Repeated Random Test Train Splits
- Hold out validation approach is our regular train test split method in which we hold out some portion of data for testing purposes.
- We won’t discuss Leave one out cross-validation and repeated random test train splits approach here because they are hardly being used and you might not need them for most of your projects.
- I will use Breast Cancer Wisconsin dataset here for an explanation. I won’t go into detail about making great feature engineering steps because the main objective of this article is cross-validation.
Data Preparation
- Now we can build our model with this data and use different cross-validation techniques
Hold Out Validation Approach
- The result of this model is 0.9239766081871345
- This is our simple train test split in which we hold out some portion of our data for validation and use the rest for the training model.
K Fold Cross-Validation
- Scores =[0.9122807 0.92982456 0.89473684 0.98245614 0.98245614 0.98245614, 0.96491228 0.96491228 0.96491228 1.]
- Average Score = 0.9578947368421054
- In K Fold Cross Validation we make k different splits of our data. choose a portion of our kth fold for validation and use the rest of the data for training.
- Repeat this k time by splitting our data randomly each time resulting in a new train and test dataset.
- This will give us the overall performance of our model in different scenarios.
Stratified K Fold Cross-Validation
- We use this approach when working with an imbalanced dataset.
- This will give different splits which will preserve percentages of classes so we can have a proper dataset to train and test our model.
- Scores =[0.98245614 0.89473684 0.94736842 0.94736842 0.98245614 0.98245614, 0.94736842 0.98245614 0.94736842 1.
- Average Score= 0.9614035087719298
- More in depth knowledge about it check out this :
Stratified K Fold Cross Validation – GeeksforGeeks
Conclusion
- If you want to use cross-validation then go with K fold cross-validation and if your dataset is imbalanced and you haven’t balanced it beforehand then you can go with Stratified K fold cross-validation.
- There are other ways of doing cross-validation obviously but those mentioned here are the most used ones in most problems.
- I hope you liked this article, If you have anything to add or want to give feedback please do it because it will help me and others a lot to improve.
Cross-Validation Types and When to Use It was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

