


")
Bag-of-Words(BOW)
Last Updated on January 27, 2022 by Editorial Team
Author(s): vivek
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Natural Language Processing
In the previous blog, we have extensively discussed the need to convert text to vector to perform machine learning algorithms, so that meaningful insights can be drawn from the text data. Text data is the major form of data available in the current world from many industries like Healthcare, Travel, Ecommerce, etc…
So, it is highly desirable to process and analyze the insights from the text data which may help in faster decision-making /assistance to decision-making in the healthcare industry, making the journey comfortable with the help of passengers from their reviews in the travel industry.
Bag-of-Words is a very simple strategy that converts text to the numeric vector which helps machine learning algorithms to perform on the text data.
The main objective of converting text to numeric vector is Semantically Similar (SS) the text must be closer (closer vector).
Before getting into the blog let’s have a look at basic terminology used in NLP
Corpus — It is a file containing all the documents.
Document — Document is generally a review given by a user to a specific product or service.
BOW:
Let’s discuss the concept with an example, A publisher asked the readers to post a review after completion of the book. So, readers posted their reviews which helps to make necessary changes in the next edition. The following is the corpus containing around n documents(reviews) posted by readers. Let’s have a look at some of the documents in the corpus. This is considered step one.
R1: This book is very informative and expensive.
R2: This book is not informative and expensive.
R3: This book is informative and costly.
R4: Book is informative and the book is expensive.
The second step in the bag of words is to design a list of all the unique words(dictionary) or construct a set of all the unique words.
From the above documents(reviews) the set of all the unique words are as follows:
This book, is, very, informative, and, expensive, not, costly.
Let us assume we have d-Unique words across all the documents.
Moving forward after constructing a set of all the unique words, step three is the construction of the vector with the help of unique words present in the corpus.
V1, V2, V3, V4 are the vectors to the reviews R1, R2, R3, and R4 respectively.
Constructing vector V1 for the review R1.
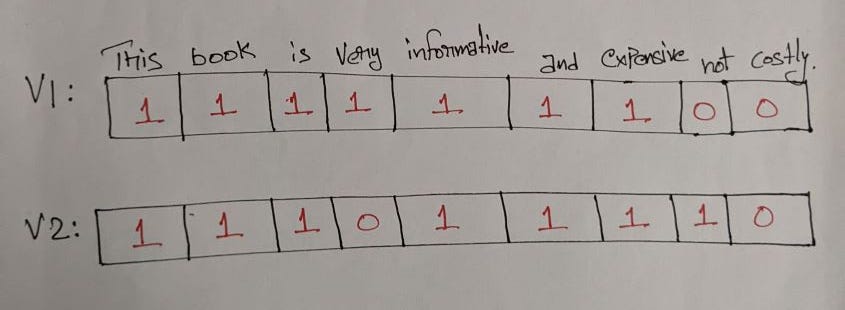
R1: This book is very informative and expensive.
Now we need to construct a vector of size d, so that all the unique words correspond to a different dimension V1 belongs to R^d(real coordinate space of d dimension) as it is d-dimensional, each word corresponds to one index in the dictionary.
The vector V1 is a d-dimensional vector i.e., it contains all the d-unique words from the corpus. The number of times a word appears in R1 is given count and is filled in the corresponding cell of V1. In the above figure, This appears only once so the count (number of times the word occurs) is 1, the word costly is not present in R1 so the cell corresponding to it is filled by 0. This way the whole vector V1 is filled.
As V1 is d-dimensional i.e., very large most of the cells are filled with zero, this condition leads to a sparse vector. A sparse vector is a vector in which most of the cells /elements of the vector are zero.
This strategy of converting text data to a numeric vector is called Bag-of-Words.
Working of Bag-of-Words:
Let’s take R1 and R2,
R1: This book is very informative and expensive.
R2: This book is not informative and expensive.
Length(V1-V2) = ||V1-V2||
||V1-V2|| is norm form
So, from the above Fig 2,
There are only two different words present one is Very and the other is not at these vectors so the difference at both these we get is |1–0| = 1.
||V1-V2|| = sqrt(1^2 + 1^2) = sqrt(2).
From the above, we can observe that sqrt(2) is the distance between the two vectors which is very small.
But we can see that the two reviews are completely opposite except they both are saying the book is expensive, but one is saying it as very informative and the other is saying not informative.
So, we can say that the bag of words doesn’t perform well when there is a small change in the words used in the document.
Binary Bag-of-Words
There is another strategy with a slight variation called Binary Bag-of-Words. It works as follows, the only difference to Bag-of-Words is instead of counting the number of occurrences of the word it marks one if the word occurs and if the word didn’t occur it marks zero in the vector. This is the only variation between Bag-of-Words and binary BoW. It is also called Boolean Bag-of-Words. So, binary BoW is nothing but the number of different words in the vectors (V1 and V2 for the above example).
||V1-V2|| = sqrt(2).
Limitations of Bag-of-Words:
The BoW model is very simple to grasp and to work with great success on reading documents, it has its own limitations.
1) Construction of dictionaries needs careful attention, because of the large sizes of the corpus available in real-world scenarios.
2) Sparsity is very common as the vectors are of size d-dimension (very large) presenting this small information in large sparse vectors is a challenge and reasons like space and time complexity during computation.
3) The model is solely based on the words, ignores the word order and the context of the word, which eliminates the flexibility to explain the meaning of the same word in another context.
Thank you, Happy learning people.
Bag-of-Words(BOW) was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")