



Trends in AI — April 2023 // GPT-4, New Prompting Tricks, Zero-shot Video Generation
Last Updated on April 12, 2023 by Editorial Team
Author(s): Sergi Castella i Sapé
Originally published on Towards AI.
GPT-4 has arrived; it’s already everywhere. ChatGPT plugins bring augmented LMs to the masses, new Language Model tricks are discovered, Diffusion models for video generation, Neural Radiance Fields, and more.
Just three weeks after the announcement of GPT-4, it already feels like it’s been with us forever. Meanwhile, an open letter with high-profile signatories calling for a stop on giant AI experiments went viral, and subsequently, the AGI discourse has been unleashed and Eliezer Yudkowsky’s imminent superintelligence doom existential risk theories have made it to Times Magazine. If you’ve got a case of existential angst over a hypothetical intelligence explosion, here’s a phenomenal based take from Julian Togelius that can soothe your soul. With that out of the way, let’s start looking at what happened recently in the AI world.
????️ News
- ChatGPT plugins: ChatGPT can now interact with external modules via natural language and act as an augmented language model. For instance, using WolframAlpha for information about the world and sound computation, or Kayak to search for flights, stays or rental cars.
- Italy banned ChatGPT temporarily last week on the grounds that it violates GDPR. While OpenAI complied with the ban, this has left the EU in a weird spot with growing uncertainties about what Language Model technologies will be allowed in the old continent.
- Stanford’s Center for Research on Foundation Models (CRFM) unveiled Alpaca, an instruction-following model trained by distilling OpenAI’s models using Meta’s LLAMA as a base model. Since then, the past couple of weeks has seen a good amount of similar open-source distillations from GPT models, such as Vicuna (Post, Demo, Repo) an up to 13B instruction-following model trained by distilling from conversations people have shared from ChatGPT (via ShareGPT).
- Stanford released their annual AI Index Report for 2023, highlighting, among others, how much AI research has shifted from academia into the industry and quantifying the growth that the field has experienced in the past decade.
- Midjourney (an independent research lab) has the world in awe with its new v5 image generation model. Adobe is building competing products for its creative suit, but it looks like they are struggling to have on-par quality, as they’re more cautious with training data to avoid using copyrighted data inadvertently. Runway — the company behind Stable Diffusion — has been touting their new video generation product Gen 2.
- Nvidia announced during their latest developer conference their efforts to become the leading foundry for large foundation models. Clients will be able to define a model they want to train and Nvidia will use their infrastructure and expertise to train the model for them. Meanwhile, Google outlined in more detail their latest TPU v4 accelerators in their latest paper.
- GitHub announced Copilot X, a big update to Copilot that adds chat and voice interface features, supports pull request completions, question answering on documentation, and adopts GPT-4.
???? Research
This month, our selection of research includes GPT-4, applications of language models, diffusion models, computer vision, video generation, recommender systems, and neural radiance fields.
1. GPT-4 Technical Report // Sparks of Artificial General Intelligence: Early experiments with GPT-4
By Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang.
❓ Why → The already famous GPT-4 from OpenAI has been the uncontested star this past month. But its release has generated more questions than its technical report chose to answer. Hence the addition here of the massive evaluation paper that examines its behavior in more detail. Of course, the writing of this very text was aided by GPT-4.
???? Key insights → This evaluation paper is filled with samples and anecdotes from GPT-4 experiments. While this cherry-picking approach is unapologetically motivated and biased, it turns out to be an essential tool for grasping the behavior of this powerful model. Not a replacement for the big tables with bold numbers, but a necessary companion.
The hilarious example: how GPT-4 ability to draw a unicorn in TikZ (LaTeX) improved over time while the model was still under active development.
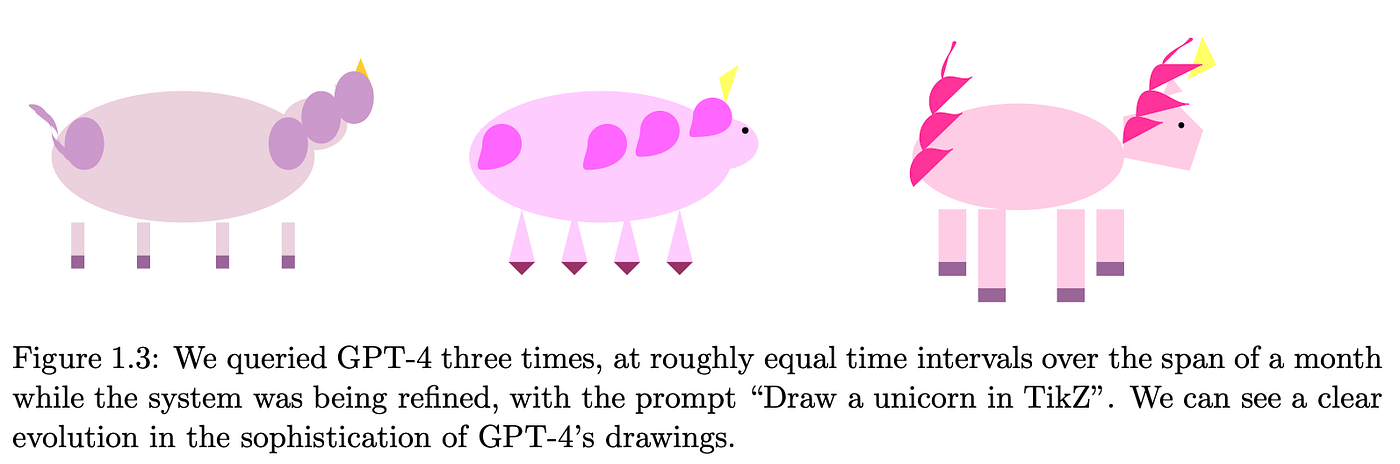
The 155-page evaluation report covers a vast range of topics, such as multimodal capabilities, mathematical reasoning, coding, human interaction, and societal influences. The authors argue that GPT-4 shows some behavior that could be labeled general intelligence while acknowledging its limitations and caveats.
The cluelessness of Microsoft’s researchers highlights the secrecy involved in this project: the authors from the very tech giant who partnered with OpenAI and provided the infrastructure for training GPT-4 didn’t seem to have details of GPT-4 beyond having access to a mysterious API endpoint.
2. Larger language models do in-context learning differently
By Jerry Wei, Jason Wei, Yi Tay, Dustin Tran, Albert Webson, Yifeng Lu, Xinyun Chen, Hanxiao Liu, Da Huang, Denny Zhou, Tengyu Ma.
❓ Why → The emergence of complex in-context learning in large language models has piqued everyone’s interest. This article delves into some niche but fascinating emerging capabilities from large language models that are not present in their smaller counterparts.
???? Key insights → Larger models possess unique abilities that smaller models simply can’t replicate, no matter how much data and effort is put to into it. For example, large models can learn within the prompt to flip labels and learn new mappings, such as reversing the sentiment labels of sentences (e.g., positive sentences are labeled negative and vice versa).

The main emergence study reveals:
- Large models learn to flip labels, while smaller models stick to their pre-trained knowledge, continuing to label positive as positive and negative as negative.
- Semantically unrelated labels (SUL) emerge with scale, where the models label things with tokens that are not words.
- Instruction-tuned models strengthen both the use of semantic priors and the capacity to learn input-label mappings. However, they place more emphasis on the former aspect.
3. Reflexion: an autonomous agent with dynamic memory and self-reflection
By Noah Shinn, Beck Labash, Ashwin Gopinath.
❓ Why → Techniques to embed LMs in self-improvement loops have been in vogue this past month!
???? Key insights → The anthropomorphic motivation for reflection is intuitive: we humans don’t always get things right on our first try. To solve problems, we often rely on trying a reasoning path, and then verifying how well it holds once it’s fully unfolded. If it doesn’t we try to correct it until the whole thing makes sense. Vanilla autoregressive LMs don’t have that ability out of the box.
Researchers have discovered that equipping LMs with a similar mechanism can improve their performance. Simply, prompt an LM, then ask it to reflect on its output and correct it if necessary. This can be embedded in an environment where the LM can know whether an answer or action is correct or not, and then try to improve it until it’s right.


Other similar papers are Self-Refine: Iterative Refinement with Self-Feedback (more focused on instruction-following rather than problem-solving), or Language Models can Solve Computer Tasks (focused on doing goal-oriented planning), which follow a similar “produce-critique-fix” feedback loop, largely based on heuristics and templated natural language inner monologues. This continues to prove that existing LMs can be seen as a new platform to build stuff on top of, and we’ve only scratched the surface of what’s possible.
4. Foundation Models for Decision Making: Problems, Methods, and Opportunities
By Sherry Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, Dale Schuurmans.
❓ Why → LMs appear to be an unreasonably useful dark-grey-box computation engine. So they can be applied to all sorts of things beyond language, such as decision-making. Here’s a comprehensive snapshot and taxonomy of the field.
???? Key insights → The authors consider the general case of embedding a foundation model within an environment where it can take actions and observe rewards. They identify several angles from which FMs can be used in decision-making contexts: as generative models, representation learners, agents, or environments.
A significant challenge when applying foundation models to decision-making is what the authors call the “dataset gap”. The broad datasets from vision and language domains where FMs are trained on often differ in modality and structure compared to task-specific interactive datasets used in reinforcement learning (RL). For example, video datasets typically lack explicit action and reward labels, which are essential components of RL. This is relevant cause most FMs for decision models are conceptualized as training a Markov Decision Process (MDP) via Behavior Cloning (like offline RL), which can lead to poor coverage of the whole action-state space, which should be possible to bridge with RL finetuning, but that ends up being hard in practice. This paper highlights the need to bridge this gap to enhance the applicability of LMs in decision-making tasks.
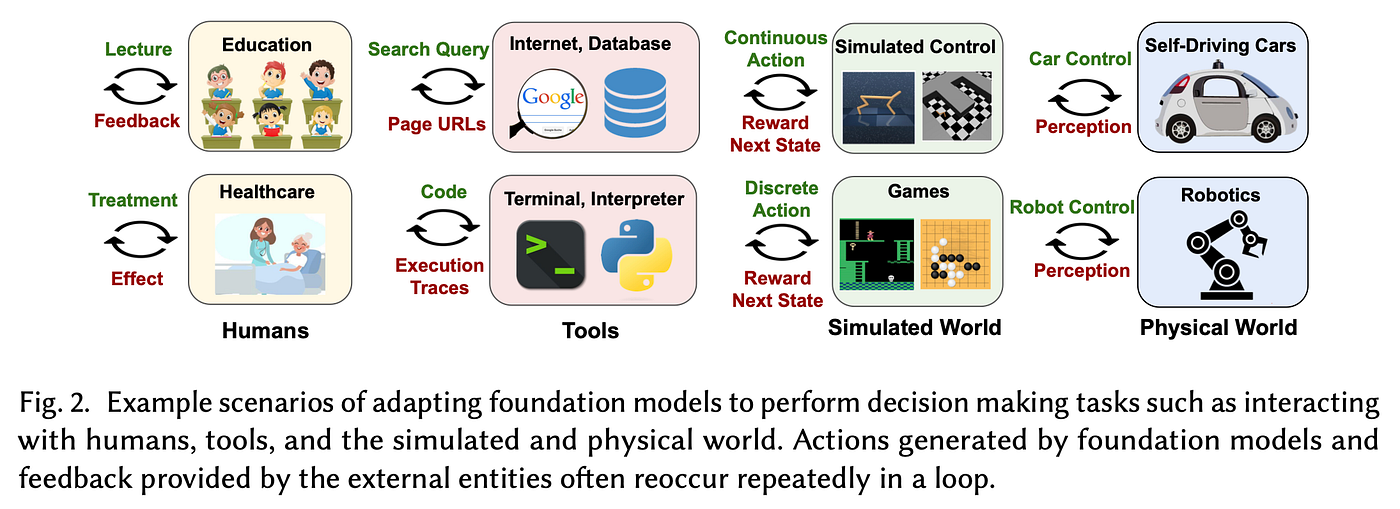
For an impressive use-case of an agent built by using GPT-4 along with other retrieval and enhancement modules, see Task-driven Autonomous Agent Utilizing GPT-4, Pinecone, and LangChain for Diverse Applications.
If you’re looking for another recent all-encompassing survey on language models, check out A Survey of Large Language Models, or Language Model Behavior: A Comprehensive Survey.
5. GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
By Tyna Eloundou, Sam Manning, Pamela Mishkin, Daniel Rock.
❓ Why → A bit of a different paper here. We often hear hot takes on the impact that AI will have on the job market. This work tries to quantify this for various professions.
???? Key insights → Let me preface this by observing how remarkably bad mainstream futurists have been through history at predicting what things are hard to automate and what things AI would learn to do first. Now, with that out of the way, this work quantifies productivity gains for different tasks using LMs. The punchline?
Our analysis suggests that, with access to an LLM, about 15% of all worker tasks in the US could be completed significantly faster at the same level of quality. When incorporating software and tooling built on top of LLMs, this share increases to between 47 and 56% of all tasks.
The key concept doing the heavy-lifting here is “Exposure”, which is defined as the extent to which access to an LLM system can decrease the time taken for a human to perform a specific task by at least 50 percent. The implications from exposure are still unclear, though: increased productivity and increased wages? Reduction of available jobs? Only time will truly tell, but in the meantime, here’s some data on how much performance correlates with using LMs as an aid in different tasks.
6. Erasing Concepts from Diffusion Models
By Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, David Bau.
❓ Why → Arguably, the most exciting of advanced generative AI is how it will enable a whole new paradigm of human-computer interaction. This paper proposes a method for such interaction when editing images with diffusion models.
???? Key insights → The authors introduce a technique called Erased Stable Diffusion (ESD), which fine-tunes a model’s parameters using only the “undesired” concept descriptions without the need for additional training data. This ad-hoc approach can be easily integrated into any pre-trained diffusion model. For instance, given an image of a field with a tree, you could simply prompt with “erase the tree”, and the output would be the “same” image without the tree.
ESD’s primary goal is to erase concepts from text-to-image diffusion models utilizing the model’s own knowledge and no additional data. The method employs Latent Diffusion Models (LDM), focusing on the latent space rather than pixel space, and uses [Stable Diffusion] for all its experiments. The technique is optimized for 3 types of removal: artistic effect (e.g., undoing a Van Gogh-style filter), explicit content, and objects. See some examples in the figure below!

7. Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
By Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, Humphrey Shi.
❓ Why → We’ve already seen some text to ‘video’ works such as Meta’s Make-a-video (well, it’s more like GIFs). But what about text-to-video that just uses an off-the-shelf text-to-image model and doesn’t need training further?
???? Key insights → Text2Video-Zero presents a method to convert an existing diffusion model for text-to-image synthesis into a text-to-video model. This approach enables zero-shot video generation using textual prompts or prompts combined with guidance from poses or edges, and even instruction-guided video editing. The best part? It’s entirely training-free and doesn’t require massive computing power or multiple GPUs, making video generation accessible for everyone.
The trick is to play around with “movements” in the latent representation space the diffusion model uses to align images with text. While jiggling that embedding would produce non-coherent movements in the resulting video, this work proposes two novel post-hoc techniques to enforce temporally consistent generation by encoding motion dynamics in latent codes and reprogramming each frame’s self-attention using cross-frame attention (see the figure below for more details). The results are short coherent videos created without any video-specific training.

Other recent works on video generation you might be interested in are Video-P2P: Video Editing with Cross-attention Control, and Pix2Video: Video Editing using Image Diffusion.
8. LERF: Language Embedded Radiance Fields | Project Page
By Justin Kerr, Chung Min Kim, Ken Goldberg, Angjoo Kanazawa, Matthew Tancik.
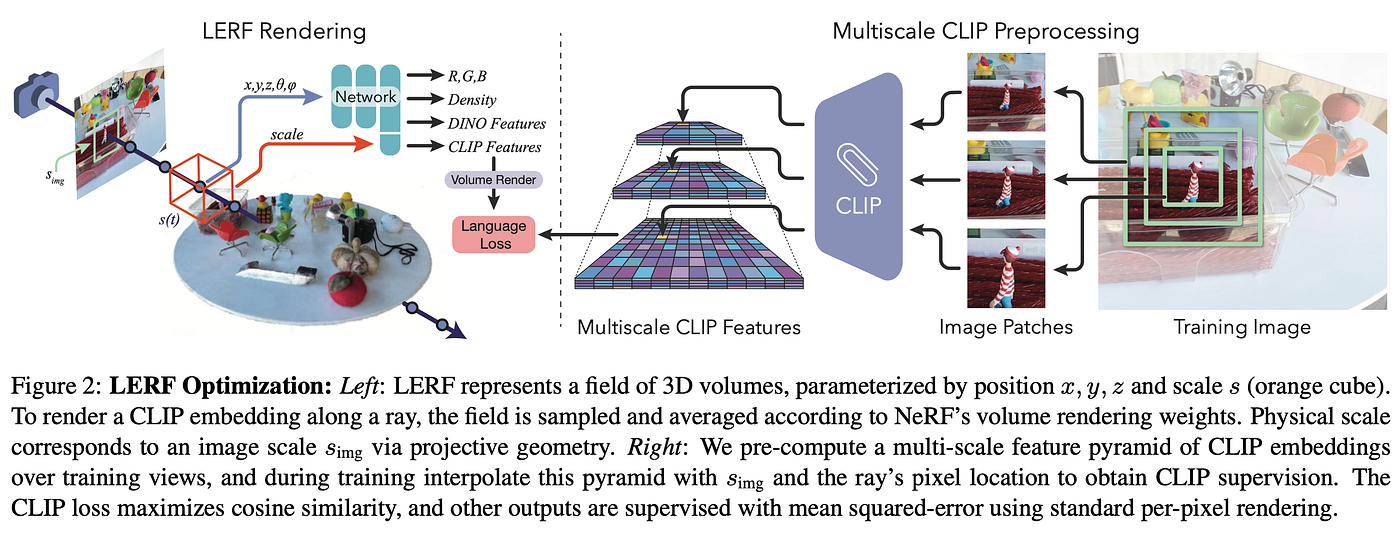
❓ Why → Combining NeRFs with off-the-shelf CLIP embeddings for superior semantic segmentation and language grounding.
???? Key insights → LERF optimizes a dense, multi-scale 3D language field by leveraging CLIP embeddings along training rays and supervising them with multi-scale CLIP features across multiple training images. This optimization enables real-time, interactive extraction of 3D relevancy maps for language queries. LERF supports long-tail, open-vocabulary queries hierarchically across the volume without relying on region proposals, masks, or fine-tuning.
Compared to 2D CLIP embeddings, 3D offer robustness to occlusion and viewpoint changes, as well as a crisper appearance that conforms better to the 3D scene structure. Multi-scale supervision and DINO regularization improve object boundaries and overall quality.
The authors also showcase how LERF can integrate seamlessly with ChatGPT, allowing users to interact with the 3D world using natural language. An example demonstrates how ChatGPT can provide language queries for cleaning a coffee spill (see figure below, along with a heatmap gif on a NeRF scene). This will soon be integrated into the popular Nerfstudio research codebase.

The authors also showcase how LERF can integrate seamlessly with ChatGPT, allowing users to interact with the 3D world using natural language. An example demonstrates how ChatGPT can provide language queries for cleaning a coffee spill (see figure below). And this will soon be integrated into the popular Nerfstudio research codebase.


9. Resurrecting Recurrent Neural Networks for Long Sequences
By Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, Soham De.
❓ Why → RNNs hidden potential? Transformer’s full attention to computational complexity means some level of recurrency could be required to achieve truly long-range dependency modeling. Here’s where RNNs stand.
???? Key insights → Recurrent neural networks (RNNs) have been crucial in deep learning for modeling sequential data but famously suffer from vanishing and exploding gradient problems, which LSTMs (sort-of) solved back in the day. Still, they’re not on par with Transformers' explicit self-attention. The recently introduced S4 , a deep state-space model (SSM)overcame some of these issues and achieved remarkable performance on very long-range reasoning tasks. This paper demonstrates that by making small changes to a deep vanilla RNN, the Linear Recurrent Unit (LRU) model can match the performance and efficiency of deep SSMs on the Long Range Arena (LRA) benchmark.
The Linear Recurrent Unit (LRU) is the core architectural contribution of this paper. The modifications from the vanilla RNN include linearization (removing non-linearities in the recurrent connections), diagonalization (which allows for parallelization and faster training), stable exponential parameterization, and normalization.
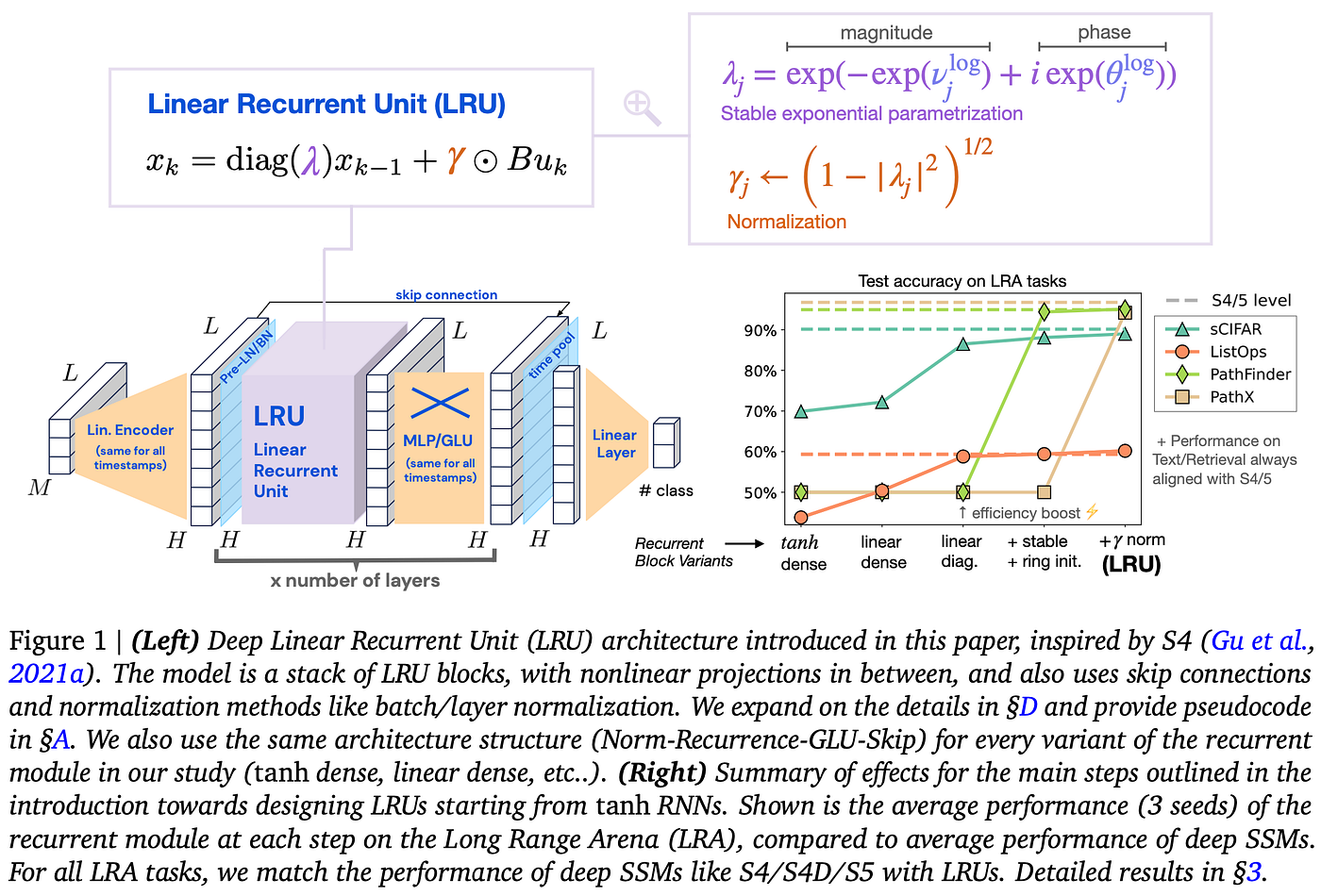
Once again, this paper shows how many of the advances in neural network rely on clever optimizations to make training faster, stable, and scalable; rather than clever architectural choices. While this won’t replace Transformers anytime soon, long-range recurrence will still be useful when linear inference complexity is required.
10. Recommender Systems with Generative Retrieval
By Shashank Rajput et al.
❓ Why → Remember the Differentiable Search Index (DSI)? Now for recommendations.
???? Key insights → The Differentiable Search Index used a transformer to memorize document IDs and generate them autoregressively based on a query, eliminating the need for a conventional index. Building on this idea, researchers have proposed TIGER, a generative retrieval-based recommender model. TIGER assigns unique Semantic IDs to each item, then trains a retrieval model to predict the Semantic ID of the next item a user will engage with given previous item IDs. Basically, doing autoregressive modeling on these IDs.
Unlike in the DSI base experiments, in this case, the IDs are semantically relevant: they use the title and text descriptions of items to encode them with Sentence-T5, then apply residual quantization to obtain a quantized representation for each item.
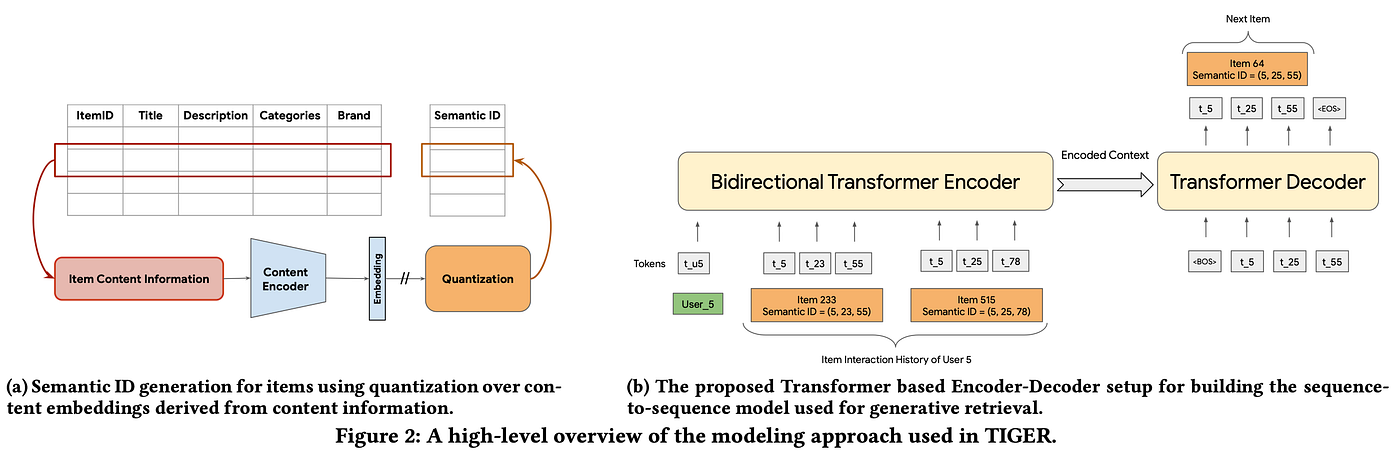
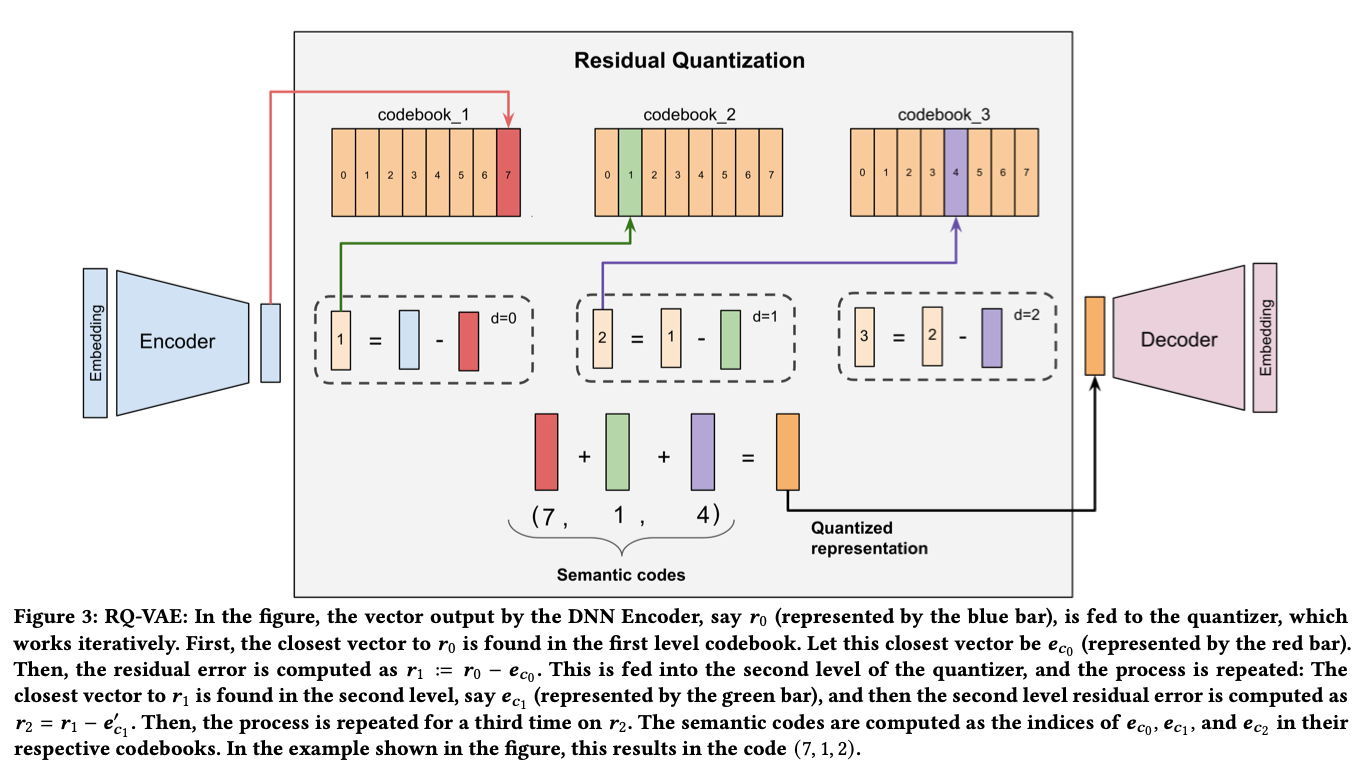
TIGER beats previous state-of-the-art in terms of recall and NDCG across the Amazon Product Reviews dataset. Despite the drawbacks associated with the DSI (it’s not that easy to add new items to a pretrained model), this new generative retrieval paradigm does offer advantages such as recommending infrequent items (improving cold-start problems) and generating diverse recommendations by tweaking the temperature of the generation.
This month’s selection is all wrapped up — if you want to stay ahead of the curve, give us a follow on Twitter @zetavector and stay tuned for next month’s picks!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Take our 90+ lesson From Beginner to Advanced LLM Developer Certification: From choosing a project to deploying a working product this is the most comprehensive and practical LLM course out there!
Towards AI has published Building LLMs for Production—our 470+ page guide to mastering LLMs with practical projects and expert insights!

Discover Your Dream AI Career at Towards AI Jobs
Towards AI has built a jobs board tailored specifically to Machine Learning and Data Science Jobs and Skills. Our software searches for live AI jobs each hour, labels and categorises them and makes them easily searchable. Explore over 40,000 live jobs today with Towards AI Jobs!
Note: Content contains the views of the contributing authors and not Towards AI.
Related posts


Popular posts

 for 2021")



Updates

Recent Posts



