



Building Domain-Specific Custom LLM Models: Harnessing the Power of Open Source Foundation Models
Last Updated on May 22, 2023 by Editorial Team
Author(s): Sriram Parthasarathy
Originally published on Towards AI.
The transformative potential of training large LLMs with domain-specific data.
Organizations are undergoing a significant shift by actively looking into the development of their own custom large language models (LLMs) to address the increasing demand for greater control, data privacy, and cost-effective solutions. This paradigm shift is driven by the recognition of the transformative potential held by smaller, custom-trained models that leverage domain-specific data. These models surpass the performance of broad-spectrum models like GPT-3.5, which serves as the foundation for ChatGPT. Adding momentum to this shift, the release of several open-source, commercially viable foundation models has provided organizations with a monumental opportunity to empower themselves with tailored, high-performing language models that precisely cater to their unique requirements. This new era of custom LLMs marks a significant milestone in the quest for more customizable and efficient language processing solutions.
Challenges of building custom LLMs
Building custom Large Language Models (LLMs) presents an array of challenges to organizations that can be broadly categorized under data, technical, ethical, and resource-related issues.
1. Data Challenges
When developing custom Language Models (LLMs), organizations face challenges related to data collection and quality, as well as data privacy and security. Acquiring a significant volume of domain-specific data can be challenging, especially if the data is niche or sensitive. Ensuring data quality during collection is also important. Additionally, organizations must address privacy and security concerns when training models using proprietary or sensitive data by implementing measures to de-identify data and safeguard it during training and deployment.
2. Technical Challenges
Building a custom Language Model (LLM) involves challenges related to model architecture, training, evaluation, and validation. Choosing the appropriate architecture and parameters requires expertise, and training custom LLMs demands advanced machine-learning skills. Evaluating the performance of these models is complex due to the absence of established benchmarks for domain-specific tasks. Validating the model’s responses for accuracy, safety, and compliance poses additional challenges.
3. Ethical Challenges
When building custom Language Models (LLMs), it is crucial to address challenges related to bias and fairness, as well as content moderation and safety. LLMs may unintentionally learn and perpetuate biases from training data, necessitating careful auditing and mitigation strategies. Ensuring the prevention of inappropriate or harmful content generated by custom LLMs poses significant challenges, requiring the implementation of robust content moderation mechanisms.
4. Resource Challenges
Building custom Language Models (LLMs) presents challenges related to computational resources and expertise. Training LLMs require significant computational resources, which can be costly and may not be easily accessible to all organizations. Developing custom LLMs also necessitates a team with expertise in machine learning, natural language processing (NLP), and software engineering, which can be challenging to find and retain, adding to the complexity and cost of the process.
While these challenges can be significant, they are not insurmountable. With the right planning, resources, and expertise, organizations can successfully develop and deploy custom LLMs to meet their specific needs. As open-source commercially viable foundation models are starting to appear in the market, the trend to build out domain-specific LLMs using these open-source foundation models will heat up.
Open-Source Foundation Language Models: Transparency, Customization, and Collaborative Development
The rise of open-source and commercially viable foundation models has led organizations to look at building domain-specific models. Open-source Language Models (LLMs) provide accessibility, transparency, customization options, collaborative development, learning opportunities, cost-efficiency, and community support. For example, a manufacturing company can leverage open-source foundation models to build a domain-specific LLM that optimizes production processes, predicts maintenance needs, and improves quality control. By customizing the model with their proprietary data and algorithms, the company can enhance efficiency, reduce costs, and drive innovation in their manufacturing operations. This customization, along with collaborative development and community support, empowers organizations to look at building domain-specific LLMs that address industry challenges and drive innovation.

The next section discusses the benefits and the potential of using open-source foundation models for building custom domain-specific LLMs
The Allure of Control
Adopting custom LLMs offers organizations unparalleled control over the behaviour, functionality, and performance of the model. For example, a financial institution that wants to develop a customer service chatbot can benefit from adopting a custom LLM. By creating its own language model specifically trained on financial data and industry-specific terminology, the institution gains exceptional control over the behavior and functionality of the chatbot. They can fine-tune the model to provide accurate and relevant responses to customer inquiries, ensuring compliance with financial regulations and maintaining the desired tone and style. This level of control allows the organization to create a tailored customer experience that aligns precisely with their business needs and enhances customer satisfaction.
Prioritizing Data Privacy
Data privacy is a fundamental concern for today’s organizations, especially when handling sensitive or proprietary information. For instance, a healthcare provider aiming to develop a medical diagnosis assistant can prioritize data privacy by utilizing a custom LLM.
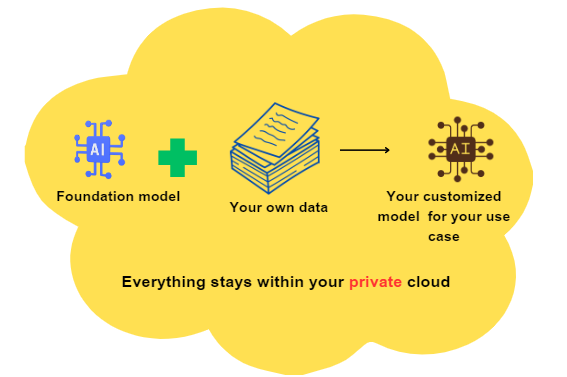
By training the model on their own de-identified patient data, the healthcare provider ensures that sensitive information remains secure within their organization. This approach mitigates the risks associated with sharing patient data with third-party models and reduces the potential for data breaches or unauthorized access. By maintaining full control over their data, the healthcare provider can adhere to strict privacy regulations, safeguard patient confidentiality, and uphold their commitment to data privacy and security.
The Economic Advantage
While broad-scale models such as GPT-3.5 boast impressive capabilities, they often carry significant costs. For example, a retail e-commerce company seeking to improve its product recommendation system can leverage the economic advantage of custom LLMs. Rather than relying on a large-scale model like GPT-3.5, which may come with substantial costs, the company can develop a custom LLM specifically trained on its own transactional and customer data. This targeted approach allows the company to optimize resource allocation by focusing on the most relevant data for product recommendations. By building a smaller, cost-effective custom LLM, the company can achieve comparable or even superior performance while significantly reducing the financial burden associated with training and deploying a generic model.
The Edge of Domain-Specificity
Organizations are recognizing that custom LLMs, trained on their unique domain-specific data, often outperform larger, more generalized models. For instance, a legal research firm seeking to improve its document analysis capabilities can benefit from the edge of domain-specificity provided by a custom LLM. By training the model on a vast collection of legal documents, case law, and legal terminology, the firm can create a language model that excels in understanding the intricacies of legal language and context. This domain-specific expertise allows the model to provide a more accurate and nuanced analysis of legal documents, aiding lawyers in their research and decision-making processes.
The Roadmap to Custom LLMs
The journey toward custom LLMs involves a number of steps, including the collection and curation of domain-specific data, the selection of suitable architectures, and the utilization of cutting-edge model training techniques. Organizations can tap into open-source tools and frameworks to streamline the creation of their custom models. This journey paves the way for organizations to harness the power of language models perfectly tailored to their unique needs and objectives.
Wrapping Up
The increasing emphasis on control, data privacy, and cost-effectiveness is driving a notable rise in the interest in building of custom language models by organizations. By embracing domain-specific models, organizations can unlock a wide range of advantages, such as improved performance, personalized responses, and streamlined operations. This shift signifies a departure from relying solely on generic models, ushering in a new era where organizations harness the potential of custom LLMs to drive innovation, address industry-specific challenges, and gain a competitive edge in the dynamic realm of natural language processing.
For example, one potential future outcome of this trend could be seen in the healthcare industry. With the deployment of custom LLMs trained on vast amounts of patient data, medical institutions could revolutionize clinical decision support systems. These custom models would possess a deep understanding of medical terminologies, procedures, and patient histories, enabling them to optimize patient care, minimize errors, and significantly improve overall healthcare outcomes.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")