



Benford’s Law Meets Machine Learning for Detecting Fake Twitter Followers
Last Updated on July 15, 2023 by Editorial Team
Author(s): Erika Lacson
Originally published on Towards AI.
In the expansive digital landscape of social media, user authenticity is a paramount concern. As platforms like Twitter grow, so does the proliferation of fake accounts. These accounts mimic genuine user activities, creating noise in data and casting shadows on the credibility of digital ecosystems.
Traditional methods for detecting fake accounts often rely on complex machine-learning algorithms. However, an intriguing alternative tool exists Benford’s Law, a mathematical principle that describes the frequency distribution of leading digits in many sets of numerical data. This article explores how we can harness the power of Benford’s Law, in conjunction with machine learning techniques, to expose fake Twitter followers.
Benford’s Law: A Brief Overview
Let’s take a moment to think about the frequency of certain numbers appearing as the leading digits in various sets of data. For instance, imagine you have a dataset consisting of the prices of products at your favorite online marketplace. What would you expect to be the most common leading digit in those prices?
Intuitively, you might assume that each digit from 1 to 9 would have an equal chance of being the leading digit. After all, shouldn’t the distribution be uniform? Surprisingly, that assumption is incorrect. According to Benford’s Law, the leading digit 1 appears as the most frequent digit, followed by 2, 3, and so on, with 9 being the least common.
So what exactly is Benford’s Law?
Benford’s Law is also called the law of anomalous numbers or the first digits law¹. It provides the probability of obtaining the first digit d appearing in a set of natural numbers. According to the law, the probability of getting a 1 in the first digit position is 30.1% and runs down to 4.6% for 9.
If I ask you this: “Suppose we have data containing the population of each county in the US for the year 2000. What is the probability that a random population count begins with 1?” You now know that the answer is around 30%:
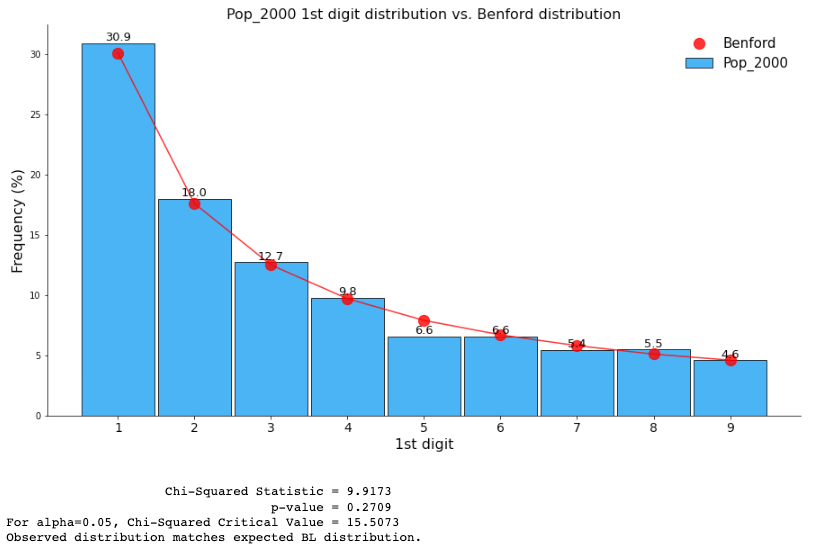
This intriguing phenomenon challenges our traditional expectations and has far-reaching implications. It has been observed not only in product prices and population figures but also in diverse datasets like financial statements, stock prices, sports statistics, Tiktok likes, and scientific measurements. Understanding and harnessing the power of Benford’s Law can unlock valuable insights and enhance our ability to detect irregularities and anomalies in various domains, including social media analytics, such as identifying fake Twitter followers.
In this blog, I delve into the fascinating intersection of Benford’s Law and machine learning, exploring how this mathematical principle can be employed alongside advanced algorithms to expose and combat the presence of fake Twitter followers.
Data Source and Description
To conduct this study, I utilized a publicly available non-synthetic labeled dataset of Twitter account data.
The source of the Twitter user dataset is the Bot Repository website², which houses a collection of Twitter user account data.
During this step, a data limitation issue arose as most of the available public data did not meet at least one of the key assumptions required for Benford’s Law. As a result, the only viable dataset I found was the cresci-2015 dataset.
The cresci-2015 dataset contains a collection of real data comprising genuine and fake Twitter accounts, which were manually annotated by the original authors³.
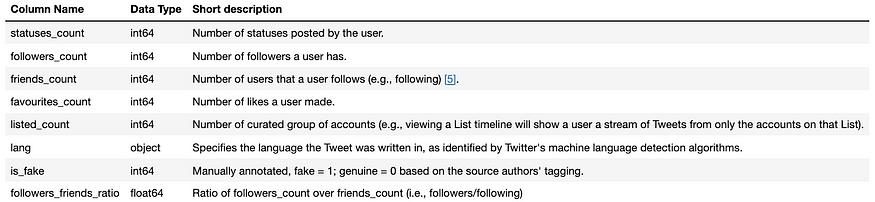
After downloading the dataset, I gathered and utilized 5301 accounts (rows) and 8 features (columns). While the dataset contained more columns, only the following columns were considered relevant for this study:
Another dataset used for a brief Benford’s Law sample illustration only is the 14_Census_2000_2010.csv from Mark Nigrini's website⁴, the author of Benford's Law book.
Key Assumptions and Examples
Before we delve into the examples and applications of Benford’s Law, let’s review its key assumptions:
- The set of numbers is not limited. (All leading digits are possible: 1 to 9)
- Numbers span multiple orders of magnitudes (1–10, 10–100, 100–1000, numbers at least 4 digits work best)
- The sample size is very large (Use the entire population, if possible; a Lower than 1,000 sample size will produce unreliable results.)
Some example datasets that do or do not follow Benford’s Law (BL) are as follows⁶:

Some major applications of Benford’s Law in Machine Learning
- Fraud/Anomaly detection
- Image forensics
- Bot/fake followers detection
Feature Engineering
Before diving into Machine Learning models, I first created a followers/friends ratio feature because social connections of the fake followers' accounts are unnatural. One of the key characteristics of fake followers include fake followers following more user accounts as compared to them having minimal number of friends (following). Although fake followers often try to get other fake follower accounts to follow them, on average, the number of accounts they follow (net friends) remains significantly higher than the number of their followers (net followers).

As evidenced by the image above, the number of followers for fake accounts is typically lower compared to the number of friends (to recap, this refers to the number of users that an account is following⁵). It’s easy to understand why fake followers would follow more accounts — after all, that is their primary purpose. Since these fake follower accounts aren’t designed to interact, they usually have a lower follower count.
Checking conformity with Benford’s Law
Based on the above discussions and graphs, it is evident that the social connections made by bots or fake followers are unnatural, and thus, they tend to violate Benford’s Law.
In checking for irregularities or indications of fake followers in each subset of data in the Twitter dataset, I performed Hypothesis Testing:
- Null hypothesis: The data subset follows Benford’s Law Distribution.
- Alternative hypothesis: The data subset does not follow Benford’s Law Distribution.
I used chi-squared test with alpha = 0.05 to test my hypotheses and to determine how well a proposed model really fits the data we observe.
Applying the above test to each data subset (genuine-only, fake-only, and combined dataframes) resulted in the following:
1. Benford’s Law on genuine accounts
Considering the key assumptions in the Key Assumptions and Examples Section of this blog, only the following features can be used to check for Benford’s Law conformity:
- followers_count
- statuses_count
- favourites_count
As illustrated below, genuine accounts follow Benford’s Distribution:

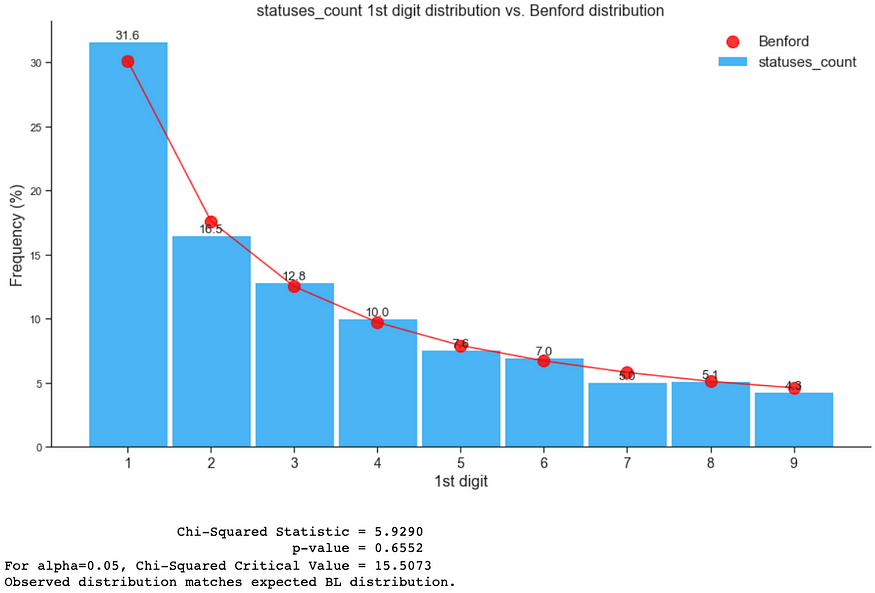

2. Benford’s Law on fake followers’ accounts
Considering the key assumptions in the Key Assumptions and Examples Section of this blog, only the following features can be used to check for Benford’s Law conformity:
- followers_count
- statuses_count
- favourites_count
- friends_count
As shown below, the fake-only data distribution did not conform with Benford’s Law Distribution:
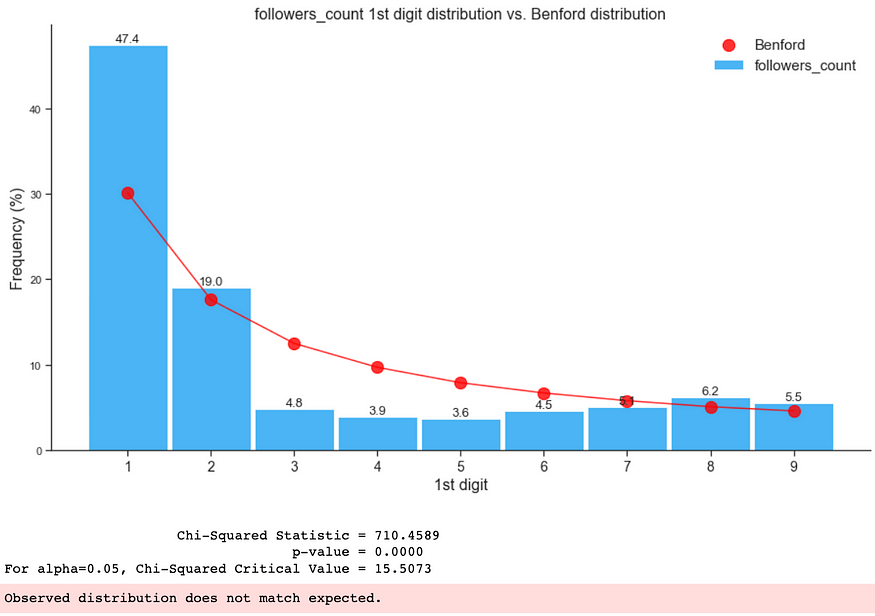

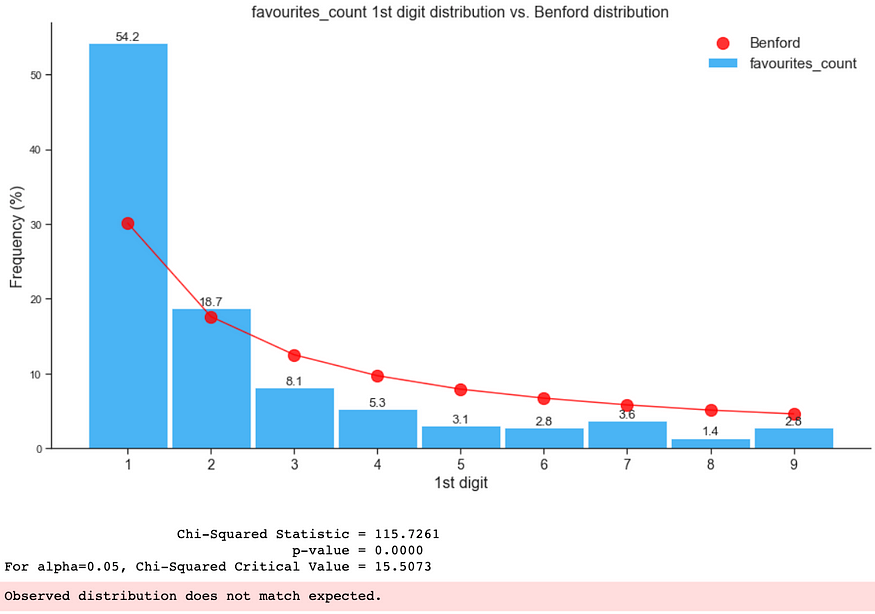

3. Benford’s Law on the whole dataset (combined genuine and fake)
Considering the key assumptions in the Key Assumptions and Examples Section of this blog, only the following features can be used to check for Benford’s Law conformity:
- followers_count
- statuses_count
- favourites_count
- friends_count
As shown below, the presence of fake followers in the whole dataframe caused it to not conform with Benford Distribution:




As shown above, by checking the dataset’s or data subset’s 1st digit distribution, we can immediately see if there are irregularities or indications of fake followers or even bots in the dataset. We can use such insights to know which group of datasets or subsets to prioritize in checking when the objective of the study is to identify the existence of anomalies or manipulations or unnatural figures reported in the dataset (such as fraud, or fake followers in this study).
Machine Learning Models
In this section, we will explore Machine Learning models to identify the presence of fake followers within a Twitter dataset. The focus will be to ascertain whether the primary predictor variable identified by auto-machine Learning classifiers aligns with the supposition that the social connections of these fake accounts, particularly the followers-to-friends ratio, are anomalous.
To undertake this classification task, I have utilized a suite of machine learning models, including Gradient Boosting, Random Forest, and k-Nearest Neighbors (kNN). With the aid of an auto-ML function, I identified the top predictor variable critical for detecting fake Twitter followers. Subsequently, I compared its implications with the findings inferred from Benford’s Law to corroborate the results.
Baseline: Proportional Chance Criterion (PCC) is 53%, so we have to beat 67% accuracy (1.25 x PCC).
Auto-ML: Execute the auto-ML function created, obtain the top predictor variable for detecting fake Twitter followers, and compare its results to those of the BL:

Observations
As expected, the analysis revealed that the followers/friends ratio consistently emerged as the top predictor variable, aligning with the findings of Benford’s Law. This supports the initial hypothesis that the ratio of a user’s followers to friends is a key factor in determining account authenticity. Furthermore, genuine followers, as naturally occurring datasets, exhibited adherence to Benford’s Law. Applying this law allowed the identification of fake followers within the datasets, as genuine accounts followed the distribution of Benford’s Law while datasets with fake followers deviated from it.
Conclusion
This study introduced Benford’s Law and its application in Machine Learning using the cresci-2015 dataset. The key challenge was finding a non-synthetic dataset that satisfies the prerequisites for Benford’s Law application. Features such as follower counts, friends count, and others were identified as distinguishing factors between fake and genuine accounts. These characteristics were then used to check the conformity with Benford’s Law and applied to Machine Learning models to classify users. The models showed a high detection accuracy (99%+) for identifying fake followers.
While fake followers try to mimic genuine activities, their unnatural behavior means they violate Benford’s Law. Even a slight variation in their first-digit distribution could cause the entire data to deviate from the Benford’s Law distribution.
By applying Benford’s Law, we detected the presence of fake followers in the datasets. All genuine accounts conformed to Benford’s Law, whereas datasets with fake followers (such as the fake dataframe and the combined/whole dataframe) did not.
Furthermore, the auto-ML provided results consistent with Benford’s Law findings. The ratio of follower count to friends count was a consistent top predictor variable across all Machine Learning models used. This confirmed the initial assumption that the ratio of a user’s followers to their friends (followings) is a key factor in determining whether an account is genuine or fake.
We can conclude that naturally occurring datasets follow Benford’s Law. A simple visualization of Benford’s Law can be used both as part of the pipeline for detecting anomalies and for exploratory data analysis to identify potential errors, fraud, manipulative bias, or processing efficiency issues in a dataset. In addition, Benford’s Law could also be applied as a standalone, initial indicator for the presence of fake followers, providing a rough yet valuable preliminary identification tool. Lastly, for large datasets, Benford’s Law can assist in performing highly focused tests to detect deviations in subsets before starting with the Machine Learning modeling process.
Recommendations for Future Studies
Since this study was primarily conducted to introduce how Benford’s Law can complement or help provide simple and immediate insights about any irregularities or signs of manipulation in our datasets, there are a lot of improvements that could be implemented for future studies. Based on the insights from our analyses and conclusion, the following items are highly recommended for future studies:
- Use larger datasets: To fully exhibit the strengths and uses of Benford’s Law as a complement or part of an ML pipeline or even just as part of an EDA, since Benford’s Law’s results tend to be more accurate as the size of the dataset increases, it would be best to use a larger dataset.
- Real-time Fake follower detection: Considering the results discussed in this blog, it would be very beneficial to make Benford’s Law and Machine Learning fake follower detection work in real-time as a web or app add-in to help with the immediate detection of the existence of fake followers or even bots in the app that a user is using.
- Consider other non-numeric features for a stronger model: Using Natural Language Processing or information retrieval and other models to process and include non-numeric features such as actual tweets made by the users could be used in conjunction with the aforementioned Benford’s Law and ML steps to strengthen the precision and recall of the dataset.
Further exploration and study of Benford’s Law related to improving ML models in detecting fake followers would help make Twitter and any other social media applications a safer environment for all genuine users.
Source Code
If you would like to explore a more comprehensive analysis and code of this project, please feel free to visit my GitHub repository by clicking this link. Thank you!
References
[1] Benford, F. (1938). The Law of Anomalous Numbers. Proceedings of the American Philosophical Society, 78(4), 551–572. https://www.jstor.org/stable/984802
[2] Bot Repository developers. (2022, November). Bot Repository Website. https://botometer.osome.iu.edu/bot-repository/datasets.html.
[3] Cresci, S., Di Pietro, R., Petrocchi, M., Spognardi, A., & Tesconi, M. (2015). Fame for sale: efficient detection of fake Twitter followers. arXiv:1509.04098 09/2015. Elsevier Decision Support Systems, Volume 80, December 2015, Pages 56–71.
[4] Nigrini, M. (Wiley, 2012). Benford’s Law. https://nigrini.com/benfords-law/
[5] Twitter Developers. (2022, November). Follow, search, and get users. https://developer.twitter.com/en/docs/twitter-api/v1/accounts-and-users/follow-search-get-users/overview
[6] National Association of State Auditors, Comptrollers and Treasurers. (2017). Fraud Analysis and Detection: Using Benfords Law and Other Effective Techniques. https://www.youtube.com/watch?v=9tpGVq5DcTw&t=4961s
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

