



Applying Classification Algorithms to Past Loan Data
Last Updated on July 5, 2022 by Editorial Team
Author(s): Gencay I.
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
KNN, Decision Tree, Support Vector Machine, Logistic Regression
In this data set, I am going to conduct classification machine learning analysis on past loan data which are;
- K Nearest Neighbor(KNN)
- Decision Tree
- Support Vector Machine
- Logistic Regression
Content Table
· Data Visualization
· One hot encoding
· Feature Selection
· Normalize Data
· Classification
∘ K Nearest Neighbor
∘ Evaluation Metrics of KNN
∘ Decision Tree
∘ Evaluation Metrics of Decision Tree
∘ Support Vector Machine
∘ Evaluation Metrics of SVM
∘ Logistic Regression
∘ Evaluation Metrics of Logistic Regression
∘ Model Evaluation using a Test set
∘ Jaccard Scores
∘ F1 Scores
∘ Final Evaluation
Let's load the necessary libraries;

The Loan_train.csv data set includes details of 346 customers whose loans are already paid off or defaulted.

Lets load data;
It is always efficient to look shape of data, to see the big picture.

Now let's fix the data frames column type.
Data Visualization
Let's see how many of each class is in our data set

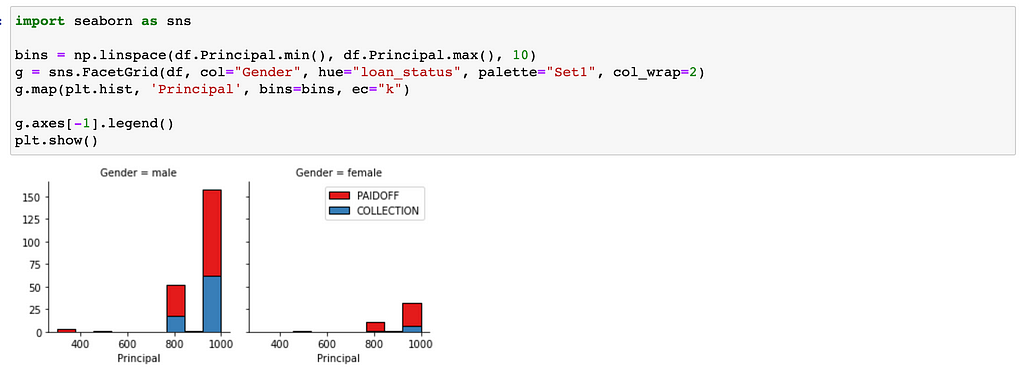
Let's plot some columns to understand better
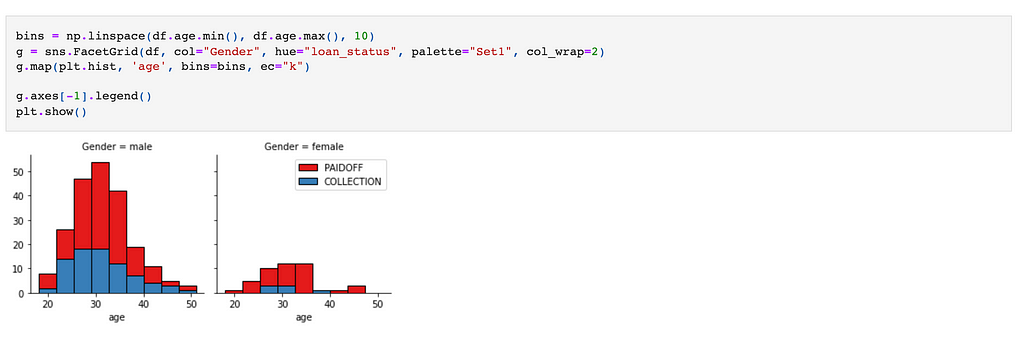
Let's look at the day of week people get the loan
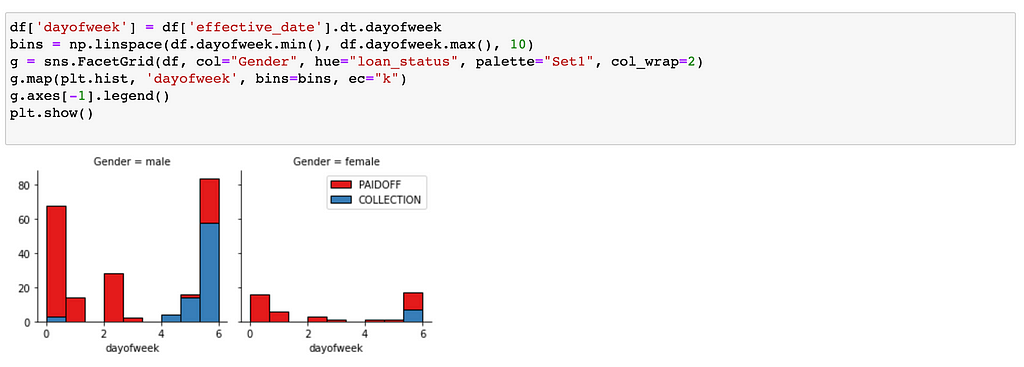
We see that people who get the loan at the end of the week don't pay it off, so let's use Feature binarization to set threshold values less than day 4
Now it is time to change categorical features to numerical because we will use machine learning algorithms.

86 % of females pay their loans while only 73 % of males pay their loan
Let's convert male to 0 and female to 1:
One hot encoding
Now let’s look education column.
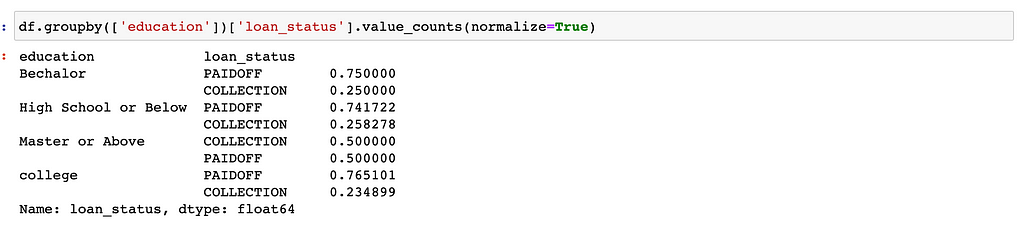
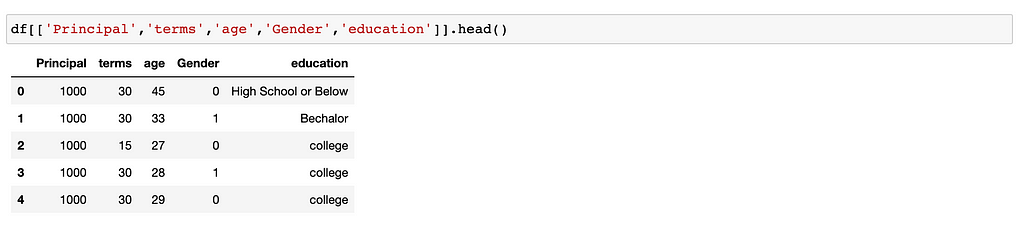
We use dummies to transform education from categorical to numerical.
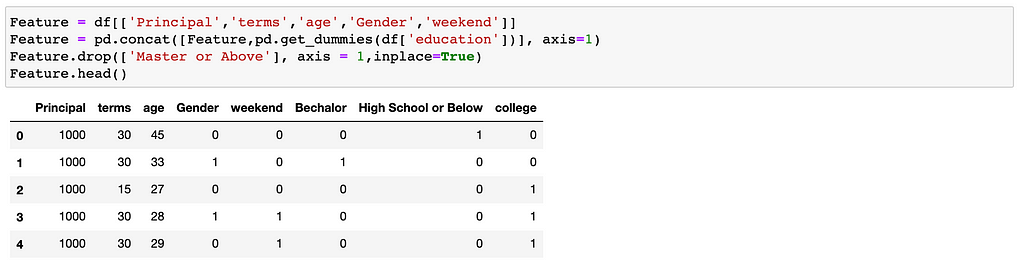
Feature Selection
Let’s define features;
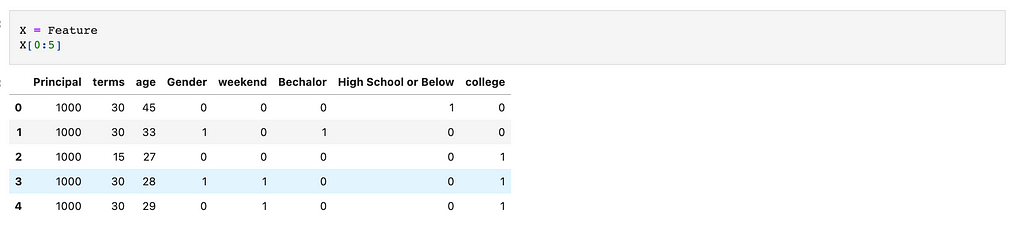
Now it is time to define our label;

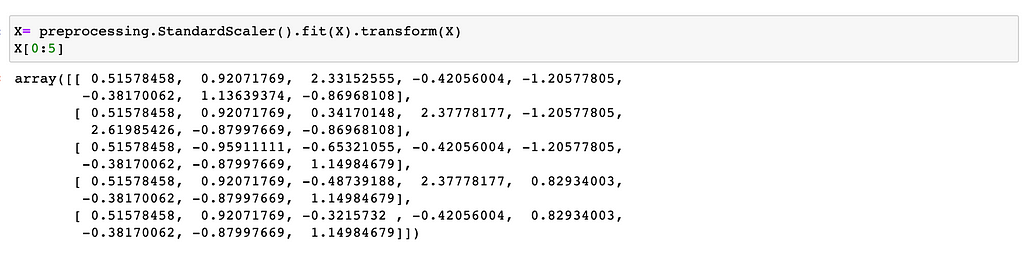
Normalize Data
Classification
These are the classification techniques that I will use in this Dataset.
- K Nearest Neighbor(KNN)
- Decision Tree
- Support Vector Machine
- Logistic Regression
K Nearest Neighbor
Now it is time to split train and test data, as usual, 0.2–0.8 portion.



Now it is time to look into the accuracy of test and train data.

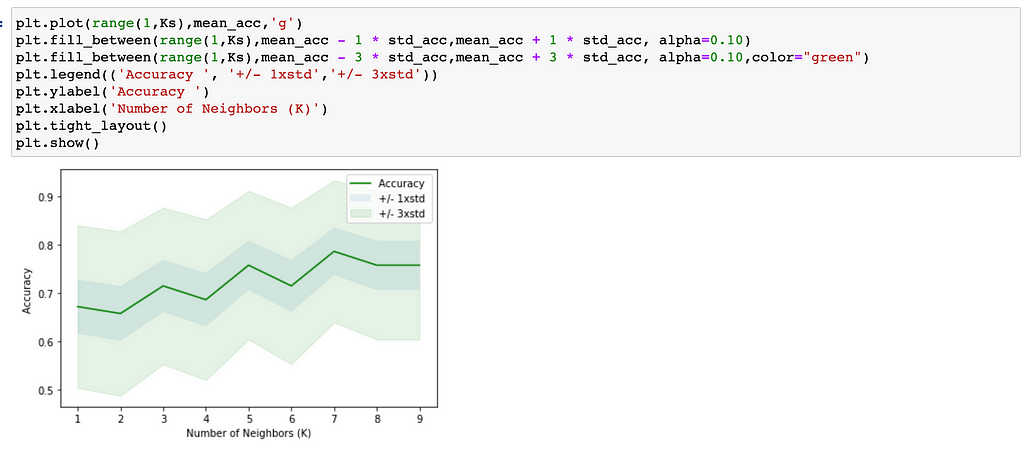
To define best K;
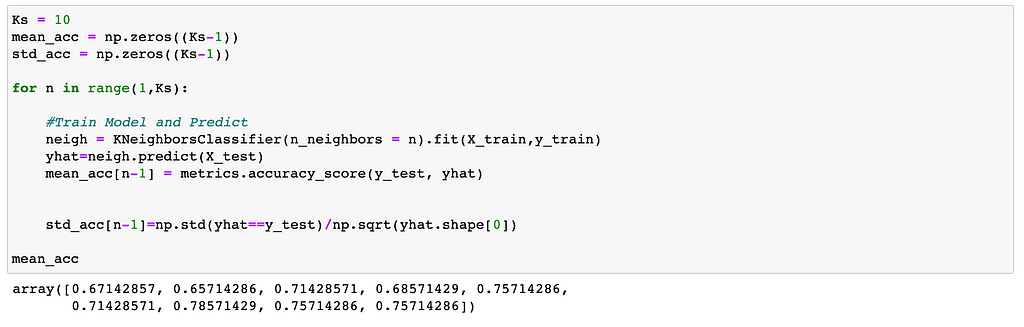
As we can see result 7 is the best K for our data.


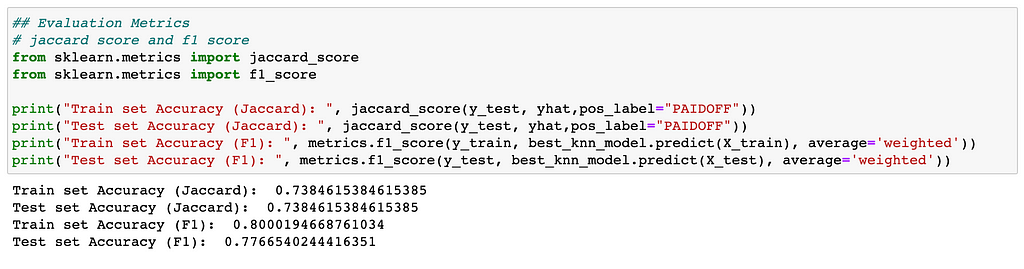
Evaluation Metrics of KNN
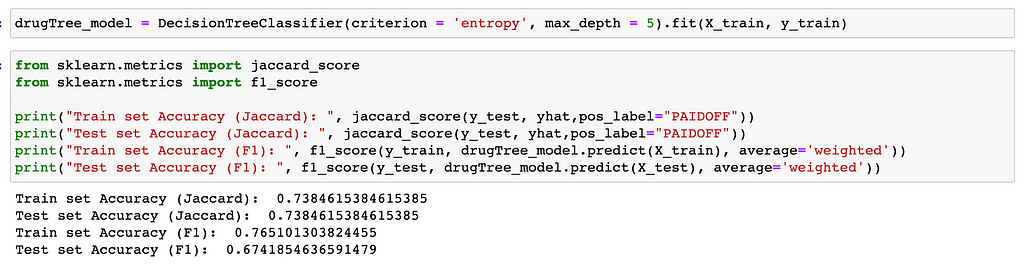
Decision Tree
Now let's try using Decision Tree algorithms.


To define the best of the depth;
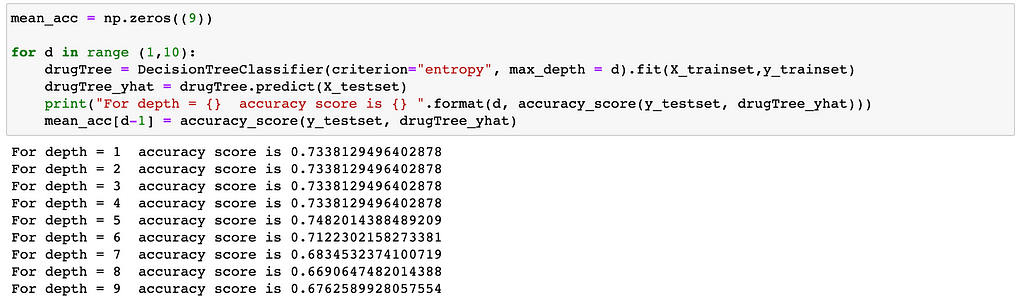
5 is the best depth score according to accuracy scores.

Let’s conduct our algorithm then and evaluate;
Evaluation Metrics of Decision Tree
Support Vector Machine
Now let’s use SVM.

To find out the best model in SVM;



Evaluation Metrics of SVM

Logistic Regression
Now it is time to use Logistic Regression.
Lets lock and load;

Train-test split;

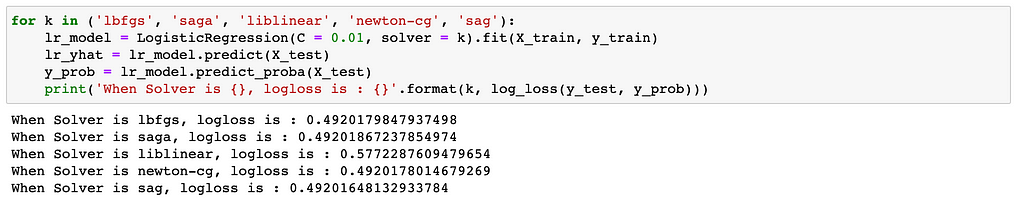
Find the best solver;

Evaluation Metrics of Logistic Regression
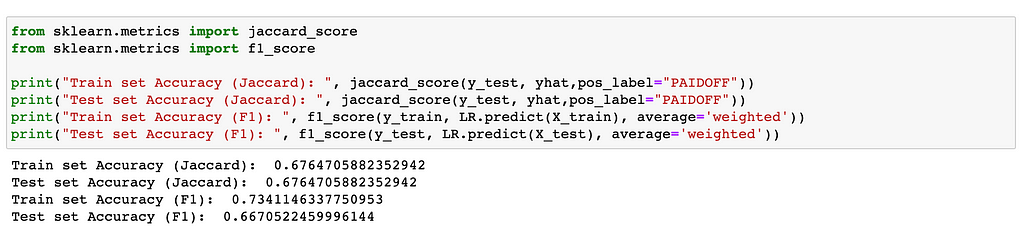
Model Evaluation using a Test set

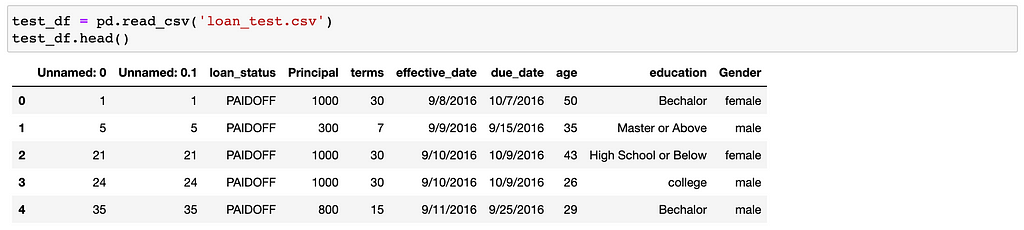
Data processing;

Jaccard Scores




F1 Scores




Final Evaluation

Thanks, IBM for Machine Learning Tutorial which gets me there.
Applying Classification Algorithms to Past Loan Data was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

