



All About Decision Tree
Last Updated on April 4, 2022 by Editorial Team
Author(s): Akash Dawari
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
In this article we will understand the Decision Tree by answering the following question:
- What is a Decision Tree?
- What is the core concept of a Decision Tree?
- What are the terminologies used in Decision Tree in the case of classification?
- What are the terminologies used in Decision Tree in case of regression?
- What are the advantages and disadvantages of a Decision Tree?
- How to implement Decision Tree using Scikit-learn?
What is a Decision Tree?
The decision tree is one of the most powerful and important algorithms present in supervised machine learning. This algorithm is very flexible as it can solve both regression and classification problems. Also, the core concept behind the decision tree algorithm is very easy to understand if you come from a programming background. As a decision tree mimics the nested if-else structure to create the tree and predict the outcome.
Before diving into the decision tree algorithm, we must understand some basic jargon related to the Tree.
What does tree mean in the computer science world?
A tree is a non-linear data structure used in computer science that represents hierarchical data. It consists of nodes that hold the data and edges which connect these nodes to each other. The uppermost or the starting node is called the root node. The end nodes are called leaf nodes. The node which has a branch from it to any other node is called the parent node and the immediate sub-node of the parent node is called the child node. See the below picture to better understand what trees look like in computer science.
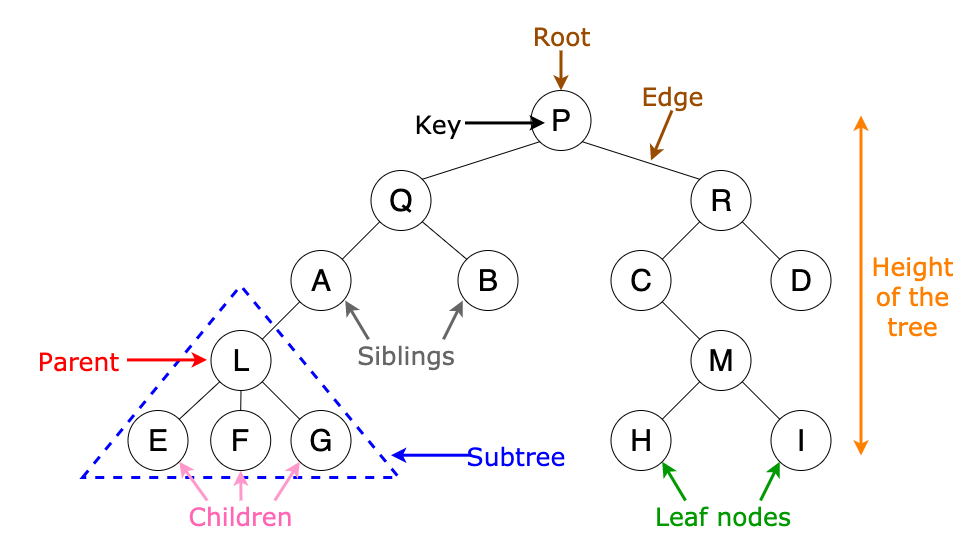
What is the core concept of a Decision Tree?
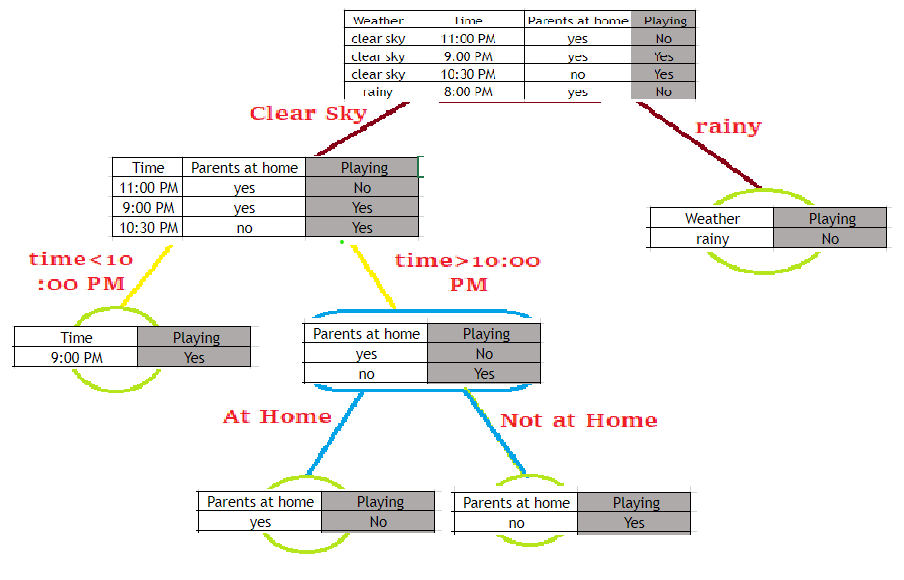
To understand the core concept let us take an example. Consider the below table:
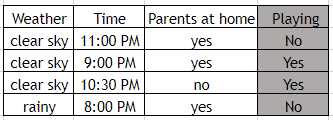
This table has 1 dependent feature which is whether a child will play outside or not denoted by “Playing”. And 3 independent feature that is weather, time, and parents at home. If we try to write a program to estimate the outcome of whether a child playing outside or not, just by observing the table. Then the program will look like this:

Now, if we use this program and try to build a decision tree it will look like this:
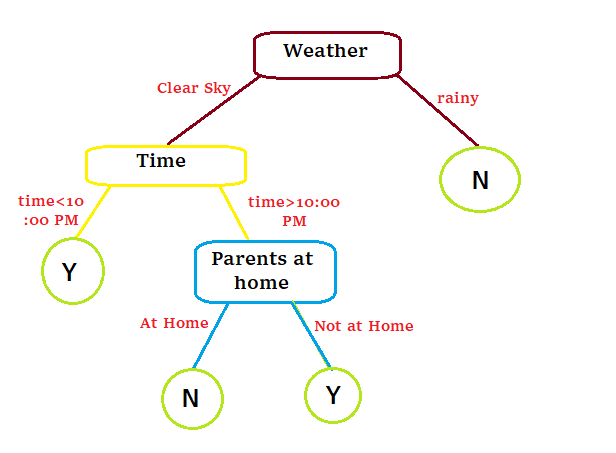
We can observe that a Decision Tree is just a nested if-else statement that is described in a tree format.
As we understand the core concept of the Decision Tree, we stumbled ourself upon a new question that is how can we arrange the order of independent features to generate a decision tree-like in the above example, how do we know that we have to take “Weather” feature first then “Time” and then “Parents at Home” features. To answer this question, we have to first understand some statistical terminologies which we will discuss below.
What are the terminologies used in Decision Tree in the case of classification?
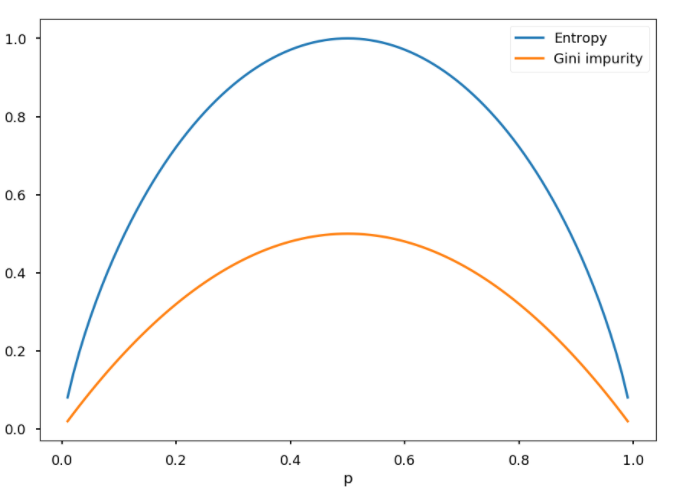
Entropy:
Entropy is the measure of randomness in the data. In other words, it gives the impurity present in the dataset. It helps to calculate the Information gain in the Decision Tree.
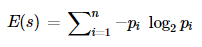
Gini Impurity:
Gini Impurity is also used to measure the randomness same as entropy. The formula of Gini impurity is:
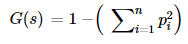
The only difference is that entropy lies between 0 to 1 and gini impurity lies between 0 to 0.5.
Information Gain:
Information gain is just the difference between the entropy of the dataset before and after the split. The more the information gain the more entropy is removed.
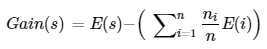
The column having the highest information gain will be split. The decision Tree then applies a recursive greedy search algorithm in a top-bottom fashion to find information gain at every level of the tree. Once a leaf node is reached (entropy =0) no more splitting is done.
What happens in the Decision Tree in case of classification problems?
Our main task is to reduce the impurity or the randomness of the data. In classification problems, we use entropy to measure the impurity and then apply the split and see the information gain. If the information gain is the highest then we will consider the split. This process will go recursively until we reach the leaf node or the entropy of the data become zero.
What are the terminologies used in Decision Tree in case of regression?
Error:
Just like in classification problems, the Decision Tree measures the impurity by calculating entropy or Gini impurity. In regression, we calculate variance error.
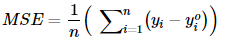
Variance Reduction:
Just like in classification problems, the Decision Tree measures the information gain. In regression, we calculate variance reduction which simply means error reduction. We find the difference between the error of the dataset after and before splitting.
What happens in the Decision Tree in case of regression problems?
In regression problems, the Decision Tree tries to identify a cluster of points to draw a decision boundary. The decision tree considers every point and draws a boundary by calculating the error of the point. This process goes on for every point then from all the errors the lowest error point is considered to draw the boundary.
This process is very expensive in terms of computational time. So, the Decision Tree opts for the greedy approach in which nodes are divided into two parts in a given condition.
What are the advantages and disadvantages of a Decision Tree?
Advantages:
- The decision tree is one of the simplest algorithms to understand and interpret. Also, we can visualize the tree.
- The decision tree needs fewer data preprocessing times as compared to other algorithms.
- The cost of using a decision tree is logarithmic
- It can be used for both regression and classification problems.
- It is able to handle multi-output problems.
Disadvantages:
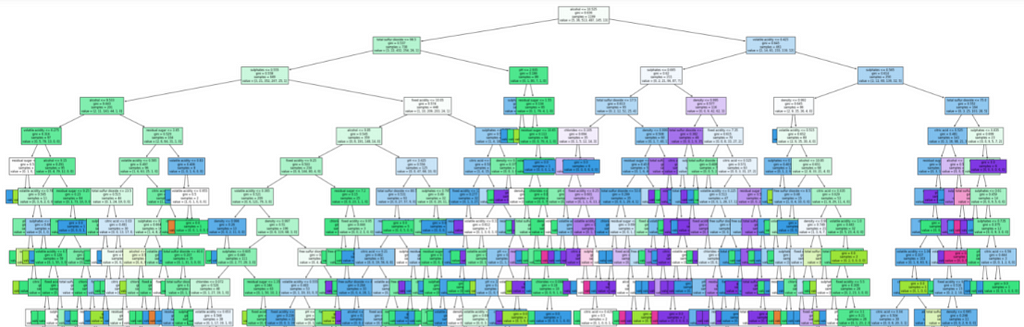
- The main disadvantage of the Decision Tree is the problem of Overfitting.
- The Decision Tree can be unstable by introducing new data points resulting in a completely new tree generated.
- Predictions of decision trees are neither smooth nor continuous, but piecewise constant approximations as seen in the above figure. Therefore, they are not good at extrapolation.
What is the solution to the disadvantages of the Decision Tree?
- For the overfitting problem, we can limit the height, nodes, or leaves of the decision tree by hyper-tunning the model. This process is called Tree Pruning.
- To handle the unstable decision tree, we can use an ensemble technique like the most famous “Random Forest”.
How to implement Decision Tree using Scikit-learn?
The coding part of the decision tree is very easy as we are using the scikit-learn package, we just have to import the Decision tree module from it.
First, we will import the required modules from python.

In this example, we are using a dataset from GitHub which is about wine quality.
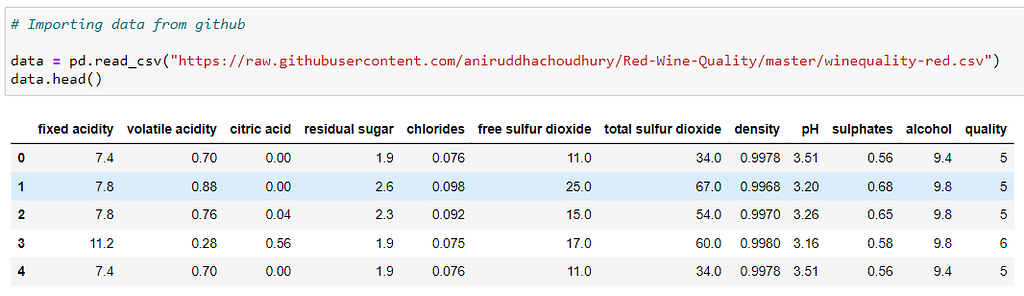
As the dataset has no null value, we will simply split it into the train, test sets.

Now, just train the model.

Accuracy score:
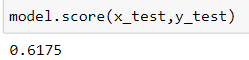
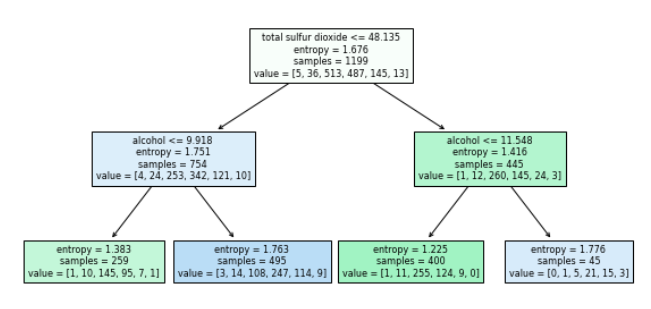
Plotting the graph:
If you want to explore more in the coding part or want to know how I tune the hyperparameter. Then, please click the below Github repository link.
Articles_Blogs_Content/All_About_Decision_tree.ipynb at main · Akashdawari/Articles_Blogs_Content
Like and Share if you find this article helpful. Also, follow me on medium for more content related to Machine Learning and Deep Learning.
All About Decision Tree was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


