



CodeQueries: Answering Semantic Queries Over Code
Author(s): Surya Prakash Sahu
Originally published on Towards AI.
While working on a project, developers come across queries related to code correctness, security, maintainability, or code readability. Various existing tools can help answer most of those queries; however, they fall short with queries requiring analysis of semantic aspects of code. Let’s understand what a “semantic query over code” is through an example.
In Python, when a class subclasses multiple base classes, attribute lookup is performed from left to right amongst the base classes following a method called “method resolution order.”¹ This means, in the code example, theacceptConnection function of ThreadingMixin class will effectively override the acceptConnection function of TCPServer class in the base class of ThreadedTCPServer. Depending on the implementation objective, such code behavior may not be desirable, and a developer may need to locate similar implementations to investigate further. This query requires an understanding of inheritance relations between classes; similarly, other queries might require an understanding of other semantic aspects of code.
Static code analysis tools like linters, formatters, etc, can not answer the semantic queries; on the other hand, any potential dynamic code analysis solution will require the code to be executed. Few static analysis tools store the relational representation of the code base and evaluate a query (written in a specific query language) on the code base, similar to how a database query is evaluated by a database engine. Such tools can be used to answer semantic queries; however, some concerns are associated with using these tools. Such a tool will –
- have a setup cost — the database needs to be recreated with every code change,
- fail to analyze code with syntax errors,
- require both programming language and query language expertise.
Hence, we need a better tool.
ML enters the picture …

Recent advances show promise for neural program analyses around complex concepts such as program invariants, inter-procedural properties, and even evidence of deeper semantic meaning. AI code assistants and tools, such as ChatGPT, are increasingly being adopted by developers to understand and utilize such concepts during code development. Therefore, it is logical to question whether an ML system can effectively answer such semantic queries.
An answer to these semantic queries should identify code spans constituting the answer (e.g., the declaration of the subclass in the example) as well as supporting-facts (e.g., the definitions of the conflicting attributes in the example). However, existing datasets for answering queries over source code either have the code context restricted to functions or deal with comparatively easier problems of answering template-based questions. These datasets are not suitable for the task of answering semantic queries over source code.
CodeQueries Dataset
In this work, we introduce a labeled dataset, called CodeQueries, of semantic queries over Python code. Compared to the existing datasets, in CodeQueries, the queries are about code semantics, the context is file level, and the answers are code spans. We curate the dataset based on queries supported by a widely used static analysis tool, CodeQL, and include both positive and negative examples, and queries requiring single-hop and multi-hop reasoning.
CodeQueries has 52 public CodeQL queries python source code files from a common corpus³. Among the 52 queries, 15 require multi-hop reasoning, and 37 require single-hop reasoning. “Conflicting attributes in the base class” is a multi-hop query; for instance, the demonstrated example requires multi-hop reasoning across three classes. Single-hop queries like “Nested loops with the same variable” can be answered from the surrounding code block. The files containing code spans that satisfy the query definition constitute the positive examples for the query. Naively, any code on which a query does not return a span could be viewed as a negative example; for instance, in the example of the “Conflicting attributes in the base class” query, it would be trivial to answer that there are no conflicting attributes if the code does not contain classes. Therefore, negative examples with plausible answers are derived with modified CodeQL queries.
The dataset is released on the HuggingFace platform with Apache-2.0 a license. Each data instance has the following details —
- query_name (query name to uniquely identify the query)
- code_file_path (source file path in ETH Py150 corpus)
- context_blocks (code blocks as context with metadata)
- answer_spans (answer spans with metadata)
- supporting_fact_spans (supporting-fact spans with metadata)
- example_type (1(positive)) or 0(negative)) example type)
- single_hop (True or False - for query type)
- subtokenized_input_sequence (example subtokens from CuBERT vocabulary)
- label_sequence (example subtoken labels)
- relevance_label (0 (not relevant) or 1 (relevant) - relevance label of a block)
To keep the article focused on the essentials, I am omitting the details of data preparation. Please refer to the paper or comment for additional information.
If you are eager to try out the dataset, here is the starter code.
So, what did we find out?!
With prompting strategies, the LLM could identify correct spans in positive examples for simple queries like “Flask app is run in debug mode” but achieved no exact match on complex queries like “Inconsistent equality and hashing.” It faces similar problems with negative examples. Some of these failure cases are fixed with few-shot prompting where explicit spans of positive/negative examples in the prompt provide additional information about the intent and differences between positive/negative examples.
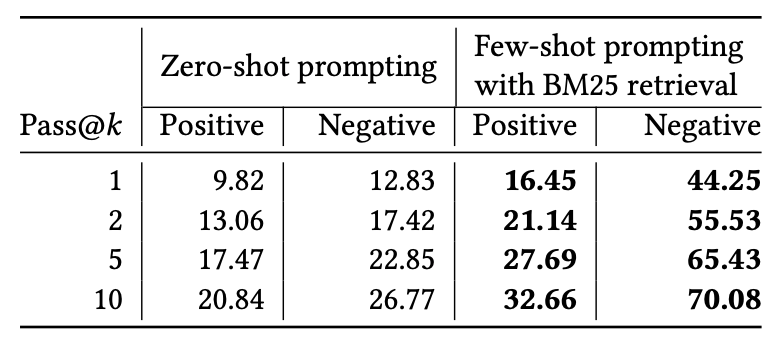

To evaluate the task with a more custom model, we reformulate the task as a problem of classifying code tokens. Let {𝐵, 𝐼,𝑂} respectively indicate Begin, Inside, and Outside labels; an answer span is represented by a sequence of labels such that the first token of the answer span is labeled by a 𝐵 and all the other tokens in the span are labeled by 𝐼’s. We use an analogous encoding for the supporting-fact spans, but we use the 𝐹 label instead of 𝐵 to distinguish facts from answers. Any token not belonging to a span is labeled by an 𝑂. We thus represent multiple answer or supporting-fact spans by a single sequence over {𝐵, 𝐼,𝑂, 𝐹 } labels. We call this the span prediction problem.

We found that not all code is relevant for answering a given query. Additionally, in many cases, the entire file contents do not fit in the input to these custom models. Hence, we programmatically identify the relevant code blocks and use a two-step procedure to deal with the problem of scaling to large-sized code. First, a relevance classifier is applied to every block in the given code, and code blocks that are likely to be relevant for answering a given query are selected. In the second step, the span prediction model is applied with the set of selected code blocks to predict answer and supporting-fact spans.
Additionally, to simulate and contrast the practical setting in which only a few labeled examples are available with the ideal setting of having sufficient data, we train two variants of relevant classifier and span classifier models: 1) one on all files in the training split and 2) another on sampled 20 files. With the two-step procedure, the results and observations were as follows –

For some queries like “Imprecise assert,” a single file may contain multiple candidate answer spans, e.g., multiple assert statements. With limited training, the relevance classifier had a low recall, missing out on some of the relevant candidates. Training with more data allows the relevance classifier to avoid considering irrelevant code blocks as relevant, which can be observed in the significant increase in precision score. Most of the code blocks in a file would be irrelevant for single-hop queries. Training with more data resulted in a significant boost (≥ 10%) in accuracy score for 15 single-hop queries. For some queries, such as “Module is imported with ‘import’ and ‘import from’”, there is less ambiguity in relevant versus irrelevant blocks, and those queries did not benefit much from larger training data.
In addition to strict metrics like exact match (EM), we also considered other relatively lenient metrics, such as BLEU, for evaluation, but our observations remain consistent. We find that these models achieve limited success on CodeQueries.
CodeQueries is thus a challenging dataset to test the ability of neural models, to understand code semantics, in the extractive question-answering setting.
This work is appearing in ACM ISEC, 24. The code, data, and unabridged paper version are publicly available for reference. The code and data are released under Apache-2.0 license.
All the images without source declaration are taken from the paper.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

