


![[2019-CVPR] D2-Net: Matching Problem among Images Under Extreme Appearance Changes](https://miro.medium.com/v2/resize:fit:1800/1*YTRPXUakFV6cA92PwHYjbw.png "[2019-CVPR] D2-Net: Matching Problem among Images Under Extreme Appearance Changes")
[2019-CVPR] D2-Net: Matching Problem among Images Under Extreme Appearance Changes
Last Updated on July 24, 2023 by Editorial Team
Author(s): YoonwooJeong
Originally published on Towards AI.
This article is based on the paper ‘D2-Net: A Trainable CNN for Joint Description and Detection of Local Features,’ which is published in 2019-CVPR. For further read, refer https://arxiv.org/pdf/1905.03561.pdf
This paper introduces a state-of-the-art method for the matching problem in extreme condition changes, especially on specific datasets. It was a challenging problem to create a general matching algorithm under challenging conditions. This article summarizes the paper so that you can easily understand the fundamental concepts of the paper.
What is the matching problem?
A matching problem is a general approach to find correspondence between two images. For the human aspect, it is an easy problem to recognize equal points between two images. However, for the computer aspect, since the computer recognizes an image as an array of pixels, the matching problem is quite challenging.
The main contribution of research that is related to the matching problem is to find an algorithm that extracts correspondences between two images. The image below shows an example of the matching problem.

The matching problem was strongly affected by SIFT(Scale Invariant Feature Transform)(2004), which was the state-of-the-art feature extraction for a long time. After the deep-learning generation, researchers discovered tremendous methods for feature extraction. Thus, until now, the matching problem is explorable in the Computer-Vision area.
Why is this research needed?
Previous works discovered many methods that work well for the matching problem. However, the methods lack robustness in challenging conditions. This research focuses on pixel-level correspondence under various image conditions. The conditions can be either day/night difference, season changing, and weakly textured scene.
Previous works distinguish the feature detector and the feature descriptor so that it is called the detect-then-describe approach. They first detect the features in images and create patches around the detected keypoints. Then, using feature descriptors, specify the features such as making an N-dimensional vector. However, this approach has a limitation: the local descriptors consider larger patches and potentially encode higher-level structures, the keypoint detector only finds small image regions. Thus, the methods suffer from significant performance drop in extreme appearance changes.
This research proposes a describe-and-detect approach: rather than performing feature detection early on low-level information, simultaneously create feature detectors and feature descriptors. It used CNN architecture to generate feature maps whose backbone is VGGNet. (VGGNet is more illumination-invariant comparing to ResNet)

Feature Extraction
As explained above, D2-Net uses CNN layers for feature extraction. For implementation details, the writer recommends you to read the original paper. It finally outputs a 3D Tensor F.
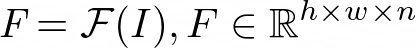
h, w is a spatial resolution of the feature maps and n the number of channels. Then each of the vectors in (i, j) is used as a descriptor of such location. They denote the descriptor as d.

During the training stage, these descriptors will produce similar values for the same scenes regardless of extreme condition changes.
Each channel is a detector of the features.

The point (i, j) is detected if and only if (i, j) must be the local maximum in channel k that is the maximum value in location (i, j) among the channels in tensor F.
How to Design Loss Function
To achieve the goal, designing a loss function is the most crucial part. The loss function must be high-value when our necessary condition is not fulfilled, must be almost zero when our necessary condition is fulfilled. We can summarize conditions that must be satisfied.
(1) The detected point tends to be local-maximum in its neighborhood.
(2) The detected point tends to be the maximum among the same location in different channels.
(3) The corresponding points will be similar. i.e., The corresponding point will have less euclidean distance.
(4) The neighbor of the corresponding points won’t be similar. i.e., The neighborhood of corresponding will have high euclidean distance.
Thus, the network uses a detection + description metrics for the loss function.
Soft-Feature Detection
To make a network end-to-end, it uses soft local-max, which is differentiable.

The soft local-max is calculating how much it is discriminative among its neighbor. As it is discriminative compared with the neighbor, it returns the larger value. However, if it is not discriminative enough, it returns the smaller value. The next metric used is the following.

The metric is using the ratio-to-max method. It is calculating whether it is close to the maximum among the same position in different channels. Then it is maximized to obtain a single score map.

And it is finally done by image-level normalization.
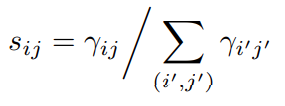
Then, this score will be high when condition (1) and (2) is fulfilled, which is introduced above.
Descriptor Distance
There are two distances, which will be the main: the positive descriptor p and the negative descriptor n. Let’s denote c as a correspondence between pixel A and pixel B.


The positive descriptor p estimates the similarity between pixel A and pixel B. To make correspondence c more confident, the score must be small enough. The negative distance n calculates the similarity between pixel A and pixel B’s neighbor and also calculates the similarity between pixel B and pixel A’s neighbor. However, if the neighbors are adjacent pixels, the matching problem is an extremely challenging problem. Thus, this paper provides a hyper-parameter K that is working as a tolerance to ease the matching problem.

Then finally, the margin function is designed as

This margin satisfies requirements (3) and (4). Because wrong correspondence will make higher p and lower n, it’ll be an excellent metric for correspondences. Finally, the loss function is designed as a combination of margin function and image-level normalized score.

Results
Introduced evaluation protocol is considering a match is correct only if the reprojected point by homography is inside the threshold. The experiment was done in various thresholds to check the performance tendency.
- Comparing with previous matching algorithms, it has lower performance in location accuracy with a tight threshold. This experiment is done over the HPatches dataset, which is a be, benchmark on the matching problems. Since CNN is performing both descriptors and detectors, individual performance can be dropped. The latter use of detectors misses the low-level blob-like structures, which are better localized than higher-level features.
- However, with a loose threshold(6.5pixels or more), D2-Net outperforms other matching algorithms. As shown in the figure below, it is invariant on illumination changes and viewpoint changes.
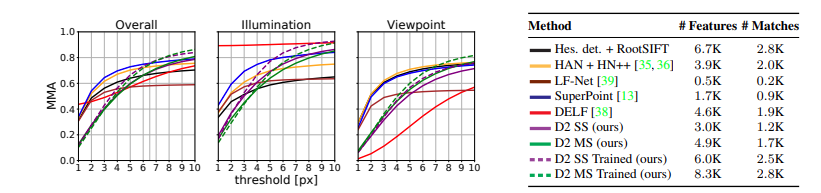
3. Even though D2-Net has a lower performance under tight thresholds, it is sufficient to build 3D reconstruction(Building a 3D model based on images). The authors used ‘Madrid Metropolis;, ‘Gendramenmarkt’ and ‘Tower of London’ datasets. Even though D2-Net has less accuracy comparing with previous works, it was not a significant drop. Performance drop is because the 3D reconstruction task requires well-localized features which are failed in image matching.

4. This paper also checked localization performance under challenging conditions. D2-Net outperformed the localization problem in both the ‘Aachen Day-Night’ dataset and the ‘InLoc dataset.’

Conclusion
The describe-and-detect methodology is state-of-the-art on localization problems. However, it still has a limitation on the image-matching problem and the 3D reconstruction problem. The research is meaningful because it suggests a new methodology in the matching problems.
For Contact: Mail me
jeongyw12382@postech.ac.kr
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

