



Beginner Tips for Using Azure Machine Learning
Last Updated on April 2, 2022 by Editorial Team
Author(s): Andrew Blance
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Beginner Tips for Getting Started with Azure Machine Learning
Getting ready for the DP-100 Azure Data Science Associate exam.
The end-to-end pipeline for a data science model is diverse and winding. Between exploratory data analysis, model training, deployment, and managing those models, there are a lot of moving parts. Azure Machine Learning is Microsoft’s cloud service to help developers along this journey. It offers a wide set of tools to track your model’s development, version your data, securely deploy your model, and more.
I think many good APIs and software share some things in common. One of these is that they are good at predicting your desires, or at least have an understanding of how the user will want to interact with the system. When I write code and think “oh boy, I wish there was a way to do this really easily”, and then stumble across a feature of the language that does that exact thing in one line, I feel like the writer of the library has done something really special. This happens a lot in Python I think, with Pandas or Numpy being designed in a way that seems to understand how I will want to interact with it (except for times and dates, which kinda suck in everything).
Currently, I am preparing for the DP-100, a Microsoft exam about using Azure ML to do data science. I’ve spent a lot of time learning about the ecosystem and getting to know how it all works. I find myself thinking quite a lot about how well designed a lot of it is. How a lot of the features make my life a lot easier, removing my need to write a lot of code, as they have implemented a smart function to do it already.
I’ve not really written about data science before, but I thought I would try it here. There are already lots of great stuff out there about the DP-100, so instead, I thought I would try something slightly different. This is a list of things that compliment the DP-100 and go well with the syllabus, or in some cases, things I thought were pretty neat from it. It’s not full tutorials on how to use the features, but lil suggestions of things to look at. Enjoy!
Visual Studio Code
Ok, so this is sometimes mentioned in the syllabus. However, I’ll mention it again since it’s integrated into it so well.

Within Visual Studio Code, the Azure Machine Learning plugin allows you to have access to your Workspaces, Datasets and Computes, etc. Basically, it allows you to use VSCode as your IDE while retaining the functionality of the Azure ML. Once you connect to a running compute you are able to access the files stored on it, and run your code the way you would on your local machine. On the Azure ML browser, you are a little limited to using notebooks, whereas here you can write scripts as you please!
Standardisation
From my experience learning programming, I think there may be a distinction between “hard” and “soft” programming skills. I’m gonna call the “hard” skills the pure coding: the language itself. The “soft” stuff is literally everything else around it. I’m not even sure that this is a good distinction to make, in fact, splitting these in two probably results in worse code. However, I mention it as I think sometimes when you learn to code you are subtly trained to make the distinction. In my experience, coding courses and textbooks focus almost solely on the “hard” skills, and leave the “soft” stuff as an exercise to the reader.
I’m not much of a programmer, I still have a huge lot of room for improvement. I think much of where I have got better has come from embracing the softer side and a thoughtful and informed rejection of the “hard”. A lot of my problems were typical ones — “oops I wrote this code 3 months ago and forgot what it does”, “oops I wish I could go back to an earlier version of the code” or “oops I’ve been given someone else's code and have no idea how to use it”. I feel a lot of these are solved not with being able to write speedier functions, but with DevOps and standards.
Anyway, that is a big introduction to simply say: try standardising stuff. Microsoft has recommended naming conventions for Azure recourses, and there are templates out there for laying out your coding projects (I’ve played around with this, badly, on Github). By standardising things, it helps new people come into a project, helps you when you go into a project you haven't been on, and you help yourself when you return to code you haven't seen in ages. Things will always be named in a consistent manner, and projects will be laid out in familiar ways.
For example, you could have a recourse group for each every project, named like:
rg-example-dev-001
This tells you a lot of information already: you know its a recourse group (rg), you have an idea of its purpose (it's for a project called example), and you know it's for the dev build (rather than uat or prod). Now, inside here you could make an Azure Machine Learning Workspace, and call it:
mlw-example-dev-001
This style can be followed for everything else, and should hopefully mean everything is all neat and tidy.
CI/CD
Using some kind of version control is absolutely vital. This is when code is sent to a “repo” for safekeeping. Being able to track changes and revisions to your code is an absolute lifesaver. It’s something that is left out of a lot of coding tutorials and textbooks I think, and I’ll admit I did spend way too long never using Git at all (just a monumentally terrible mistake).
Continuous integration then is when code is automatically checked whenever it is sent into a repo. This might involve automatically running all the tests you’ve written, checking if the code can build, or running a linter.
At work, we use Azure DevOps, which has lots of fun tracking things for project management. I use Github for all my personal stuff, and it has a wonderful feature where you can launch notebooks in-browser by hitting the . key on your keyboard. It's amazing. Both have robust CI/CD offerings: Github has Github Actions and Azure DevOps has Pipelines, but both work similarly.
In Github, you can create a file .github/workflows/main.ymlwhich looks like:
name: Linting and Testing
on: [push]
jobs:
build:
runs-on: ubuntu-latest
strategy:
matrix:
python-version: [3.7, 3.8, 3.9]
steps:
- uses: actions/checkout@v2
- name: Set up Python $
uses: actions/setup-python@v2
with:
python-version: $
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Test with pytest
run: |
pytest --ignore=docs
This code, every time you push your code will create a Python instance (either 3.7, 3.8 or 3.9) with packages based on the contents of requirements.txt , then run pytest . Now, when you check the project’s Github page you can take the results of the CI pipeline into account before you accept a pull request. Azure Pipelines use a very similar syntax. It's a great way of making sure code passes certain tests before accepting it.
ps, Microsoft, please release the . thing for Azure DevOps!
Sharing Environments
For each project, I create a Python environment for it. This is driven by a requirements.txt file. This file, as hinted at above, is also used to create the Python environment that is used for the CI/CD pipeline.
When you submit jobs in Azure Machine Learning using the run methods, you need to specify the environment to use. I (wrongly) imagined at the time I would have to create a whole new environment. I thought I would have to do this by looping through my requirements file, passing the contents of it .add_pip_package() one at a time. Eventually, that would create the same environment as everywhere else. However, it's much easier than that.
Firstly, you can use .from_pip_requirements() and pass the whole requirements file into it in one go. Or, if you’ve already created a conda environment you can just specify that in.from_existing_conda_environment() .
Then, if you register this environment, you can see it in Azure ML’s “Environment” tab! Now, you should have consistent environments across all parts of your project.
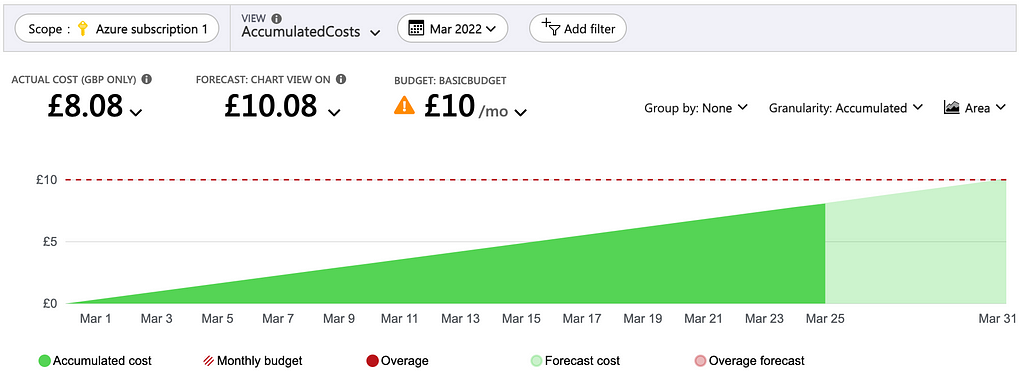
Setting a Budget
I am sorry to break this to you: one day you will leave a VM or compute or something running when you thought you turned it off. This might be for an hour, or for weeks, but it’s gonna happen. I try not to think about how much I’ve accidentally spent, it’s not good….
In your recourse group or subscription, you can set a budget, which can help you stop this problem before it’s a problem. You can put in the amount you think you should be spending, and set points at which you want to be warned if you are starting to approach it.
Final thoughts
So that are a few things that I’ve found useful when using Azure Machine Learning. Each point could really be its own article — I’ve done all the points a disservice, really! There are also so many other things I’ve found that I think are neat (the “Model” tab in Azure ML, Labeller, and Synapse) that I would also love to talk about. If people are interested, I might come back and write some more about everything!
However, these 5 things: VSCode, standardization, CI/CD, environment management, and Budgets are all good tools to build upon some of the DP-100 content! I might return to these things later for more in-depth exploration, but hopefully, you enjoyed what was here!
Andrew is a data scientist at Waterstons, an IT consultancy. He hosts a silly podcast called Brains on the Outside and is in a genuinely terrible band called Dioramarama. Regardless, Durham University deemed him sensible enough to make him a Doctor of particle physics (and kinda machine learning and quantum computing). Once, in a moment of unthinkable insanity, he decided to learn the 6502 assembly programming language. He can run 5km pretty fast (22:05) and thinks modern Star Trek isn’t as bad as people make it out to be.
Beginner Tips for Using Azure Machine Learning was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

