



BLUPs and shrinkage in Mixed Models
Last Updated on July 26, 2023 by Editorial Team
Author(s): Dr. Marc Jacobs
Originally published on Towards AI.
Data Visualization
Using SAS
Mixed Models are a great tool for estimating variance components and using those estimates to provide predictions. The predictions coming from Mixed Models are called Best Linear Unbiased Prediction(BLUP), and they are called that way because they include the fixed and random effects of the model to provide a prediction.
By including both fixed and random effects, Mixed Models allow a technique called ‘shrinkage’, or partial-pooling, which limits the potential for overfitting. In short, when a Mixed Model is made, the fixed effect is estimated across all observations, but the random part is done per level.
So, if you have observations across time for 100 people, you could ask the model to estimate different intercepts and different slopes (trajectories) for each of those 100 people. Now, you have multiple modeling options:
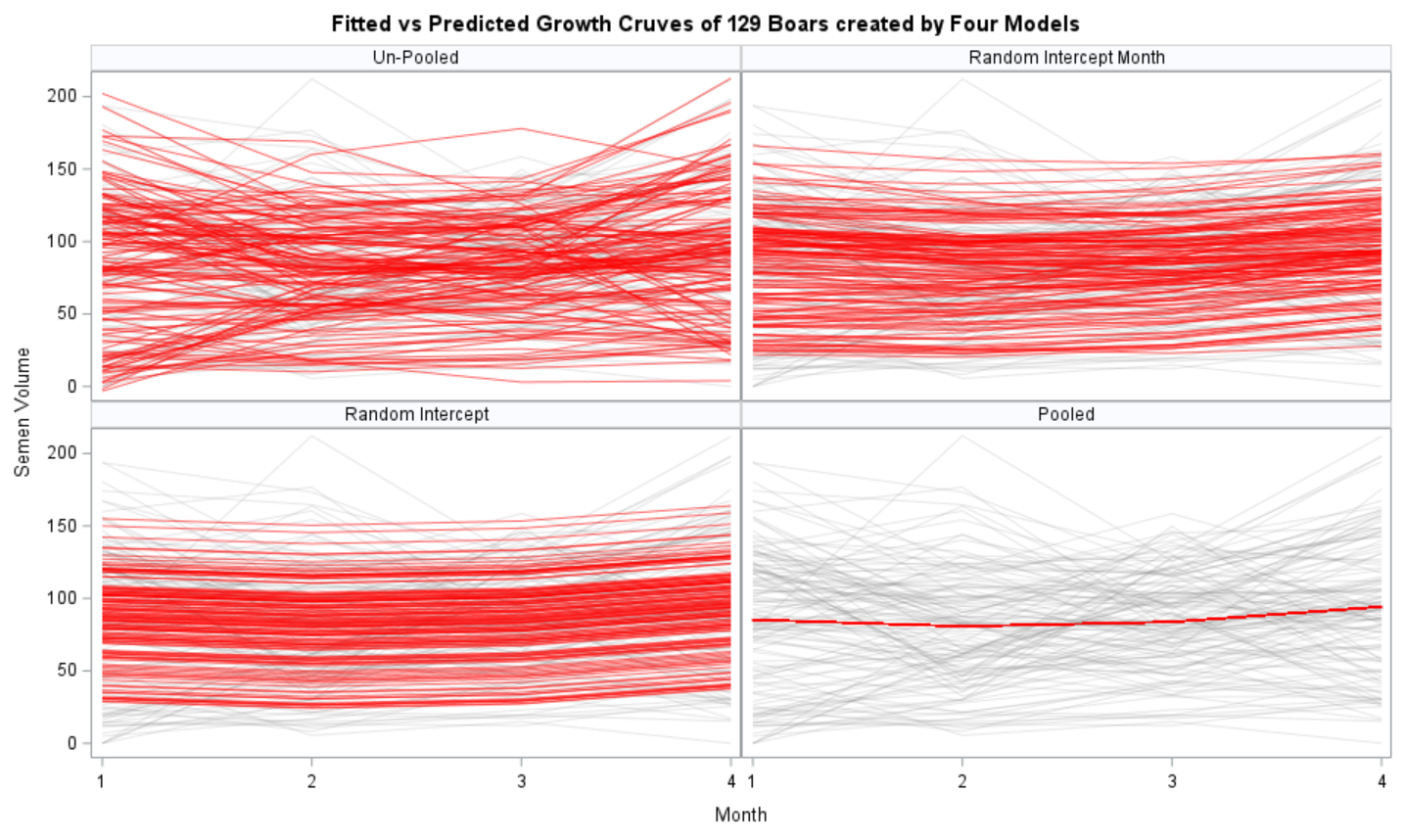
- You fit a linear regression model on all the observations. This is called a pooled model since no people-level trajectories are estimated. Just one single intercept and one single slope.
- You fit a linear regression model on each observation, separately. Now, you have estimated 100 intercepts and 100 slopes, separately, per person. This is the equivalent of splitting the dataset up in 100 parts. None of the people know the other 99 exist.
- You fit a mixed model. The fixed intercept and slope effect are global, but you also estimate a person-dependent intercept and slope. To realize such feet, there needs to be enough variance in both the start and the trajectory of the curve. The way the random parts are estimated is called partial-pooling since the form follows a Normal distribution[0, variance]. Here, each specific random effect is determined by the population effect and person-specific deviance. To counter overfitting, the estimates furthest away from the population average are shrunk back the most to zero, since we believe they are more like anomalies. If we would not do so, the variance estimate of the random effect would explode.
Now, in this example, using SAS, I will show you how I compared pooled, no-pooled, and various partially pooled models on a dataset containing the semen volume of 129 boars measured at 4 time points.
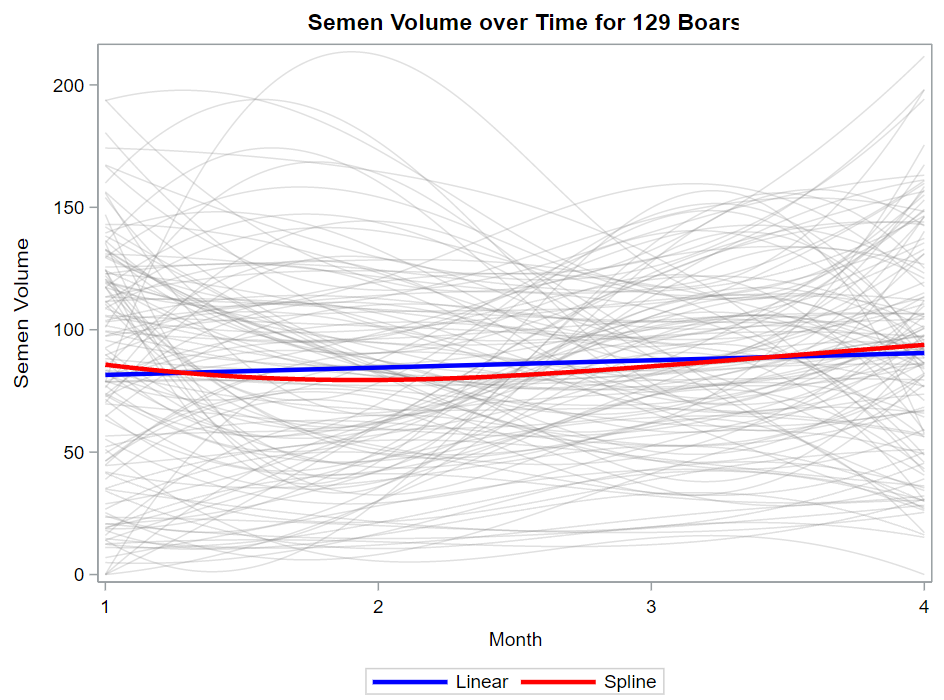
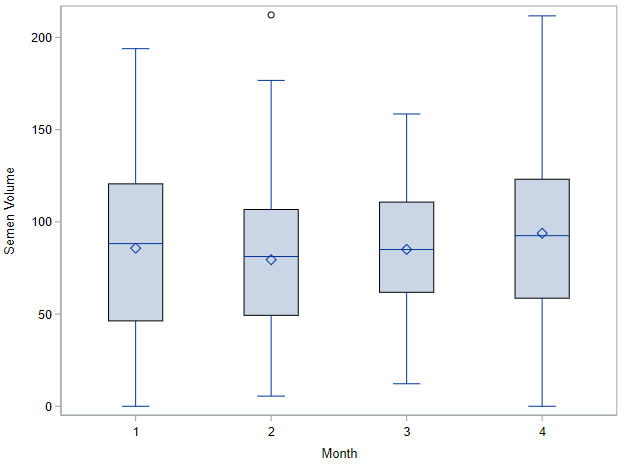

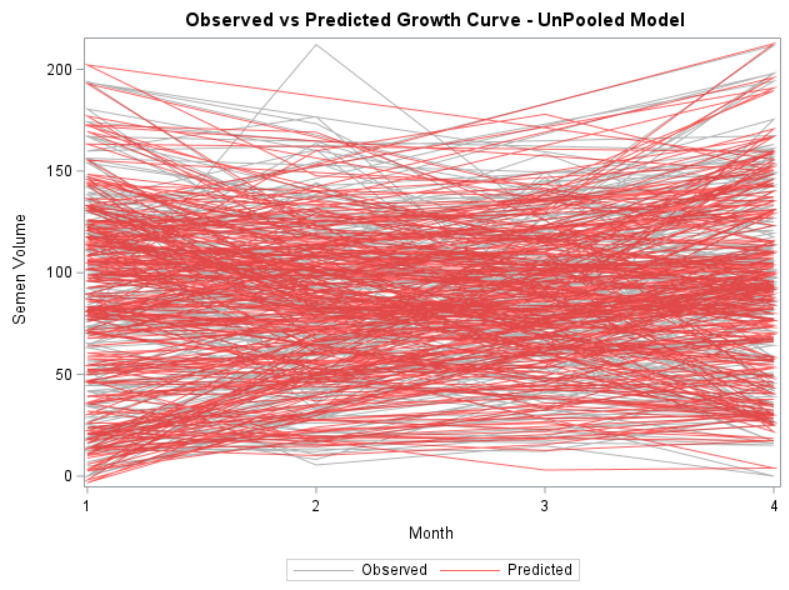

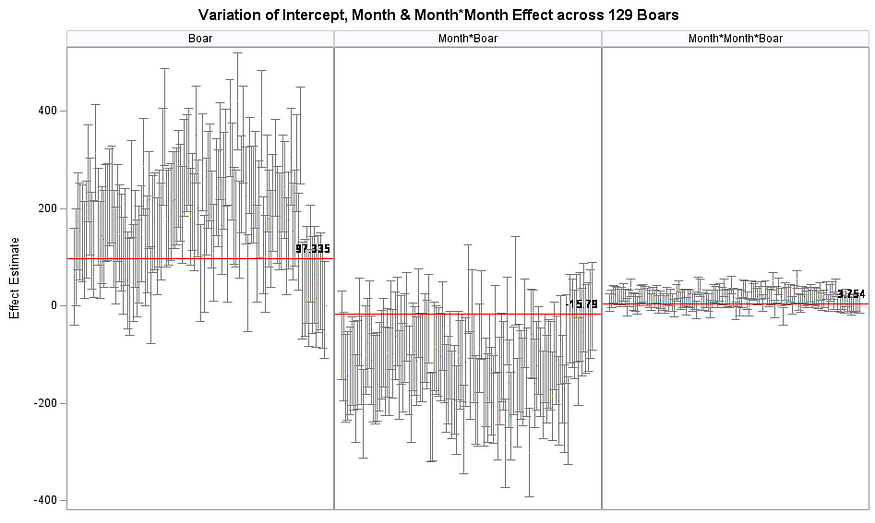
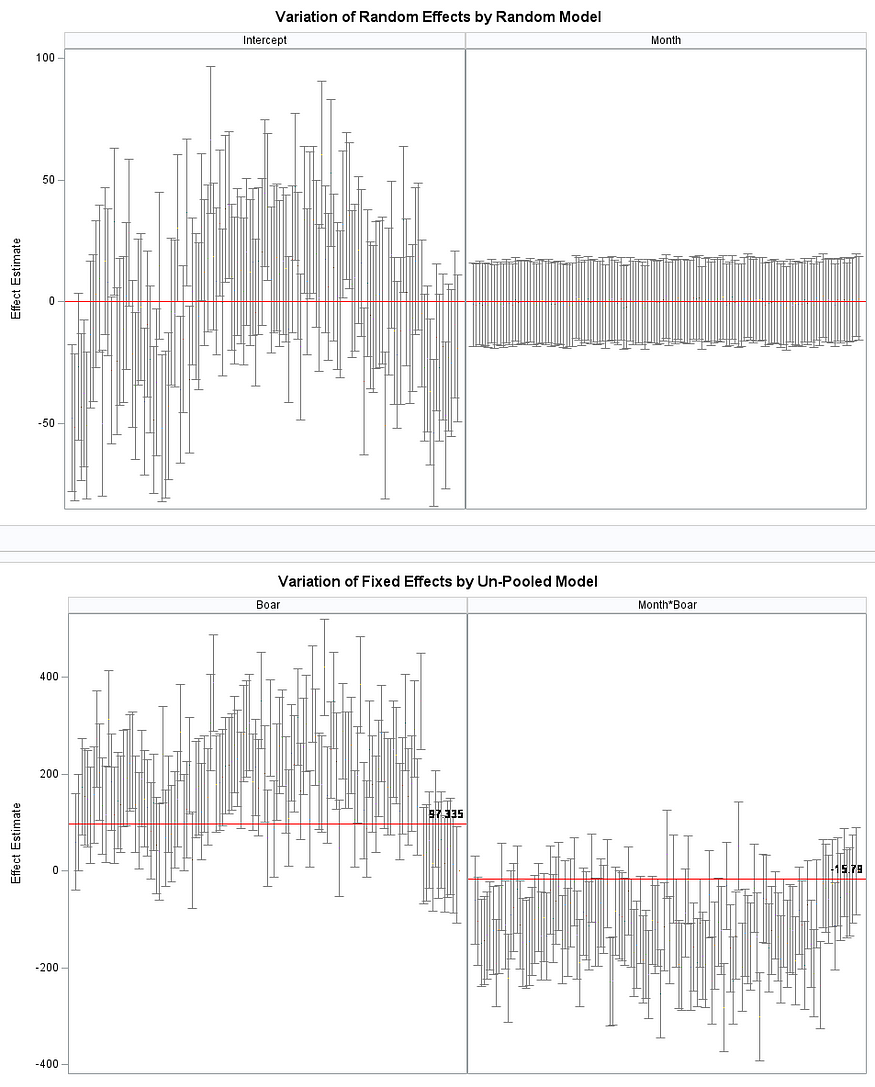
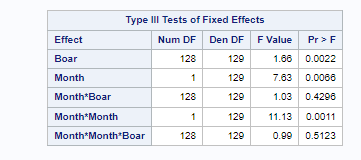
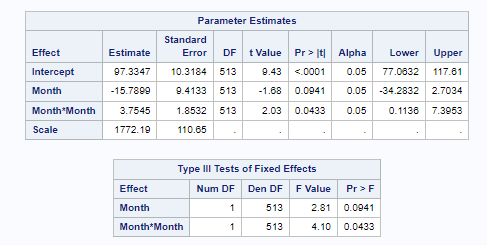
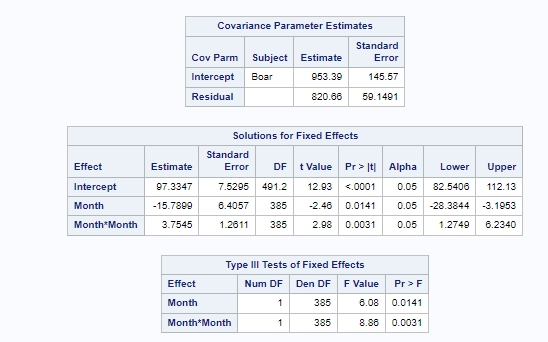
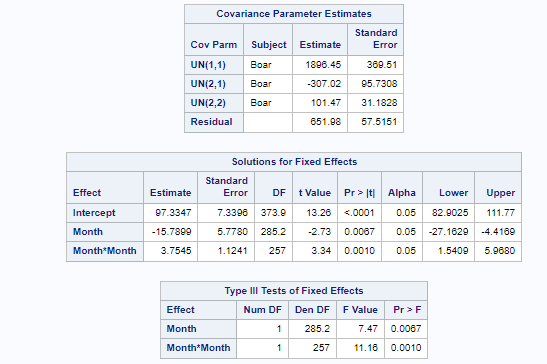
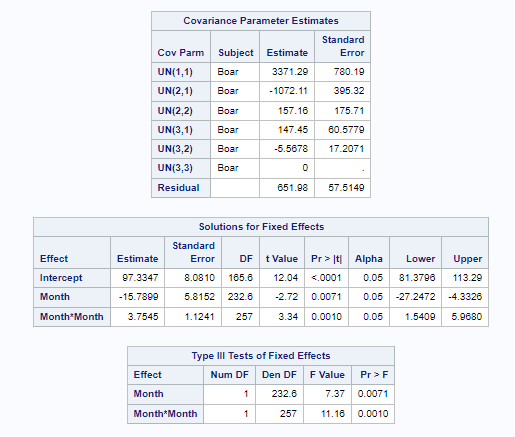
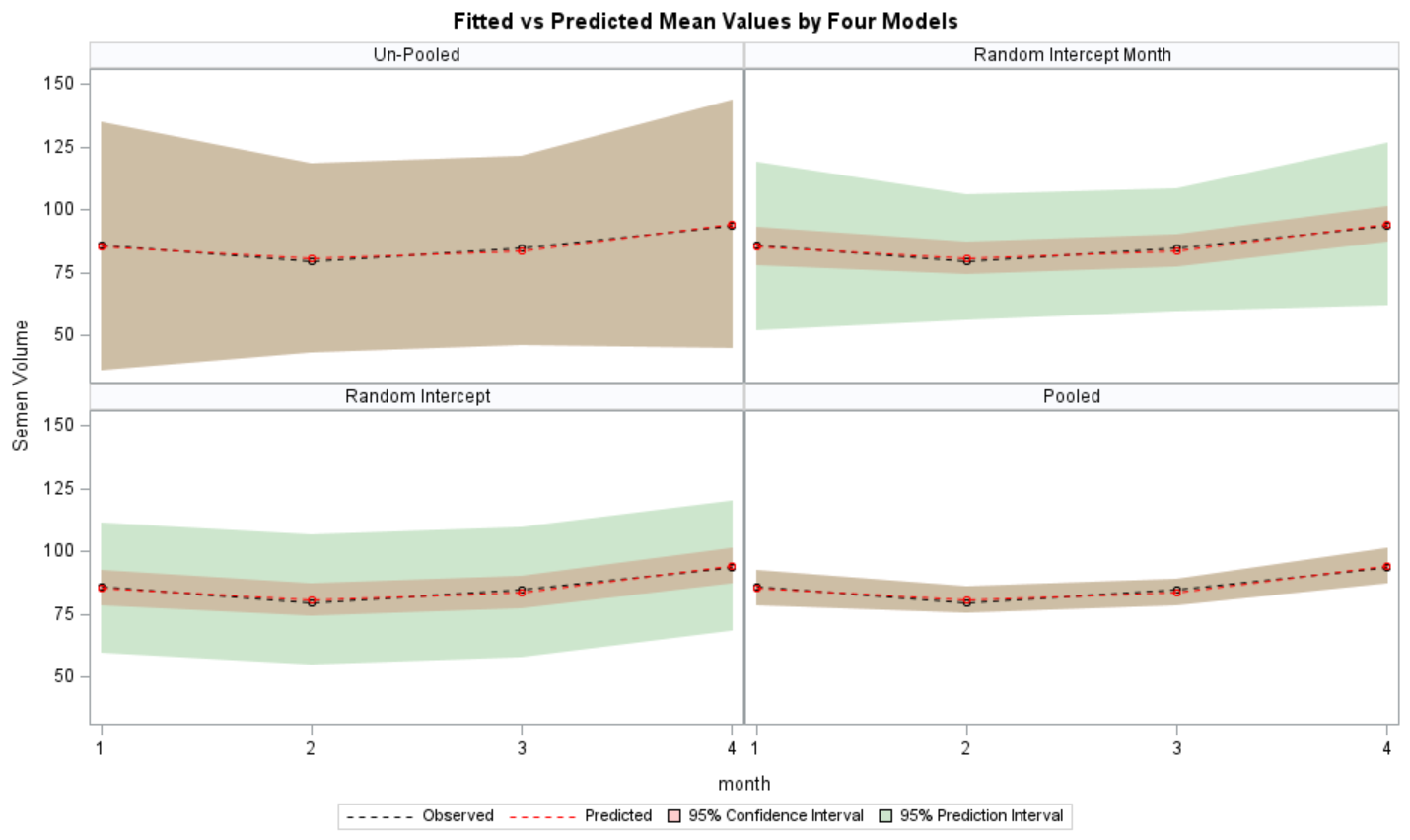


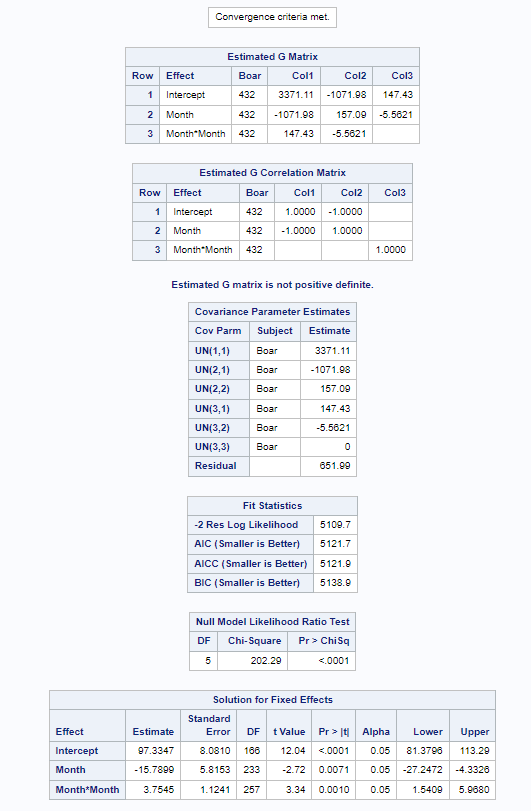
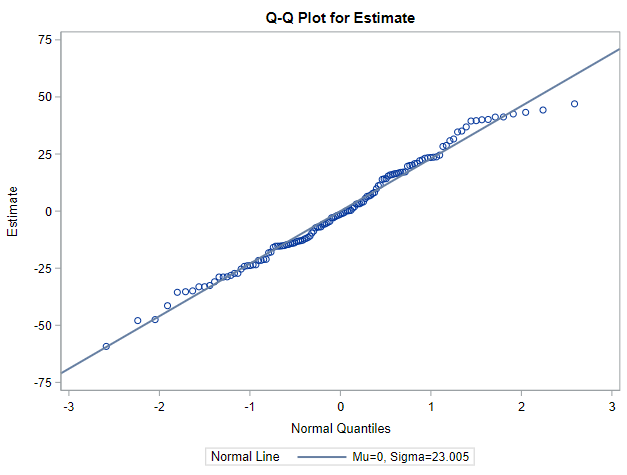
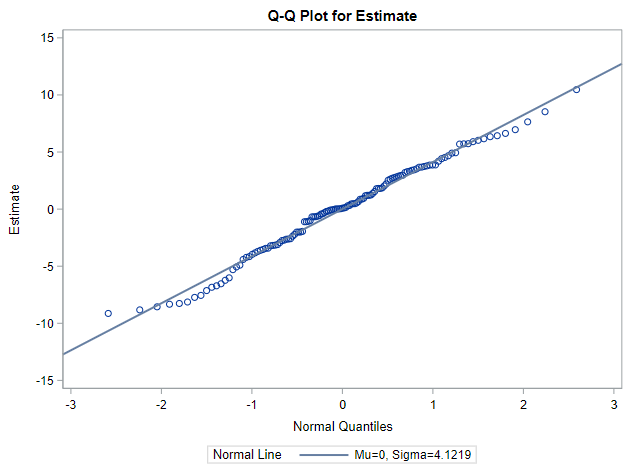
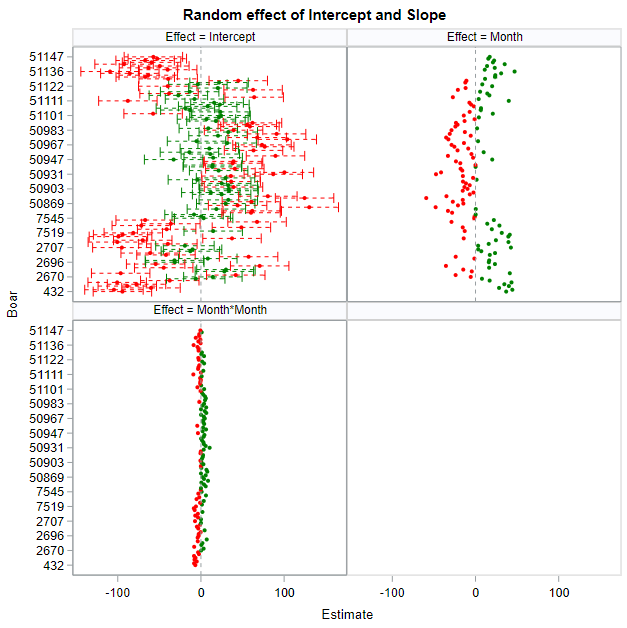
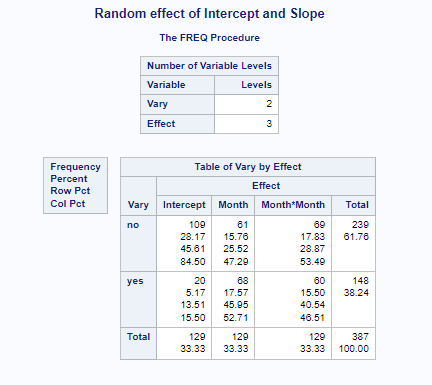
Below you can see some additional pieces of code added to look deeper into specific Mixed Models created. They are not easy to use and often lead to non-convergence or matrices that are not positive definitive. If such a warning should arise, you need to simplify the model.



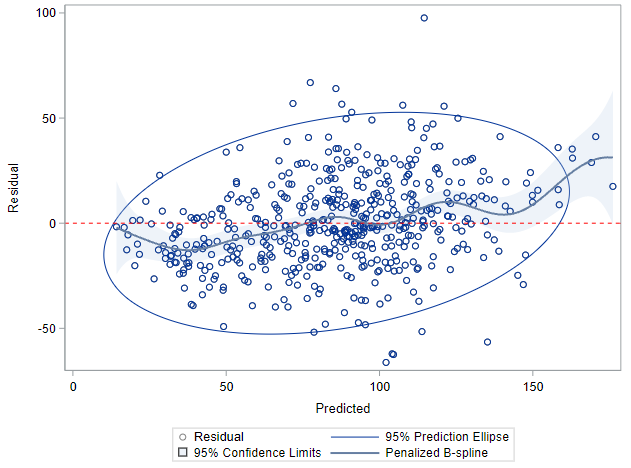

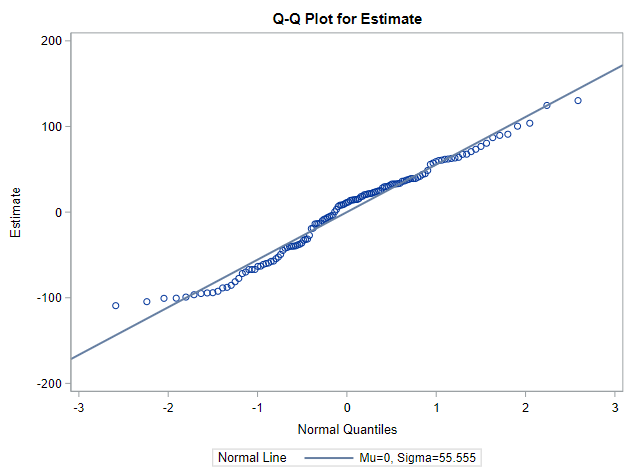

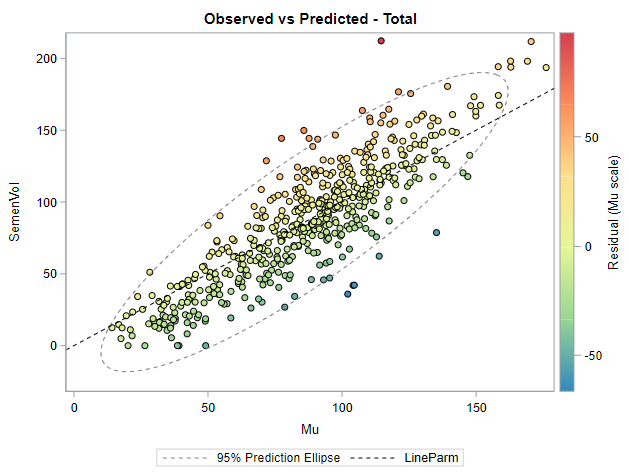


I hope this post gave you a bit more feeling about what BLUPs are and shrinkage does. Please reach out to me if you have questions, ideas, or just want to spar!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

