


")
1. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (The first NeRF)
Last Updated on July 20, 2023 by Editorial Team
Author(s): YoonwooJeong
Originally published on Towards AI.
Computer Vision
10 NeRF Papers You Should Follow-up — Part 1
Recommending 10 papers to NeRF researchers. Part 2 will be soon available.
Humans generally acquire most information from the eyes. Computer vision has shown successful performances in many tasks, reducing manual labor when dealing with visual data. Recently, visual rendering has been one of the most popular areas in computer vision. NeRF, an abbreviation of Neural Radiance Fields, has shown incredible performance in rendering, resulting in reliable and realistic rendering in real-world scenes. For researchers, a paper with a strong impact involves great interest; however, it is difficult to follow up due to exploding number of variants. In this article, we are going to dive into NeRF and summaries of follow-up papers. This article is focused on introducing variants of NeRF. Here is the list of papers that are introduced in my article.
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- NeRF++: Analyzing and Improving Neural Radiance Fields
- NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
- NSVF: Neural Sparse Voxel Fields
- D-NeRF: Neural Radiance Fields for Dynamic Scenes
- DeRF: Decomposed Radiance Fields
- Baking Neural Raidance Fields for Real-Time View Synthesis
- KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs
- Depth-supervised NeRF: Fewer Views and Faster Training for Free
- Self-Calibrating Neural Radiance Fields
Paper Link: https://arxiv.org/abs/2003.08934
Author: Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, Ren Ng
Conference: ECCV20 (Best Paper Honorable Mention)
Description
- The first paper proposes NeRF architecture. They handle view-dependency problems. Objects have a different color depending on their viewing direction due to properties of the light, such as reflection, by receiving the viewing direction as input.
- Given a position vector and a viewing direction in canonical space, the network outputs color and volume density. The illustration below visualizes the network architecture.

- The model is designed end-to-end. For each ray from training images, the model renders the ray's color by weight-summing colors with volume density for points in the ray sampled by stratified sampling. For details, we recommend referring to the paper. The training objective is the L2 difference of predicted color with the ground truth color of each ray.
- They adopt two strategies for stable and effective training, namely, hierarchical volume sampling and positional encoding.
2. NeRF++: Analyzing and Improving Neural Radiance Fields
Paper Link: https://arxiv.org/abs/2003.08934
Author: Kai Zhang, Gernot Riegler, Noah Snavely, Vladlen Koltun
Conference: arXiv20
Description
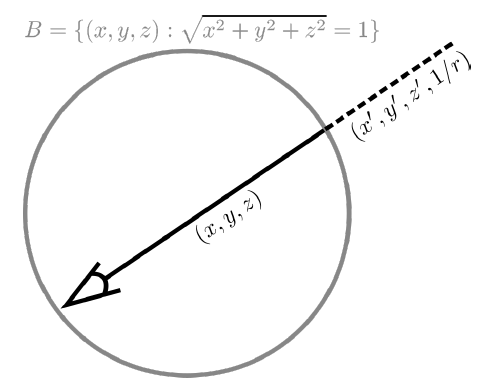
- Motivation: The original NeRF has difficulty rendering outdoor scenes due to the ambiguity of setting background depth. In other words, NeRF is incapable of rendering unbounded scenes. NeRF++ addresses this problem by separating foreground and background sampling.
- They set the unit sphere to separate the foreground and background of scenes. For the points in the foreground, that is to say, points inside the unit sphere, they follow the same method from the original NeRF. However, for the points in the background, that is to say, points outside the unit sphere, they reparameterize the coordinate with its distance. As a consequence, the foreground network receives 5-dimensional inputs; however, the background network receives 6-dimensional inputs.


3. NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections

Paper Link: https://arxiv.org/abs/2008.02268
Author: Ricardo Martin-Brualla, Noha Radwan, Mehdi S. M. Sajjadi, Jonathan T. Barron, Alexey Dosovitskiy, Daniel Duckworth
Conference: CVPR20 Oral
Description
- Motivation: Although NeRF has greatly impacted the rendering tasks, it requires image collections that are captured in static conditions, negligible illumination changes, and no transient objects in scenes. In contrast, NeRF-W enables reliable rendering from unconstrained photo collections, especially gathered from the Internet.
- The proposed model separates static and transient objects during the rendering process. Since the transient objects are not certainly located in their current poses in different scenes, their model computes the uncertainty of rays. Then, based on the computed uncertainty, their model focuses less on rays with high uncertainty.
- In my personal opinion, defining an evaluation metric on unconstrained photo collections is a challenging and controversial problem. This paper nicely proposes an evaluation metric with convincing intuition. For more information, I highly recommend reading this paper.
4. NSVF: Neural Sparse Voxel Fields

Paper Link: https://arxiv.org/pdf/2007.11571
Author: Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, Christian Theobalt
Conference: NeurIPS20 (Spotlight)
Description
- Motivation: Boosting inference time is a key challenge that NeRF should overcome. They point out that the last points in rays are not necessary when accumulated alpha values are almost 1. Moreover, for parts in the canonical space that has less volume density, we could omit the rendering. The authors experimentally demonstrate their inspiration in various datasets.
- Starting from a large voxel size, the proposed model prunes voxels whose volume densities are below a certain threshold. Then, it decreases the size of voxels. Repeating the aforementioned processes, they acquire a voxel octree with a small voxel size. During the inference time, they skip rendering a point when the point is located inside the pruned voxel. In addition, they adopt an early ray termination which omits to render when the accumulated alpha value is above the threshold.
- Well-written paper. The idea here encouraged future work to improve the inference time of NeRF.
5. D-NeRF: Neural Radiance Fields for Dynamic Scenes

Paper Link: https://arxiv.org/abs/2011.13961
Author: Albert Pumarola, Enric Corona, Gerard Pons-Moll, Francesc Moreno-Noguer
Conference: CVPR21
Description
- Motivation: D-NeRF enables the rendering of dynamic scenes. The proposed model only requires a single view for each timestamp, indicating it is highly applicable to real-world rendering.
- The idea is very simple. They add a network called deformation network that predicts the positional difference in a specific time of a certain location. With estimated location by the deformation network, the canonical network predicts colors and volume density.

- The idea is simple and intuitive. The work is meaningful since it enables rendering videos with a single view for each timestamp. I hope soon variants of D-NeRF enable rendering real-world scenes that include backgrounds.
6. DeRF: Decomposed Neural Radiance Fields

Paper Link: https://arxiv.org/abs/2011.13961
Author: Daniel Rebain, Wei Jiang, Soroosh Yazdani, Ke Li, Kwang Moo Yi, Andrea Tagliasacchi
Conference: CVPR21
Description
- Motivation: Forwarding a large MLP network involves a larger computational budget than forwarding multiple small MLP networks. By decomposing scenes into multiple MLP networks, they reduce the number of computations during the rendering process.
- They explicitly learn the importance of each MLP when rendering a color and volume density in a particular 3D point. Regarding the l1-distance to computed parameter, they weigh the rendered colors from each MLP network.
- Using a Painter’s Algorithm, the model renders from back to front, to the outer buffer.
7. Baking Neural Rendering Fields for Real-Time View Synthesis

Paper Link: https://arxiv.org/abs/2011.13961
Author: Peter Hedman, Pratul P. Srinivasan, Ben Mildenhall, Jonathan T. Barron, Paul Debevec
Conference: ICCV21
Description
- Motivation: Although many variants of NeRF have boosted the inference time, it still remains challenging to enable real-time rendering. By separating specular colors and alpha-composite colors, they minimize the computation during inference time while preserving the rendering qualities.
- The authors propose features called specular features that implicitly encode view-dependent color, i.e. specular color. In addition, from the trained NeRF networks, they generate sparse voxel grids based on estimated volume density in 3D canonical space.
- Storing the color of the generated sparse voxels grids into a texture atlas, they skip the rendering in inference time. Eventually, the only thing to compute during the inference time is a view-dependent color rendered from a tiny MLP network.
8. KiloNeRF: Speeding up Neural Radiance Fields with Thousands of MLPs

Paper Link: https://arxiv.org/abs/2011.13961
Author: Christian Reiser, Songyou Peng, Yiyi Liao, Andreas Geiger
Conference: ICCV21
Description
- Motivation: The motivation is similar to the motivation of “DeRF: Decomposed Neural Radiance Fields”. The proposed algorithm first partitions the canonical space with thousands of much smaller networks.
- Setting the trained vanilla NeRF network as a teacher model, they distillate the teacher model to multiple networks. To select a proper network, they define a mapping function. Simply distilling the teacher networks fails to generate reliable scenes. Thus, they apply L2 regularization to the weights and biases of the last two layers of the networks.
9. Depth-supervised NeRF: Fewer Views and Faster Training for Free

Paper Link: https://arxiv.org/abs/2011.13961
Author: Kangle Deng, Andrew Liu, Jun-Yan Zhu, Deva Ramanan
Conference: ICCV21
Description
- Motivation: NeRF requires a set of images and the corresponding camera poses of the images. In the general SfM, camera poses are estimated with depth values. However, NeRF ignores the estimated depth values. The authors argue that supervision from the depth values is beneficial to NeRF for learning accurate volume densities, resulting in better rendering accuracy.
- With trained volume density, they estimate the depth of each ray. The goal of depth loss they propose is to learn accurate depth values with an additional explicit loss term.
10. Self-Calibrating Neural Radiance Fields

Paper Link: https://arxiv.org/abs/2011.13961
Author: Yoonwoo Jeong, Seokjun Ahn, Christopher Choy, Animashree Anandkumar, Minsu Cho, Jaesik Park
Conference: ICCV21
Description
- Motivation: The general NeRF framework assumes that the estimated camera information using COLMAP is sufficiently accurate. Since the goal of NeRF is to overfit the network into the scenes, the accuracy of the estimated camera information is crucial.
- The author proposes an extended camera model to reflect complex noises in the camera. By jointly optimizing camera and NeRF parameters, SCNeRF enables rendering without carefully calibrated camera information. Moreover, the algorithm results in better rendering qualities than the vanilla NeRF and NeRF++.
We’ll soon be back with the additional papers in Part2.
If the article was beneficial and interesting, please follow my individual account.
LinkedIn: https://www.linkedin.com/in/yoonwoo-jeong-6994ab185/
GitHub: https://github.com/jeongyw12382
Mail: jyw123822@gmail.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


