



Clash Royale API: Looping Query for Data Collection
Last Updated on July 20, 2023 by Editorial Team
Author(s): Michelangiolo Mazzeschi
Originally published on Towards AI.
Data Science
A few days ago I had the idea of applying factor analysis to the decks of the Clash Royale players in order to classify them into hierarchies. Unfortunately, I realized that I could not find any related data online, and none of the open-source datasets I found had the information I was searching for: therefore, I decided to use an API to download raw data from the source.
You can use this tutorial as a guide to orient you in the use of APIs and data collection from online databases. In a further tutorial, I will perform a factor analysis on the results to identify hierarchical structures in the collected data.
Full code available on my GitHub repo.
Downloading Clash Royale matches in a JSON file
Clash Royale is a smartphone game that allows each player to build a deck of 8 different cards to battle against other players. Through the website https://developer.clashroyale.com/#/ I can have access to the last 25 matches a player has fought. I want to collect and store the data of every deck played by top players in the last 25 battles so that I can later use the data to train an AI. For doing this, I will need to:
1. Register and get an API token on developer.clashroyale.com
2. Establish a connection to the dataset through an API
3. Download a specific set of data (I cannot download everything, I need to be specific on what I want to collect)
4. Iterate through each .json I have downloaded, extract the features I want from the .json file and store them
5. Make all the stored data with identical shape, then create a DataFrame
6. Export the DataFrame
Practical Issues
Realistically, there are so many limitations we encounter when downloading data using APIs:
- There is a time limit: we can download small batches of data in relation to time
This problem makes it very challenging to work with this database. I know that for my AI I need thousands of matches to perform any kind of analysis, however, I can download up to 25 matches every 4 minutes, 15 of them probably valid (I only want to store ‘Ladder’ games, discard all the others): this sets a download limit of 225 matches per hour, given that the algorithm is fully running and every request is valid (you would not believe how many issues happen even when performing a valid request).
Through this article I will guide you in building an algorithm capable of periodically connecting to an online database to extract information, collecting them into a DataFrame that you can export as a .csv file.
- We need to know what data to search for
In this specific case, I will need to input the tags of the players that have played the matches I want to collect data from. I will choose 7 of the top players that play one archetype called the X-bow (the top player using this archetype is called LemonTree68, his name will be echoed through time…). As already mentioned, I only want to save games played in ‘Ladder’, so I will need to get rid of all the others: from 25 original games, I will likely be able to store only 15.
- We need to process the .json files
The API will provide us with a list of dictionaries, each one representing a single match. However, we cannot just convert it to a .csv: we need to identify the features we want to save and then store them into a list for every .json dictionary we downloaded: we need to create a personalized algorithm for this.
If you are aiming to a more professional approach to Data Science, you will need to get used to downloading data directly from specific websites using APIs, rather than finding it already structured in some open-source repository.
Connecting to the Database
Let us begin going through the list of steps: first of all, I have registered in the website above and asked for a Developer Key linked to my IP address:
When I will use this key in my code, if the query (request) is proper and the IP address corresponds, the database will authorize me, and allow me to download data. For now, I will set up a connection with the database:
import requests
import json
from urllib.parse import quote
import timeheaders = {
'Accept': 'application/json',
'authorization': 'Bearer <eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzUxMiIsImtpZCI6IjI4YTMxOGY3LTAwMDAtYTFlYi03ZmExLTJjNzQzM2M2Y2NhNSJ9.eyJpc3MiOiJzdXBlcmNlbGwiLCJhdWQiOiJzdXBlcmNlbGw6Z2FtZWFwaSIsImp0aSI6ImFkODhlY2NjLTM2YjUtNDUwZi1hODI0LTY3ZWIyZjc0MzY5YSIsImlhdCI6MTU4OTQ4MzUyMiwic3ViIjoiZGV2ZWxvcGVyLzJkZGRhOGI4LTEyY2YtMzQzNy05N2FjLTQxNTBhMTMzNGI1MiIsInNjb3BlcyI6WyJyb3lhbGUiXSwibGltaXRzIjpbeyJ0aWVyIjoiZGV2ZWxvcGVyL3NpbHZlciIsInR5cGUiOiJ0aHJvdHRsaW5nIn0seyJjaWRycyI6WyIxMDQuMTU1LjIxOC4xNzgiXSwidHlwZSI6ImNsaWVudCJ9XX0.PdB9ycHIcIkKRs246zKLNdRJleUiXV9u-szeMj9qm02Rz-wS4OkkfOaafWRMXos_LVLmZe1VeUBCpr6fIiMvRw>'
}
Preparing the Request
As mentioned before, I need to be very specific on which data I want to download. I will download the most recent matches of 7 of the top X-bow players (25 matches per player) in the world. Therefore, I will store the following tags.
#has to be run only once, otherwise the dataset we are going to create will reset
battles_list = list()tag_list = [
'#929URQCL8', '#RC2JGVVG', '#R9QC0QUQ',
'#9JPL980Y2', '#YU8R0VPP', '#RPURG9GR',
'#2GYRQJRR8']tag_list_scavenged = list()
columns = [
'gamemode', 'battletime',
'p1.name', 'p2.name',
'p1.crowns', 'p2.crowns',
'p1.card_1', 'p1.card_2', 'p1.card_3', 'p1.card_4',
'p1.card_5','p1.card_6', 'p1.card_7', 'p1.card_8',
'p2.card_1', 'p2.card_2', 'p2.card_3', 'p2.card_4',
'p2.card_5', 'p2.card_6', 'p2.card_7', 'p2.card_8'
]
Because I already looked at the data, I will also save the headers of the features I will want to apply to the last version of the .csv dataset we are going to create: essentially the game mode (we will use this information to discard all games not played in ‘Ladder’), the battle time and the name of the two players (in order to discard duplicates), the number of crowns to figure our who won the match, and finally the deck chosen by each player.
For each label forward a query
I will now create a function that will allow me to perform a GET request to the database: for each player tag I will download a .json file, make the proper modifications, and end up with a list with 25 elements: each element contains only the data I want as the summary of a battle.
import pandas as pd
from pandas.io.json import json_normalizedef p1_dataset(player_tag):
df_list_complete = list() #downloading json
r = requests.get('https://api.clashroyale.com/v1/players/'+player_tag+'/battlelog', headers=headers)
#a contains 25 dicts in a list
try:
a = r.json() ###IN CASE OF UNRESOLVED ERROR: EXIT
except Exception as e:
return 1 ###IN CASE OF FAILED REQUEST: EXIT
if a == {'reason': 'accessDenied', 'message': 'Invalid authorization'}:
return 0
In case the dataset returns error, the functions exits returning 0 or 1.
Structuring each JSON into a DataFrame
#for each of the 25 dicts in the list
for n in a:
Download all data into variables
The biggest issue so far is structuring each .json. As you can see from what I have downloaded, it is a set of dictionaries withing dictionaries. What I will do, is using pandas.io.json.json_normalize, this tool will allow me to turn a dictionary contained in one cell into another DataFrame.

Essentially, I will be dealing with several nested dictionaries:

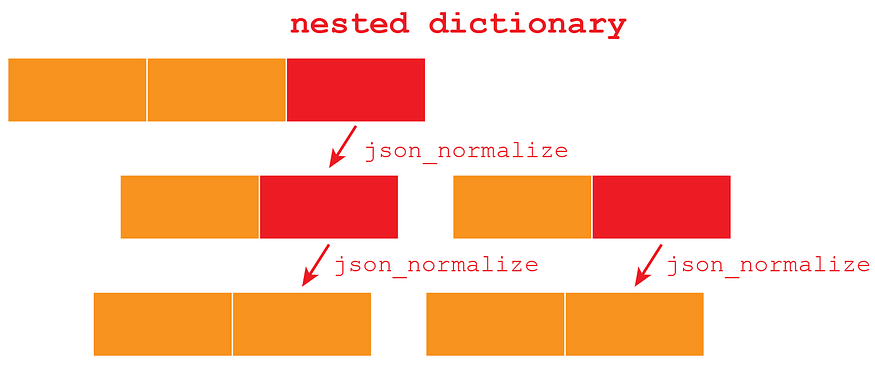
df1 = json_normalize(n)
df_opponent = json_normalize(df1['opponent'][0]) df_opponent_name = df_opponent['name'][0]
df_opponent_crowns = df_opponent['crowns'][0]
df_opponent_cards = json_normalize(df_opponent['cards'][0])
df_opponent_cards = df_opponent_cards['name'].tolist() df_team = json_normalize(df1['team'][0])
df_team_name = df_team['name'][0]
df_team_crowns = df_team['crowns'][0]
df_team_cards = json_normalize(df_team['cards'][0])
df_team_cards = df_team_cards['name'].tolist() battletime = df1['battleTime'][0]
gamemode = df1['gameMode.name'][0]
Place all the variables in a list
I will store each element of a DataFrame in a variable, while I will need to expand the nested dictionaries to find out which other variables they contain. In the end, I will end up with a list of variables.

df_list = list()
#append individual variables
df_list = [
gamemode,
battletime,
df_team_name,
df_opponent_name,
df_team_crowns,
df_opponent_crowns
]
#append lists
for team_card_n in df_team_cards:
df_list.append(team_card_n)
for opponent_card_n in df_opponent_cards:
df_list.append(opponent_card_n)
Append the list to our DataFrame
df_list_complete.append(df_list)
return df_list_complete
Looping queries
We have created a function that lets us download and store correctly 25 matches per player tag. Now we have to activate it in a way that, given a list of 7 players tag, the algorithm won’t stop until it has downloaded all the data (175 rows). In order to do so, we will make it loop until it has completed its task:
first_round = True
#looping through queries until all our requests are filled
while len(tag_list_scavenged) < len(tag_list):
#we cannot substitute existing tags
for m in tag_list:
if m in tag_list_scavenged:
print(‘Tag already in list:’, m)
else:
#the first round skip the waiting
if first_round == True:
first_round = False
else:
#wait 240 seconds
time.sleep(240)
print('timer_ended') #GET request
csv = p1_dataset(quote(m))#manage errors
if csv == 0 or csv == []:
print('unable to download:', m)
pass
elif csv == 1:
print('unable to download due error:', m)
pass
else:
print(‘scavenged:’, m)
csv = pd.DataFrame(csv)
#we won't ne editing the columns until the end, here is only a reference
#csv.columns = columns
#we add the csv to the dataset
battles_list.append(csv)
#we save the tag so that the algorithm will not repeat the request for this tag
tag_list_scavenged.append(m)
Dealing with errors
The biggest risk to the functioning of our algorithm errors, simply because they force the algorithm to stop and require manual reactivation. In order to prevent this from happening, in case of error or empty dataset (a case that can lead to an error) I will return a condition (0 or 1) that the algorithm will ignore in order to keep its loop going. You can do this in many other ways, I chose this one because I found it to be the most comfortable. Common errors:
- The downloaded file is empty and results in [], causing JSONDecodeError
- {‘reason’: ‘accessDenied’, ‘message’: ‘Invalid authorization’}
…after 28 minutes
timer_ended
scavenged: #RPURG9GR
timer_ended
scavenged: #2GYRQJRR8
...
In case of errors, the algorithm will signal them but it will keep working and performing requests. If we check the tag_list_scavenged:
tag_list_scavenged
[‘#929URQCL8’,
‘#RC2JGVVG’,
‘#R9QC0QUQ’,
‘#9JPL980Y2’,
‘#YU8R0VPP’,
‘#RPURG9GR’,
‘#2GYRQJRR8’]
Above, we have created a dataset containing the battles of all the players with the tags above using a single algorithm rather than several manual requests. All the matches have been stored in battles_list.
#before editing further, we make a copy
q = battles_list.copy()
***If for any reason the algorithm would stop, because operating on a Jupiter Notebook the variables will be temporarily stored: any successful request won’t be lost
Editing the battles DataFrame
We now have to discard all the games that are not classified as ‘Ladder’:
#we only conserve ladder plays
for i in range(0, len(q)):
#lista con i nomi delle colonne exra che volgiamo eliminare
list1 = [22 + x for x in range(0, q[i].shape[1]-22)]
print(list1)
#only maintain ladder games
q[i] = q[i].loc[q[i][0] == ‘Ladder’]
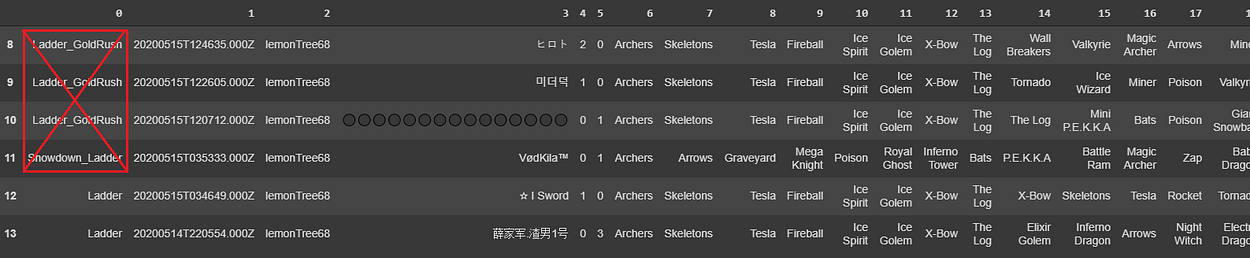
Now there is another problem: the lists we have been storing do have not equal length: because there is the possibility of playing a game mode that allows decks of 18 cards, some lists are longer than the others. Because we have been storing them as a unique DataFrame, we will need to delete all the extra columns:
#deleting all the extra columns
if q[i].shape[1] > 22:
#if there are no extra columns, do not even bother, otherwise error
q[i] = q[i].drop(list1, axis=1)
Editing the final DataFrame
CRL = pd.DataFrame()
CRL = pd.concat(q[0:len(q)], axis=0)
#rinominiamo l’intero dataset alla fine
CRL.columns = columns
CRL
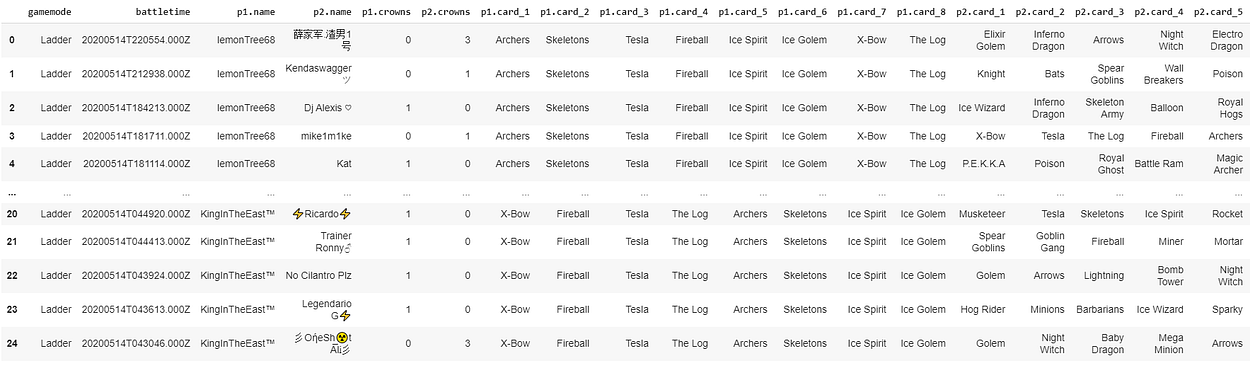
Export to CSV
CRL.to_csv(‘CRL.csv’)
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



