



A Gentle Introduction to Hint Learning & Knowledge Distillation
Last Updated on August 23, 2021 by Editorial Team
Author(s): LA Tran
Deep Learning
Guide a student to learn a teacher’s behavior.
Knowledge distillation is a method to distill the knowledge in an ensemble of cumbersome models and compress it into a single model in order to make possible deployments to real-life applications. Knowledge distillation was introduced by the Godfather of AI, Geoffrey Hinton, and his two co-workers at Google, Oriol Vinyals and Jeff Dean in 2015.
Knowledge distillation refers to the transfer of the learning behavior of a cumbersome model (teacher) to a smaller one (student), in which, the output produced by the teacher is used as the “soft targets” for training the student. By applying this method, the authors revealed that they achieved surprising results on the MNIST dataset and showed that a significant improvement can be obtained by distilling the knowledge in an ensemble of models into a single model.
Knowledge Distillation for Image Classification
Hinton and his two co-authors first introduced their knowledge distillation for the image classification task in the paper: Distilling the Knowledge in a Neural Network. As mentioned in the paper, the simplest form of knowledge distillation is that the distilled model is trained on a transfer set with soft target distribution. So far we should know that there are two targets that are used for training a student model. One is the correct labels (hard target) and the other is soft labels (soft target) generated from the teacher network. Therefore, the objective function is a weighted average of two different objective functions. The first objective function is the cross-entropy loss between the student prediction and the soft targets, and the second objective function is the cross-entropy loss between the student output and the correct labels. The authors also mentioned that the best results were generally obtained by using a lower weight on the second objective function.
Some surprising results obtained from the paper are shown below, for further details, please refer to the original paper here:

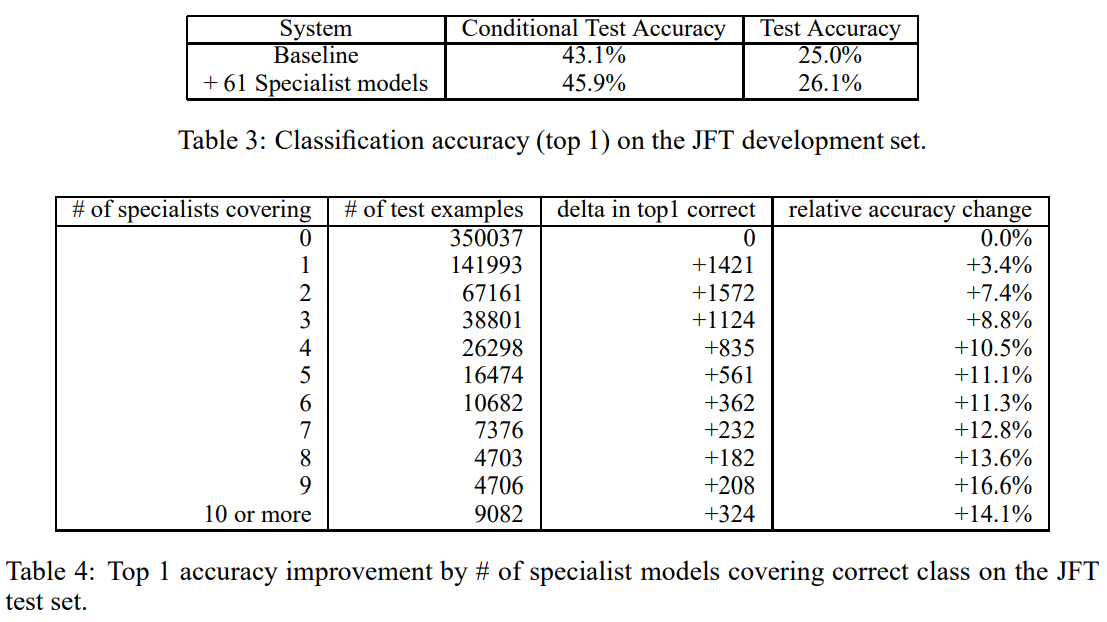
Knowledge Distillation for Object Detection
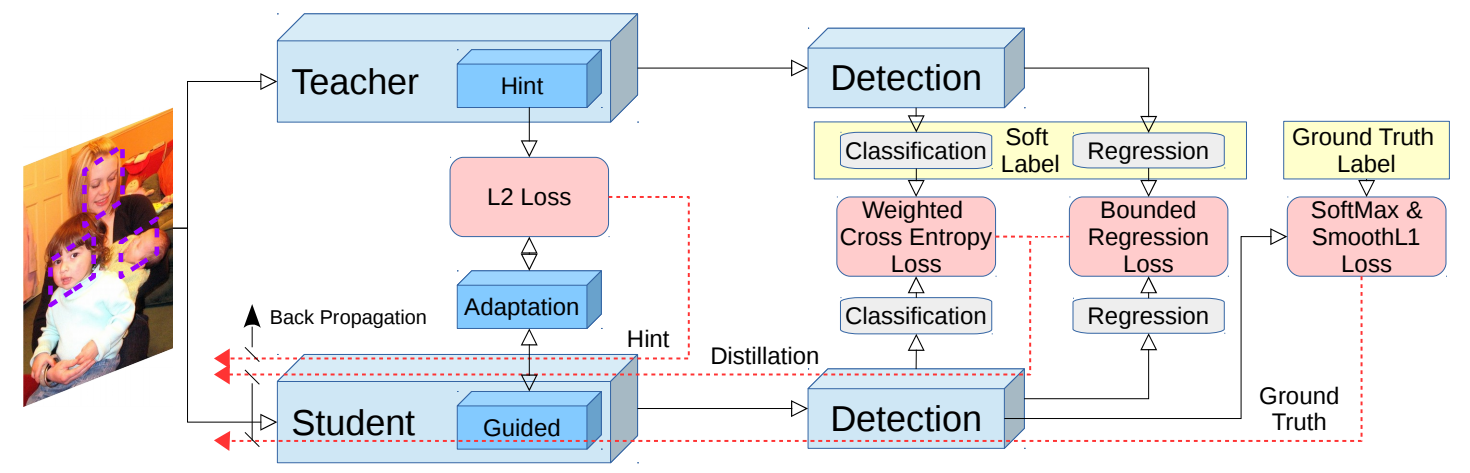
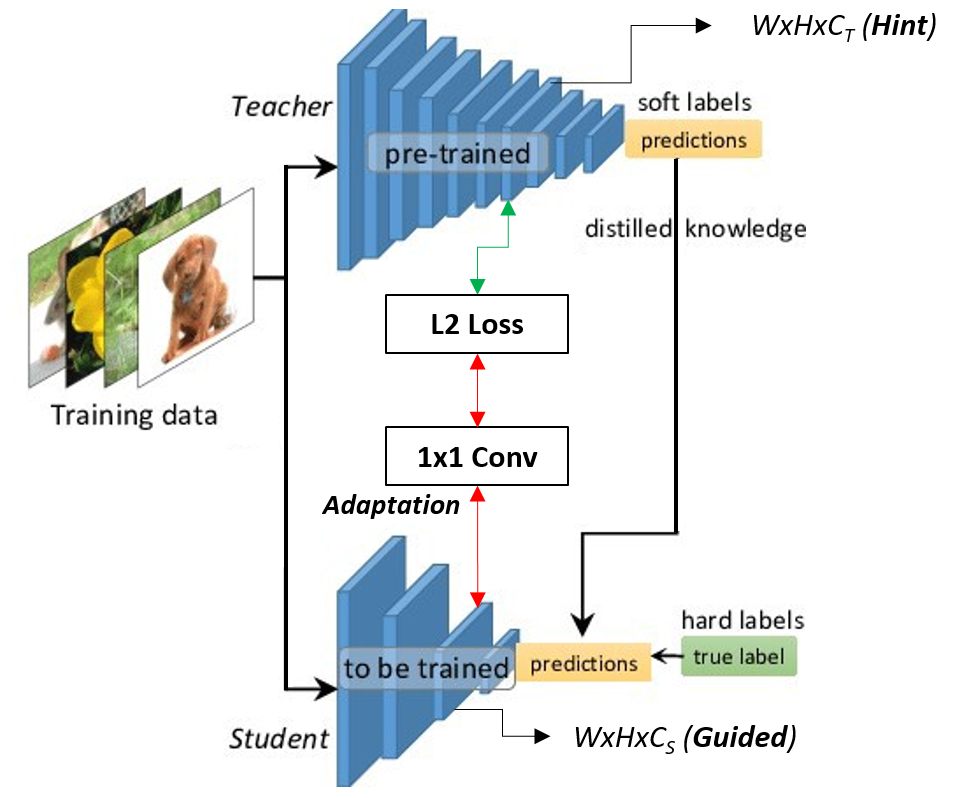
In NeurIPS 2017, Guobin Chen and his co-authors published their research on knowledge distillation combined with hint learning for object detection in the paper: Learning Efficient Object Detection Models with Knowledge Distillation. In their method, they further use a hint which is the feature map obtained from the intermediate layer of the teacher for guiding the student to learn the behavior of the teacher as closest as possible. Furthermore, an adaptation layer is necessary for the best performance of distilling knowledge, this adaptation layer will be discussed later. Faster-RCNN is the object detection network used for the experiment in the paper. Their learning scheme can be visualized as the figure below:
The learning objective function is written as below:
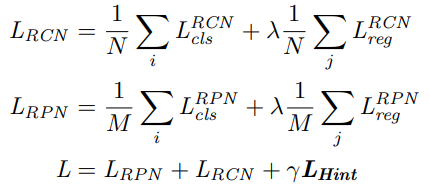
where RCN and RPN stand for regression-and-classification network and region proposal network, respectively; N and M are the batch-size of RCN and RPN, respectively; L_RCN, L_RPN, and L_Hint are the losses of RCN, RPN, and hint, respectively; λ (typically is 1) and γ (is usually set to 0.5) are hyper-parameters for controlling the final loss.
Hint Learning
Adriana Romero in the paper FitNets: Hints for Thin Deep Nets has demonstrated that the performance of the student network can be improved when the intermediate representation of the teacher network is utilized as a hint to help the training process of the student. In this sense, the loss between hint feature Z (the feature map obtained from the intermediate layer of the teacher) and guided feature V (the feature map of the intermediate layer of the student) is calculated using L1 distance,
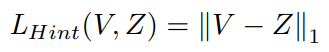
or L2 distance,
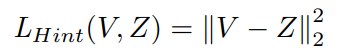
The following figures show the feature maps extracted from the pre-trained YOLOv4 model trained on the WAYMO dataset which is one of my projects regarding object detection with knowledge distillation. In these examples, the input image is resized to 800×800.


Knowledge Distillation + Hint Learning
The use of hint learning requires that the hint feature and the guided feature should have the same shape (Height x Width x Channel). Also, the hint feature and the guided feature will always not be in a similar feature space, therefore, an adaptation layer (typically is a 1×1 convolutional layer) is used to help to improve the transfer of knowledge from teacher to student.
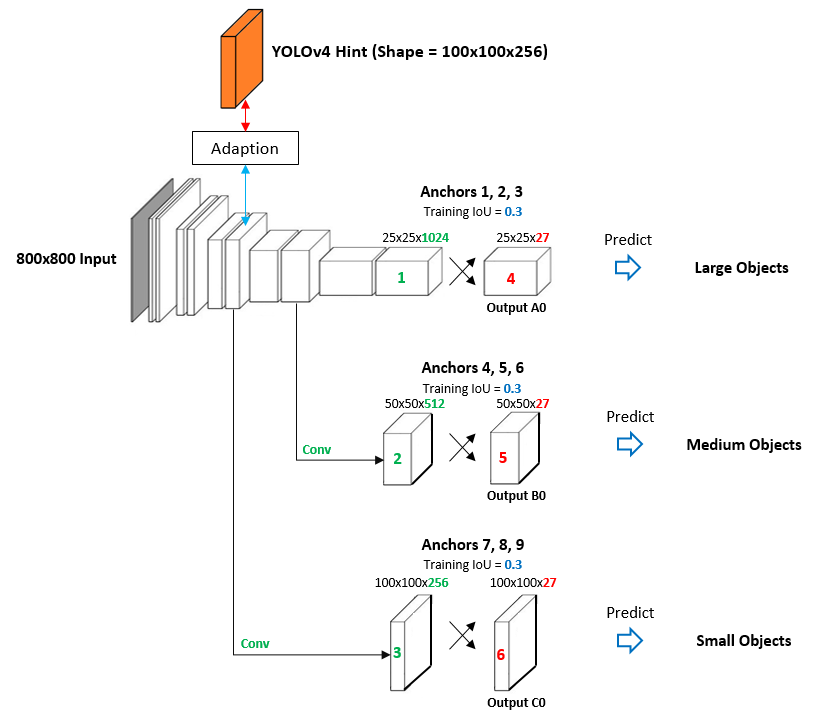
The figure below describes the learning scheme that I was working on in my object detection project, in which, I was using a small network with three levels of detection to distill knowledge from the pre-trained YOLOv4.
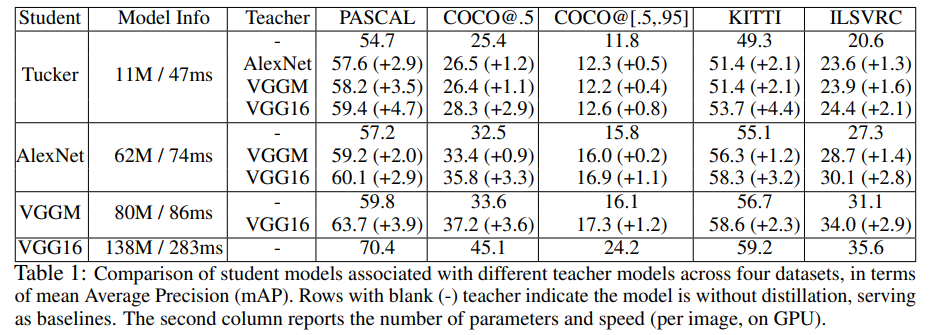
Guobin Chen shows excellent results when combining knowledge distillation with hint learning for object detection. For further details, please find in the original paper Learning Efficient Object Detection Models with Knowledge Distillation.
Conclusions
In this post, I have introduced briefly knowledge distillation and hint learning. Knowledge distillation is considered an efficient method for transferring the knowledge of an ensemble of cumbersome models into a smaller and distilled one. The combination of hint learning and knowledge distillation is a very powerful scheme to improve the performance of neural networks.
Readers are welcome to visit my Facebook fan page which is for sharing things regarding Machine Learning: Diving Into Machine Learning.
Thanks for spending time!
A Gentle Introduction to Hint Learning & Knowledge Distillation was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

