



Can we build an AI model to understand what gangs are talking about and prevent gang violence?
Last Updated on July 20, 2023 by Editorial Team
Author(s): Rudradeb Mitra
Originally published on Towards AI.
Preventing Gang Violence by analyzing Tweets
“Some believe that bolstering school security will deter violence, but this reactionary measure only addresses part of the problem. Instead, we must identify threats, mitigate risk, and protect children and staff before an act of violence occurs.” — Jeniffer Peters, Founder of Voice4Impact
(Include contributions from Yang Gao, Tony Tonev, and Arafat Bin Hossain)
Chicago is considered the most gang-infested city in the United States, with a population of over 100,000 active members from nearly 60 factions. Gang warfare and retaliation are common in Chicago. In 2020 Chicago has seen a 43% rise in killings so far compared to 2019.
Can we use AI to reduce gang violence
It was noticed that gangs often use twitter to communicate with fellow gang members as well as threat other gang members. Gang language is a mixture of icons and some gang terms.

The team split the work into two parts:
- Implement a machine-learning algorithm to understand gang language and detect threatening tweets related to gang violence.
- Find co-relation between threatening tweets and actual gang violence.
Part 1: Detecting violent gang language and influential members
The goal was to classify tweets as threatening or non-threatening so that the threatening ones can be routed to intervention specialists who then decides what action to take.
Step 1: Labeling tweets collaboratively
First, a tool was created to label tweets faster and train the machine learning model. We were only provided the raw tweets. Searching the web, we found LightTag, which is a product designed for exactly this, but it is a paid product once you exceed the comically low number of free labels.
We needed a simpler solution that does everything we need, and nothing else. So, we turned to a trusted old friend: Google Spreadsheets. A custom Google Spreadsheet was made (the template publicly available here). It features a scoreboard, so labelers get credit for their contribution, and a mechanism to have at least two people label each tweet to ensure the quality of labels.
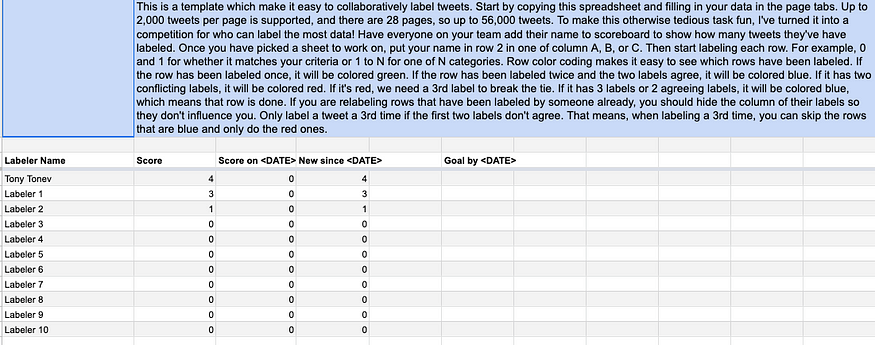
To ensure the quality of our labels, we decided we need at least two labels on every tweet, and if they are not the same, a third label would be required to break the tie. Row color-coding makes it easy to see which rows are finished. If the row has been labeled once, it will be colored green. If the row has been labeled twice and the two labels do not agree, it will be colored red. Also on the scoreboard page, is a count of how many tweets are labeled once, labeled twice with conflicting labels, and finished on each page.
Step 2: Sentiment analysis (with probability value) of tweets being violent
The sentiment analysis team built a machine learning model to predict whether the tweets are threatening or non-threatening. But first, we needed to address the challenges of an imbalanced dataset where over 90% of the tweet feed was non-threatening, and the scarcity small size of the labeled dataset. We tested multiple techniques, including loss functions specifically designed for imbalanced datasets, undersampling, transfer learning from existing word embeddings algorithms, and ensemble models. We then combined the reservoir of violent signal words to come up with probability value (the probability that a tweet is more prone to using violent words) against each tweet.
Step 3: Detect influential members in the twitter gang network
Next, we wanted to identify the influential members of the network. A network analysis resulted in a directed graph, and by using the Girvan Newmann algorithm, the communities in the networks could also be detected. Using PageRank values of each node, the influential members were identified.
5 steps to build an effective network analysis of tweets
- Using python’s networkX, a graph using the mentions and authors of the tweets were created
The nodes represent mentions in the tweet/author of a tweet. Edge A →B means B was mentioned in the tweet posted by A.
2. Thousands of tweets were used to create a directed graph, and to use the Girvan Newmann algorithm, the communities in the networks were detected. Also, using the PageRank values of each node, the influential members in the network could be identified. This value is not crucial to the network analysis but can be useful if one tries to track any gang member who is influential in the network.
3. The members in the communities are either authors or mentions. So, the tweets were then tagged with the community number based on the mention or author names.
4. The total number of signal keywords in all the communities was calculated, and so was the total number of signal words for individual communities.
5. The final result was a dataset of tweets that had the community tag and probability of using violent words — based on usage of signal words within the community relative to all the communities. For example, In the picture below, members from Community 1 who are authors or mentions in the tweets are more likely to be inclined towards using violent keywords. So, the tweets which contain authors/mentions from this community are contextually more violent.
Also, the network analysis can give an insight into which members are more influentials within the community. One can get a notion by looking at the PageRank values of the members of the community. The greater the PageRank, the more influential a member, is.
Part 2: Correlation between actual violence and tweets
Next, we wanted to understand if there is any co-relation between actually Crimes and mention of ‘Gun’ in a threatening tweet.
Below is the correlation between the two metrics on the same day, 1-day, and 2-day shift.

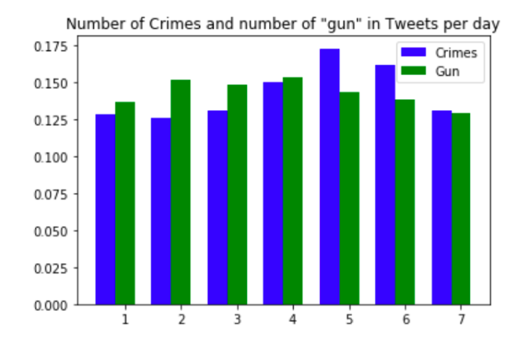
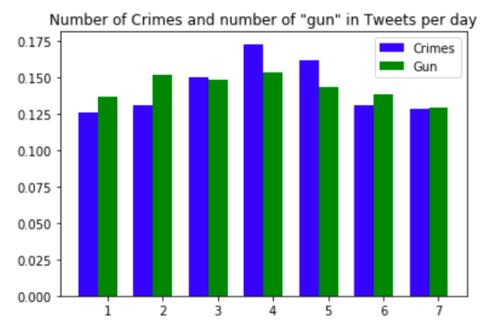
Through this analysis, we can see that there is a correlation between the number of crimes and the use of a gun in threatening tweets with a 2-day shift. This can be very useful for authorities to prevent gang violence.
Omdena
This project was done via Omdena — an innovation platform for building AI solutions to real-world problems through the power of bottom-up collaboration.
I would like to thank Jennifer Peters, Phil Andrew, and Jim Connor for their expert advice.
Here are the collaborators who contributed actively on this project (in alphabetical order):
Alexandr Laskorunsky, Arafat Bin Hossain, Arvin Febriyan, Erum, Emile Bondzie-Arthur, Hitesh Gautam, Koena Monyai, Ofentse Rice, Rafael Echeverria, Ramon Ontiveros, Sakthisree Venkatesan, Samir Sheriff, Keng Ying, Tony Tonev, Yemissi Kifouly, Memunat Ajoke Ibrahim, Sai Praveen, Yang Gao
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

