



900 Stars in 2 Weeks: Deepchecks’ Open-Source Release and Everything Leading Up To It
Last Updated on February 7, 2022 by Editorial Team
Author(s): Philip Tannor
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
Programming
A few weeks ago my team and I released a python package for testing machine learning models and data. This came with some valuable lessons that I thought were worth sharing, so here they are 🙂
❓Who Is This for❓
Turns out that even though many great packages are completely open to the public, it’s not so common for the individuals behind these projects to openly share about the “behind the scenes” of the release. This made it important to me/us to write a detailed blog about our experience.
✅ If you’re involved in an open-source project or tech entrepreneurship (or considering becoming involved), I think this piece will be useful.
❌ Otherwise, this probably won’t be worth your time.
👋 Introduction
A few weeks ago, my team and I released deepchecks, a python package aimed at building test suites for machine learning models and data. Before the release, we’d lowered our expectations, and assumed it would take a few months until deepchecks drew any attention. However, the release ended up being WAY more successful than we had imagined — and I decided to share some thoughts and lessons which I thought could be helpful for others as well.
A few things I’ll discuss in this post:
- Recap: Timeline from the founding of the company until the release
- Community: The importance of the professional community before and after our release
- The release: Metrics from the release and where deepchecks was featured
- Lessons: Lessons my team and I learned when preparing for the release, that I think can be helpful for others
- Improvement: Some things that we could have improved
- Vision: Refining our long term vision based on lessons learned
So here we go 😇:
Oh, and if you like what we’re doing, please consider ⭐starring us on GitHub⭐, and joining the discussion on our 👐Slack Community👐.
🕐 Recap
Ancient History: ML Monitoring as the Only Focus
Deepchecks has been around for a bit more than 2 years. My team and I were always passionate about building a product that would really impact the everyday lives of machine learning practitioners and would turn into a “household name” for data scientists. That’s really part of what drove my co-founder (Shir Chorev) and me to tackle this problem, and I think it’s also a major part of what made our founding team members passionate about hopping on board.
Nonetheless, for ~1.5 years we’ve focused most of our development resources on an ML monitoring solution, which is meant for enterprises that have deployed ML models into production. The reasons for this were obvious:
- This is the main pain point you’ll hear about when speaking with AI leaders within enterprises.
- Companies are willing to pay for this and don’t necessarily feel a need for in-house development of this
While this approach does touch on one of the most obvious problems in MLOps heads-on in production, we saw that this pretty much guarantees us a slow and clumsy process😞. It typically requires an internal champion to tentatively authorize both a budget and an OK from IT/InfoSec before we could even start a POC and before they could start experiencing the value… This felt too far away from our goal, to find the path to becoming a “household name”.
ML Validation “Pilot” (that was put on standby)
About this time last year (~January 2021), our algo team started working on a side project meant for ML validation. The idea was simple: A user would upload their model and data to our website and could download a report summarizing many different aspects. This is what this “pilot” version looked like:
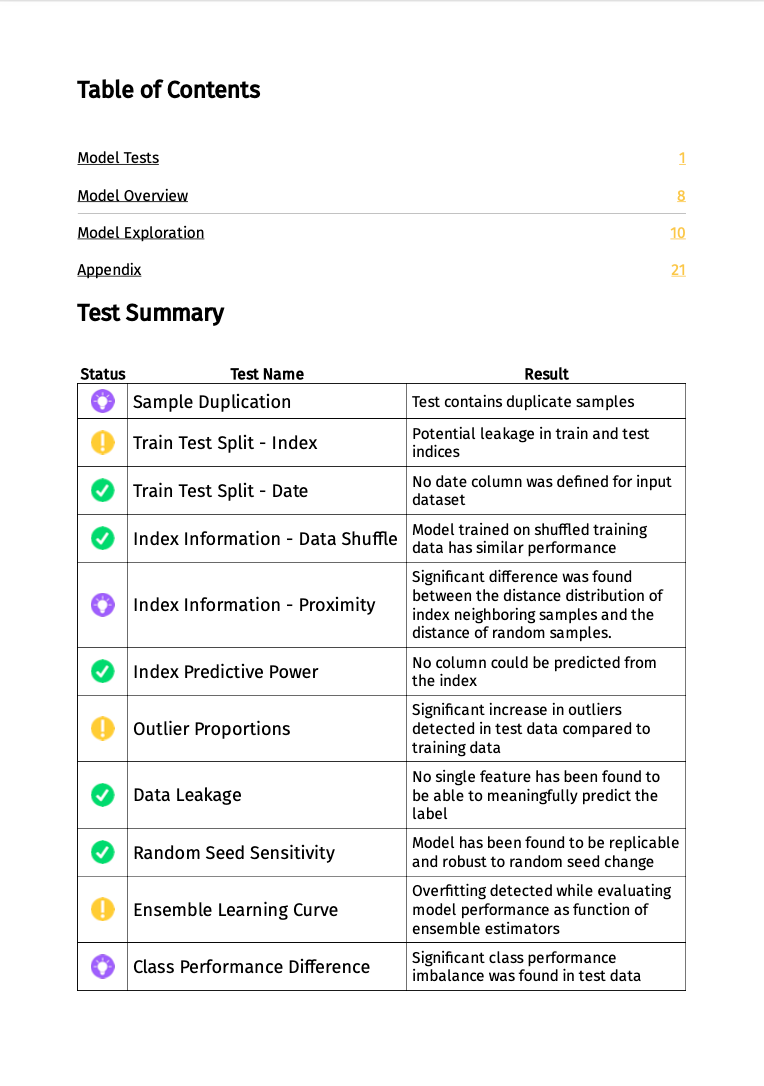
We ran user interviews with 4–5 data scientists and received mixed feedback🤔. They all liked the idea but had a lot of interesting input:
- What if I want to customize my report? Or just add one custom check?
- Do I have to upload my data to your server? And if it’s on-prem, how will it be deployed?
- Can I get it as a python package?
After intensive internal discussions, we’d reached the conclusion that even though this project seems promising, it will require a ton of work for it to take off, and it just seems too separate from the ML Monitoring to have our teamwork on both of them simultaneously. So we put it on standby.
However, I think none of us dismissed the potential in this idea. And at least at a personal level, this “pilot” never left my mind for a second. I felt that this could be used by a much wider population than the ML monitoring audience — students, data scientists working on a model that hasn’t been deployed yet, and more. So every time we had a significant product roadmap discussion, the possibility of “reviving” this project would come up.
The Breakthrough & the Hackathon
During September 2021, about 8 months after we had put the validation project on standby, we had a “dream come true”. Our team had a breakthrough that would enable us to use the same infrastructure for offline validation and for production monitoring.
The idea was pretty simple and is pretty much along the lines of the deepchecks package you know (and love 😉 ❤️). Here are the main parts of the idea:
- The ML Validation module should be a python package and not an automatically generated PDF report. If the user wants to, the results can be downloaded as a report.
- The python package has to be open-source so that:
-It can be used on-prem, in settings that include sensitive data.
-The community can contribute checks and test functions of their own. - The reports will be built by different types of test suites in which each test suite will correspond with a certain type of use case.
- The customizability of the suites will be obtained by having different functions that can be added, removed, or customized.
- Dashboards and alert policies for our ML monitoring system can be easily configured using suites from the same python package as the ML validation package.
This was potentially huge news for us if we could get it to work. We could finally enable our team to work on the testing/validation use case, while not having to take into account that it’s a separate project that may distract us from our main path.
So we decided to test this out, and have significant internal discussions about if & how this may work. But up to this point, only the algo team was involved. So how could the other team members intelligently express their opinions and say what they think is a good or bad idea? Our solution — get everyone involved.
We kicked this off during October with a three-day company-wide hackathon (followed by a company day off =]). And the results were INCREDIBLE. After a week of preparation and the three-day hackathon, we had a working, presentable, demo that did exactly what we imagined. And the initial feedbacks were very positive, or at least as positive as you can get from a fairly preliminary package.
(Interesting anecdote – at the end of this hackathon, the name of the package was ‘mlchecks’ and not ‘deepchecks’)
Clear Release Date, “Silent Release”, Mini-Deadlines
After the feeling of a success story from our short experiment, we’ve gained enough confidence to make a bold move. Aside from deciding to open-source a lot of our existing IP, we decided to allocate the vast majority of our resources (>80%) to the open-source effort for the next few months. The only thing left to do was to set a date for the release.
The release date we chose was ~3 months away: January 6th, 2022. Why? Our considerations were fairly arbitrary. We thought that 1.5 months wasn’t enough time, and we didn’t want to release the package too close to the holiday season. In any case, having a clear release date that the whole team takes very seriously, was a really good experience.
Here’s how we tackled the preparation for the release date:
- Fail/Pass Criteria: We decided that our core focus during this period of time was to surpass a certain threshold of how positive user feedbacks were. The fail/pass criteria we decided upon was pretty straightforward: We needed to get the majority of the users that tried out the package to respond positively to both of these questions (that we always asked):
-If you had come across this package without knowing us, would you use it?
-Would you recommend it to a friend?
And as long as this wasn’t the case with a specific person/group, we knew that we had work to do. - Silent Release: Since our focus was on authentic user feedback, we wanted to make sure that their experience will be as close as possible to “the day after the release”. So we had a “silent release” about a month before the package was ready, and users got a direct link to the repo. We just kindly asked all of the beta testers not to distribute the package before the release date.
- Mini-Deadlines: Let’s mark the release date (January 6th) as ‘T’. Having just ‘T’’ as one huge deadline that’s a few months away wouldn’t have been a great strategy for us. Since our main goal was to do better on the pass/fail criteria regarding user feedback, we set mini-deadlines related to this:
💻 Collect feedback from dozens of users/beta testers on ‘T-10’ (10=number of days prior to the release), in order to prepare for the release. The days after the feedback collection were to be blocked out for fixing bugs or other complaints from beta testers. And if after the fixes we don’t pass the pass/fail criteria, we should consider postponing the release deadline.
💻 Collect feedback from a couple of teams at ‘T-20’, but this time the idea isn’t to prepare for the release but rather for the ‘T-10’ event. If needed, we would learn that we need to postpone the ‘T-10’ deadline.
💻 Collect feedback from a few individuals “friend and family users” at ‘T-30’ — to prepare for the ‘T-20’ event.
You probably get the idea of our mini-deadlines by now 😉. But what I was very impressed about in the way our team worked was that we didn’t have to move any one of these events. Everything happened exactly according to the schedule, so the release date remained on January 6th and didn’t even move by one day.
To be honest, I think that being exactly on time wasn’t just “magic” and great planning. I think the schedule was challenging but achievable, and once our (amazing) team members bought into the goals & mini-deadlines (we all built them together) they felt committed and did what it took to make them happen.
🏘️ Community
Community Story, Not a Deepchecks Story
Before I dive into the numbers, I think this is a great opportunity to thank the community for such a great start. I was dumbfounded by how much support and energy my team and I have received from you all. The endorsements, ideas & feedback have been extremely meaningful and gave us enough confidence to continue to pursue to tackle this problem in its open-source format. So in the following section, I’ll brag about some metrics — but I think it’s worth clarifying that it isn’t the story of me that I’ll be telling. Or even the story of my colleagues at Deepchecks. It’s really a story of the community (that means you!).
Here’s the community story I can relate with:
Some solutions for testing/validating ML have begun to emerge, but most of them are in a “talk-to-us-and-we’ll-show-you-our-amazing-but-secret-solution” type format. This can work fine for other industries, but the ML community typically tries to avoid that type of solution if they don’t really have to (yes — even DSs at banks and pharma companies). So in the meantime, the typical ML practitioners just write their own tests, which is a crazy amount of work (+requires seniors). So de-facto, there’s a significant missing component in the ML stack, and it’s becoming increasingly important.
Along comes a company (us) that wants to have a win-win relationship with the community and solve this problem. The company spends dev resources on the open-source even when there is no immediate ROI, and the community helps out wherever it can with open-source love: Ideas for features, positive reviews, contributions, and spreading the word.
This “community story”, it’s not about the company named Deepchecks or “our pretty eyes”. It’s about the community rewarding those that are helping to empower it. This is merely the community’s mechanism of “self-preservation”. Simple as that. For the same reasons, I believe that individual members of the community will also prefer to work with deepchecks rather than a “non-community-focused” company when an enterprise deal comes up.
⌚The Release
Metrics From The Release
Without further ado, let’s dive into the numbers, starting from the “star history”:
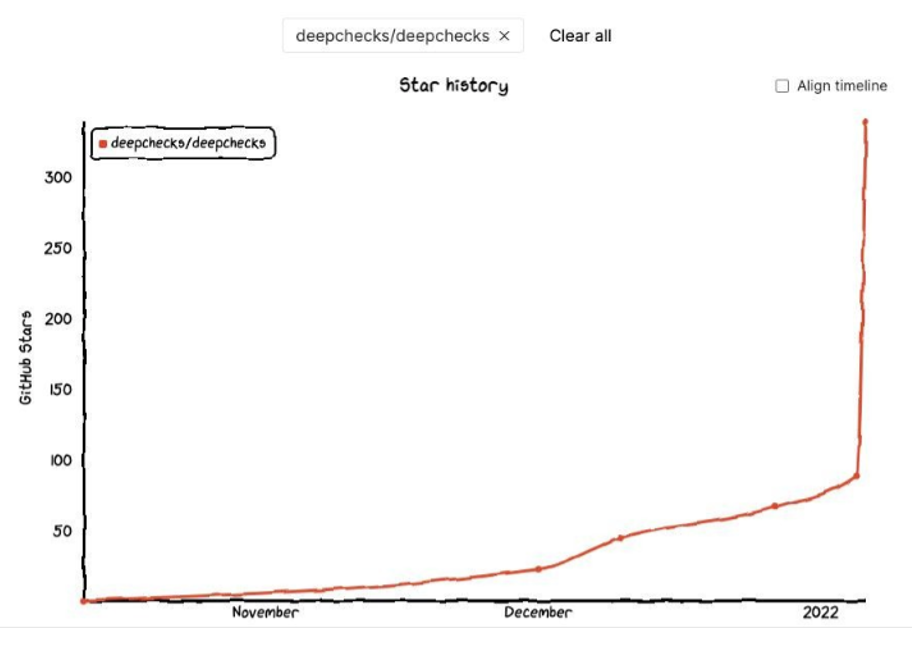
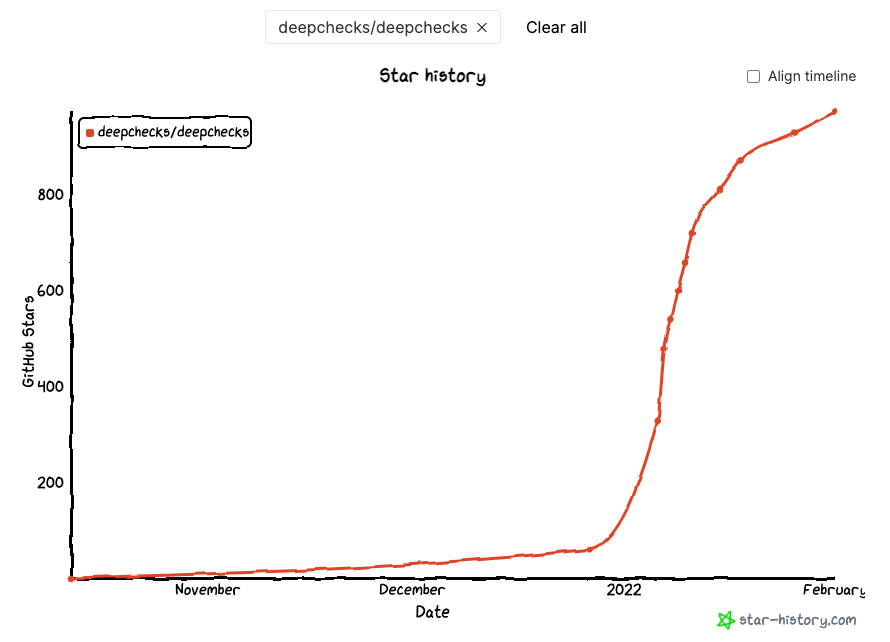
As you can see, deepchecks climbed from 100 stars to ~350 stars on the day of the release and reached ~900 stars within about 2 weeks. As I’m writing these words, we’re at ~970 stars (3+ weeks since the release). Pretty impressive for a brand new package!
Unlike stars, downloads are really hard to measure. There could be a huge organization with thousands of users that will count as only one download… You have to deal with bots, mirrored downloads, multiple download mechanisms, and more. In any case, here are the download stats that originate in PyPI (no bots, no mirrors):
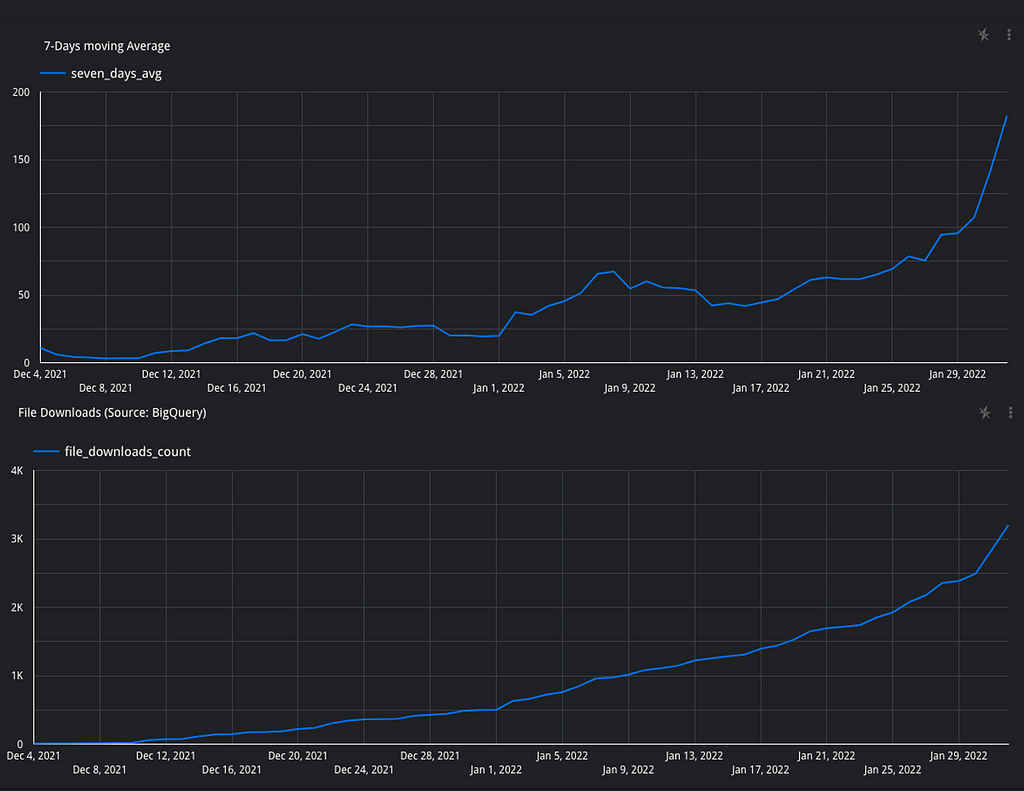
From what we can tell, it seems like the distribution had a very interesting mechanism. It seems that many people saw the package, starred it, sent it to friends, but actually waited for a while until they downloaded it and tried it out on their own dataset.
So where are the users from? To get an estimate, we can look at the stats from Google Analytics on our documentation site:
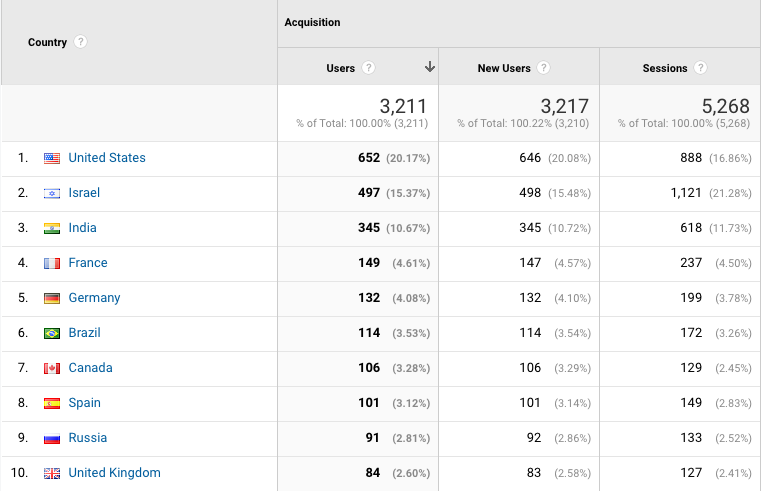
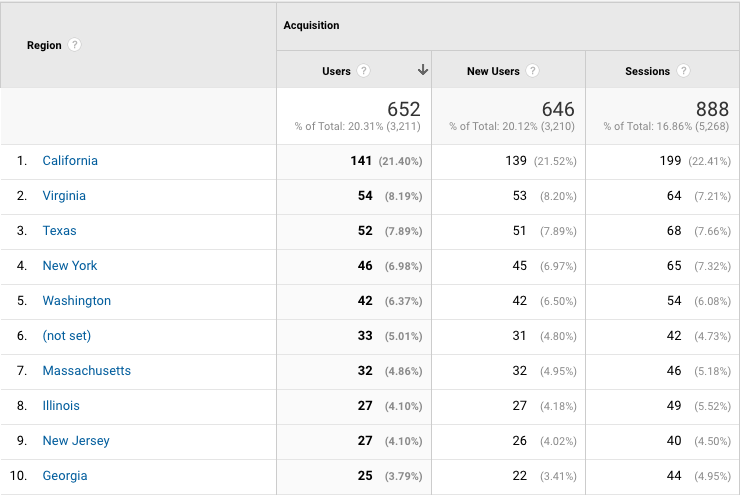
A few comments/questions about these stats (I know that the numbers are too small for statistical significance but it’s still fun😀):
- The US seems to have the most usage, but Israel has more total sessions. Could that just be because the core of our own R&D team is in Israel?
- Where is China?! They are so dominant in AI/ML conferences, but nowhere to be seen in our docs… Did nobody tell them about deepchecks? Or are they just so far ahead that they don’t need the docs? And we can ask a similar question about Russia that did provide some traffic, but less than some much smaller countries like Spain and France.
- What’s special about Virginia, do they have a lot of ML going on? Or is this some specific group/course related to ML? Also, pretty cool that Texas is ahead of New York, Washington, and Massachusetts. I wonder if it will stay like this over time.
So Where Was the Package Featured?
We were honored to have deepchecks featured in quite a few interesting places. Some of them were really early on and helped us gain some early traction and stars, while others were important in giving us more detailed feedback (or an additional “approval stamp”). I’ll go through the different categories, starting from the LinkedIn posts:
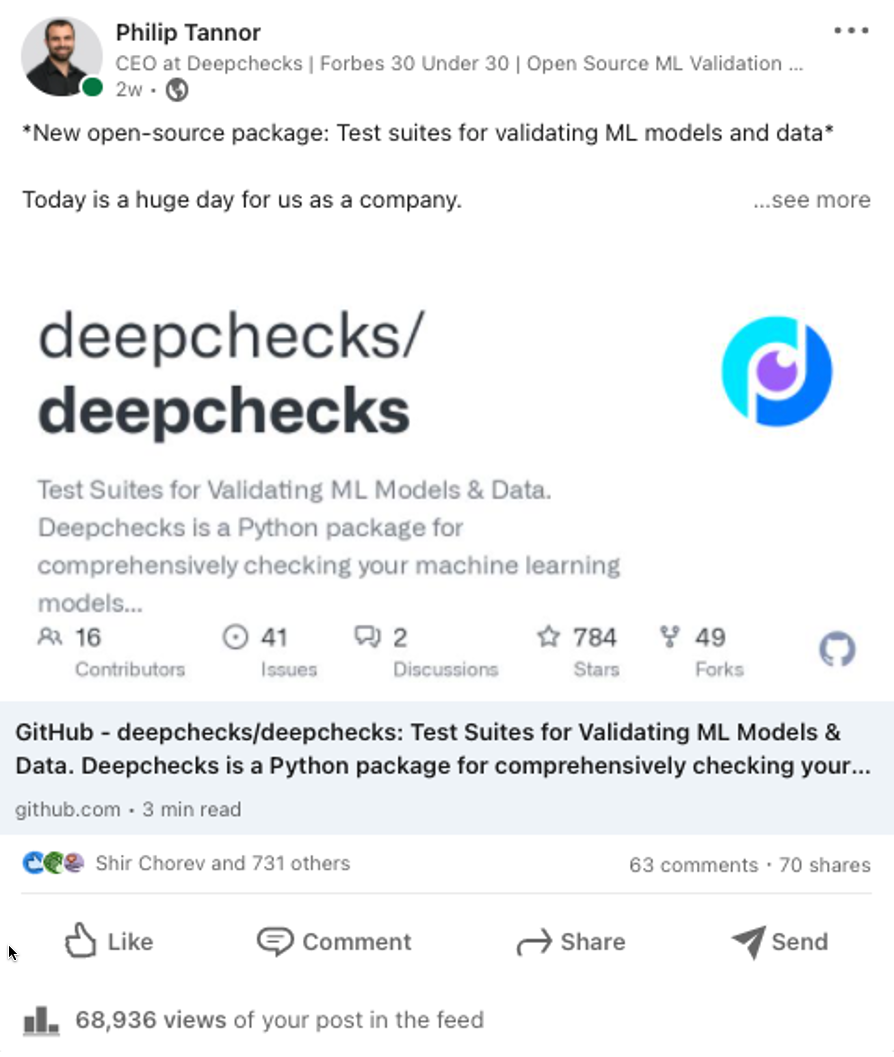
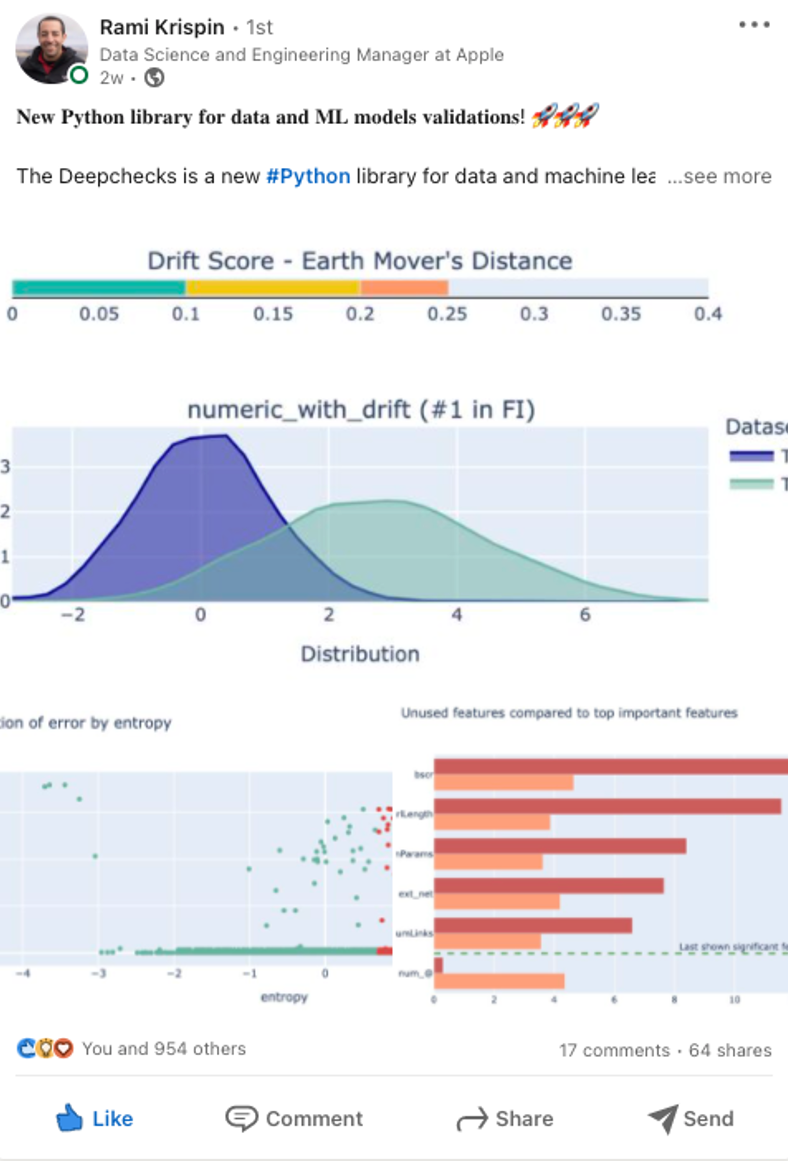
LinkedIn posts were the primary source of the traffic to the deepchecks repo. These are the two most notable ones, but there were also many other posts by colleagues and community members.
We also had a pretty significant Reddit post, written spontaneously by Itay Gabbay from our R&D team on the day of the release:

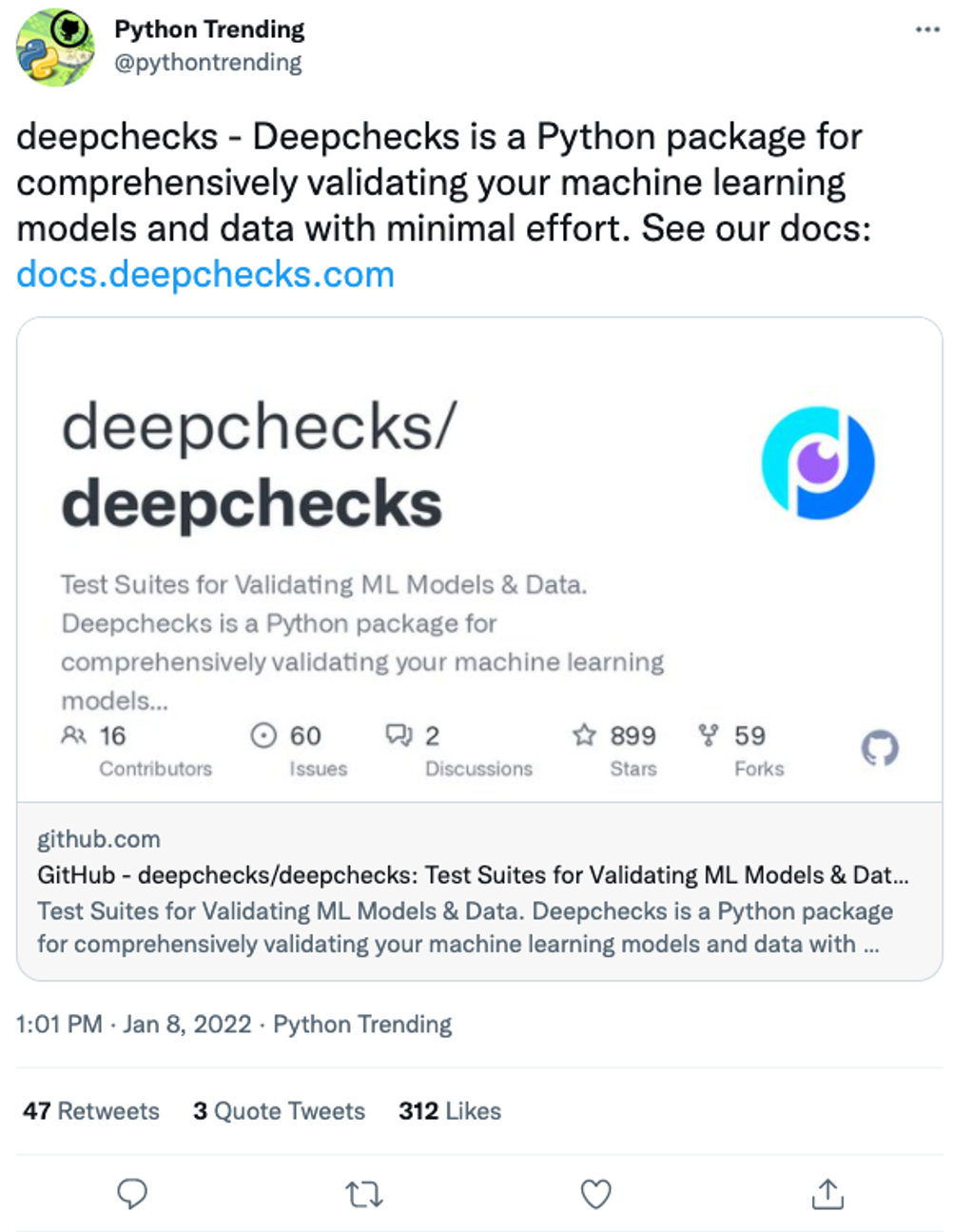
A couple of days after the release we were delighted to see that deepchecks was featured on GitHub trending (for python). And we were there for three consecutive days… This also had an impact on the repo’s incoming traffic, both from the list on GitHub and from this Tweet:
We were also featured in newsletters and posts by thought leaders. See for example:


The package got featured on “ML News” by Yannic Kilcher:

And deepchecks was even featured twice on Towards Data Science, by authors we’d never met before:
🤗 As you can probably tell from my writing tone, I’m EXTREMELY satisfied with these results🤗. We still have a lot to work on, but these metrics are all far better than my team and I anticipated. I think that the main reason for the release going so well was listening to community feedback and implementing it. However, I realize that recommending “listening to users” is a pretty generic piece of advice, and I think there are more specific lessons learned that I’d like to share with the community.
🏫 Lessons Learned
Here are the main lessons my team and I have learned from releasing this open-source package:
- The importance of the README + docs: For open-source projects, the README, docs, and structure of the repo are just as important as the code/product itself. It turns out that many people know this, but we didn’t. We learned this during our feedback sessions with users. Our initial plan was to have no docs for the initial release (README only). Then we learned from user feedback that we need at least minimal docs. After that, we saw that improving the docs+README was having a larger impact on the overall user experience than actual code changes…
Interesting anecdote: The day before the release, I looked at our docs and became a bit anxious. We’d previously discussed a few major changes, and I saw they weren’t yet in place. But I told myself it’s too late and we should just make the best of what we have (so I didn’t tell anyone about my concerns). To stress me out even more, on the morning of our release, our CTO Shir Chorev slept in (and when I called her said “OMG, I didn’t wake up”). But turns out she worked on the docs all night 😆. And I think the changes she made were very important for the success of the release. - Short time to value is key: It took us time until we formalized this for ourselves, but one of the key metrics you want to optimize for to get to fast word-of-mouth growth is the time it takes until initial value. Sounds trivial, but there are a million things to optimize and for OSS projects and similar this may be the top one.
- Mini-deadlines were a great way to work: As described at the beginning of the post, having these clear, frequent, deadlines with measurable outcomes was really amazing. I don’t think this is always possible, but when it is — it can be really great for productivity.
- Sunlight makes us improve ourselves: I really feel that our standards are higher since our code was open-sourced. Knowing that everyone out there (including critical people) can see exactly what we’re doing just makes everyone be the best version of themselves.
📈 Improvements
- Twitter: Social media played a significant part in spreading the word about the deepchecks package. For the last couple of years, I’ve been spending a lot of time on LinkedIn, and it definitely paid off during the release. However, I’ve just begun to learn that Twitter is just as important. But after neglecting my Twitter account for so long, it turns out that my Twitter account is just sad. Look how bad my numbers were on “release day” despite the big news (7 likes, <3 retweets):
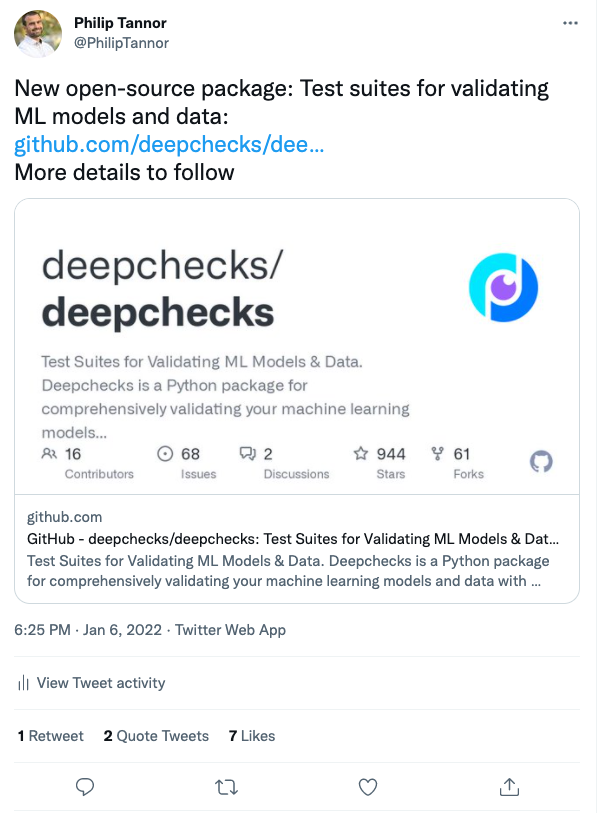
(BTW, about this Twitter account problem — I’m now accepting pitty followers if you’re up for helping a good cause: https://twitter.com/PhilipTannor)
2. Deepchecks community voice yet to be found: Transitioning from a “classic sales” company to a community-focused company requires many significant changes. But one of them is finding our “tone” for speaking with the community, which conveys that we’re really collaborating in a way that should benefit both the community and the company. We’re still figuring this out, and we still have to make sure that none of our messaging comes out more “sales-y” than it should be.
BTW part of the solution could be hiring a community manager/DevRel 🧑💼. Please let me know if you or anyone you know may be a fit for this.
👓 Conclusion & Long Term Vision Refined
When our OSS package was still very ״draft-y״, I didn’t really know what the community potential was. But we’ve learned a lot over the last few months, and as I wrote in the “Community” section, I think there is a lot of potential in a collaboration between the ML community and Deepchecks (the company).
I believe that the deepchecks open-source package has the potential to become a “household name”, that will be part of the workflow of every ML practitioner, from university students to the most senior Data Scientists in large enterprises. Deepchecks can really turn into a synonym for “testing Machine Learning”, and will hopefully be used as a verb in professional conversations between Data Scientists. And I think that the community would benefit tremendously from having a common language & standard protocol for ML testing & validation…
As we continue to expand the package from Tabular data to computer vision and NLP and from Jupyter notebook outputs to other formats, I think this vision is beginning to seem more and more realistic.
Will this actually happen or just remain an unfulfilled dream? 🛌🏾
Truth be told, that depends more on 👉 your 👈 actions(=the professional community) than it does on mine.
Philip Tannor is the co-founder and CEO of deepchecks, the leading company for continuously validating machine learning systems and data. Philip has a rich background in Data Science and has experience with projects including NLP, image processing, time series, signal processing, and more. Philip holds an M.Sc. in Electrical Engineering, and a B.Sc. in Physics and Mathematics, although he barely remembers anything from his studies that doesn’t relate to computer science or algorithms.
(OK, my father, that’s a Quantum Mechanics Professor, requested that I clarify that that’s just a joke. I do like ML more than physics 🤗, but you can still ask me about Bernoulli's principle or Maxwell’s equations. Just don’t surprise me on a podcast!)
900 Stars in 2 Weeks: Deepchecks’ Open-Source Release and Everything Leading Up To It was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

