


NLP (doc2vec from scratch) & Clustering: Classification of news reports based on the content of the text
Last Updated on November 18, 2023 by Editorial Team
Author(s): Krikor Postalian-Yrausquin
Originally published on Towards AI.
In this example, I use NLP (Doc2Vec) and clustering algorithms to try to classify news by topic.
There are many ways to do this type of classification, such as using supervised methods (a tagged dataset), using clustering and using a specific LDA algorithm (topic modeling).
I use Doc2Vec because I consider it a good algorithm for vectorizing text and it is relatively simple to train from scratch.
The general overview of how I am going to address this situation is as follows:
As usual, the first step is to load the required libraries:
#to process data
import numpy as np
import pandas as pd
#dictionary data source is in json
import json
pd.options.mode.chained_assignment = None
#read from disk
from io import StringIO
#text preprocessing and cleaning
import re
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
nltkstop = stopwords.words('english')from nltk.stem.snowball import SnowballStemmer
nltk.download('punkt')
snow = SnowballStemmer(language='English')
#modeling
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
from nltk.tokenize import word_tokenize
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import pairwise_distances
from sklearn.cluster import Birch
from sklearn.metrics import silhouette_samples, silhouette_score, calinski_harabasz_score
import warnings
#plots
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import seaborn as sns
Then, I read the data and prepared the dictionary files. These are originally from datasets public in Kaggle (lists of countries, names, currencies, etc.)
#this is the articles to process dataset
maindataset = pd.read_csv("articles1.csv")
maindataset2 = pd.read_csv("articles2.csv")
maindataset = pd.concat([maindataset,maindataset2], ignore_index=True)
#this is a list of countries. We will replaces the country names in the articles by xcountryx
countries = pd.read_json("countries.json")
countries["country"] = countries["country"].str.lower()
countries = pd.DataFrame(countries["country"].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
countries.columns = ['word']
countries["replacement"] = "xcountryx"
#this is a list of provincies. This list includes several alternate names and a list of countries, which I am also adding to the dictionary
provincies = pd.read_csv("countries_provincies.csv")
provincies1 = provincies[["name"]]
provincies1["name"] = provincies1["name"].str.lower()
provincies1 = pd.DataFrame(provincies1["name"].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
provincies1.columns = ['word']
provincies1["replacement"] = "xprovincex"
provincies2 = provincies[["name_alt"]]
provincies2["name_alt"] = provincies2["name_alt"].str.lower()
provincies2 = pd.DataFrame(provincies2["name_alt"].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
provincies2.columns = ['word']
provincies2["replacement"] = "xprovincex"
provincies3 = provincies[["type_en"]]
provincies3["type_en"] = provincies3["type_en"].str.lower()
provincies3 = pd.DataFrame(provincies3["type_en"].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
provincies3.columns = ['word']
provincies3["replacement"] = "xsubdivisionx"
provincies4 = provincies[["admin"]]
provincies4["admin"] = provincies4["admin"].str.lower()
provincies4 = pd.DataFrame(provincies4["admin"].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
provincies4.columns = ['word']
provincies4["replacement"] = "xcountryx"
provincies5 = provincies[["geonunit"]]
provincies5["geonunit"] = provincies5["geonunit"].str.lower()
provincies5 = pd.DataFrame(provincies5["geonunit"].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
provincies5.columns = ['word']
provincies5["replacement"] = "xcountryx"
provincies6 = provincies[["gn_name"]]
provincies6["gn_name"] = provincies6["gn_name"].str.lower()
provincies6 = pd.DataFrame(provincies6["gn_name"].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
provincies6.columns = ['word']
provincies6["replacement"] = "xcountryx"
provincies = pd.concat([provincies1,provincies2,provincies3,provincies4,provincies5,provincies6], axis=0, ignore_index=True)
#currency list
currencies = pd.read_json("country-by-currency-name.json")
currencies1 = currencies[["country"]]
currencies1["country"] = currencies1["country"].str.lower()
currencies1 = pd.DataFrame(currencies1["country"].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
currencies1.columns = ['word']
currencies1["replacement"] = "xcountryx"
currencies2 = currencies[["currency_name"]]
currencies2["currency_name"] = currencies2["currency_name"].str.lower()
currencies2 = pd.DataFrame(currencies2["currency_name"].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
currencies2.columns = ['word']
currencies2["replacement"] = "xcurrencyx"
currencies = pd.concat([currencies1,currencies2], axis=0, ignore_index=True)
#first names
firstnames = pd.read_csv("interall.csv", header=None)
firstnames = firstnames[firstnames[1]>=10000]
firstnames = firstnames[[0]]
firstnames[0] = firstnames[0].str.lower()
firstnames = pd.DataFrame(firstnames[0].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
firstnames.columns = ['word']
firstnames["replacement"] = "xfirstnamex"
#last names
lastnames = pd.read_csv("intersurnames.csv", header=None)
lastnames = lastnames[lastnames[1]>=10000]
lastnames = lastnames[[0]]
lastnames[0] = lastnames[0].str.lower()
lastnames = pd.DataFrame(lastnames[0].apply(lambda x: str(x).replace('-',' ').replace('.',' ').replace('_',' ').replace(',',' ').replace(':',' ').split(" ")).explode())
lastnames.columns = ['word']
lastnames["replacement"] = "xlastnamex"
#month, days and other temporal names.
temporaldata = pd.read_csv("temporal.csv")
#whole dictionary
dictionary = pd.concat([lastnames,temporaldata,firstnames,currencies,provincies,countries], axis=0, ignore_index=True)
dictionary = dictionary.groupby(["word"]).first().reset_index(drop=False)
dictionary = dictionary.dropna()
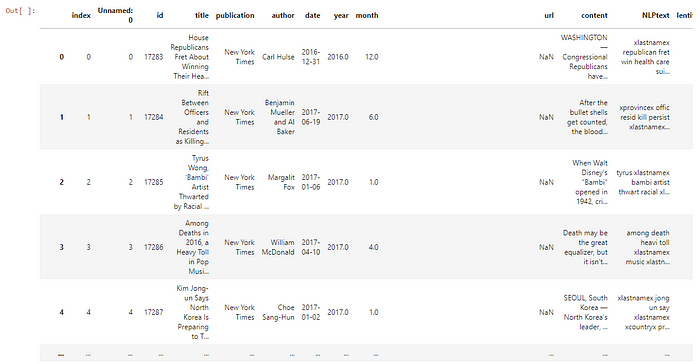
maindataset
This is a preview of the original dataset
maindataset

The next functions are tasked with:
- Replace words using the dictionary crafted above
- Remove punctuation, double spaces, etc.
def replace_words(tt, lookp_dict):
temp = tt.split()
res = []
for wrd in temp:
res.append(lookp_dict.get(wrd, wrd))
res = ' '.join(res)
return res
def preprepare(eingang):
ausgang = eingang.lower()
ausgang = ausgang.replace(u'\xa0', u' ')
ausgang = re.sub(r'^\s*$',' ',str(ausgang))
ausgang = ausgang.replace('U+007C', ' ')
ausgang = ausgang.replace('ï', ' ')
ausgang = ausgang.replace('»', ' ')
ausgang = ausgang.replace('¿', '. ')
ausgang = ausgang.replace('', ' ')
ausgang = ausgang.replace('"', ' ')
ausgang = ausgang.replace("'", " ")
ausgang = ausgang.replace('?', ' ')
ausgang = ausgang.replace('!', ' ')
ausgang = ausgang.replace(',', ' ')
ausgang = ausgang.replace(';', ' ')
ausgang = ausgang.replace('.', ' ')
ausgang = ausgang.replace("(", " ")
ausgang = ausgang.replace(")", " ")
ausgang = ausgang.replace("{", " ")
ausgang = ausgang.replace("}", " ")
ausgang = ausgang.replace("[", " ")
ausgang = ausgang.replace("]", " ")
ausgang = ausgang.replace("~", " ")
ausgang = ausgang.replace("@", " ")
ausgang = ausgang.replace("#", " ")
ausgang = ausgang.replace("$", " ")
ausgang = ausgang.replace("%", " ")
ausgang = ausgang.replace("^", " ")
ausgang = ausgang.replace("&", " ")
ausgang = ausgang.replace("*", " ")
ausgang = ausgang.replace("<", " ")
ausgang = ausgang.replace(">", " ")
ausgang = ausgang.replace("/", " ")
ausgang = ausgang.replace("\\", " ")
ausgang = ausgang.replace("`", " ")
ausgang = ausgang.replace("+", " ")
ausgang = ausgang.replace("=", " ")
ausgang = ausgang.replace("_", " ")
ausgang = ausgang.replace("-", " ")
ausgang = ausgang.replace(':', ' ')
ausgang = ausgang.replace('\n', ' ').replace('\r', ' ')
ausgang = ausgang.replace(" +", " ")
ausgang = ausgang.replace(" +", " ")
ausgang = ausgang.replace('?', ' ')
ausgang = re.sub('[^a-zA-Z]', ' ', ausgang)
ausgang = re.sub(' +', ' ', ausgang)
ausgang = re.sub('\ +', ' ', ausgang)
ausgang = re.sub(r'\s([?.!"](?:\sU+007C$))', r'\1', ausgang)
return ausgangClean up the dictionary data
dictionary["word"] = dictionary["word"].apply(lambda x: preprepare(x))
dictionary = dictionary[dictionary["word"] != " "]
dictionary = dictionary[dictionary["word"] != ""]
dictionary = {row['word']: row['replacement'] for index, row in dictionary.iterrows()}
Preparation of the text data to convert: created a new column with a concatenation of the title (4 times) and the summary. This is what will be converted to vectors. I do this since, this way, I give more value to the title than the actual content of the article.
Then I replace the stop words and words in the dictionary
maindataset["NLPtext"] = maindataset["title"] + maindataset["title"] + maindataset["content"] + maindataset["title"] + maindataset["title"]
maindataset["NLPtext"] = maindataset["NLPtext"].str.lower()
maindataset["NLPtext"] = maindataset["NLPtext"].apply(lambda x: preprepare(str(x)))
maindataset["NLPtext"] = maindataset["NLPtext"].apply(lambda x: ' '.join([word for word in x.split() if word not in (nltkstop)]))
maindataset["NLPtext"] = maindataset["NLPtext"].apply(lambda x: replace_words(str(x), dictionary))
The last part of preparing the text is stemming. This is done in this case since I am training the model from scratch.
The decision to stem or not will depend on the model used. When using pretrained models as in BERT, this is not recommended since the words won’t match the words in their libraries.
def steming(sentence):
words = word_tokenize(sentence)
stems = [snow.stem(whole) for whole in words]
oup = ' '.join(stems)
return oup
maindataset["NLPtext"] = maindataset["NLPtext"].apply(lambda x: steming(x))
maindataset['lentitle'] = maindataset["title"].apply(lambda x: len(str(x).split(' ')))
maindataset['lendesc'] = maindataset["content"].apply(lambda x: len(str(x).split(' ')))
maindataset['lentext'] = maindataset["NLPtext"].apply(lambda x: len(str(x).split(' ')))
maindataset = maindataset[maindataset['NLPtext'].notna()]
maindataset = maindataset[maindataset['lentitle']>=4]
maindataset = maindataset[maindataset['lendesc']>=4]
maindataset = maindataset[maindataset['lentext']>=4]
maindataset = maindataset.reset_index(drop=False)
maindataset
Finally, it is time to train the doc2vec model.
#randomize the dataset
trainset = maindataset.sample(frac=1).reset_index(drop=True)
#exclude text that are too short
trainset = trainset[(trainset['NLPtext'].str.len() >= 5)]
#select the text column
trainset = trainset[["NLPtext"]]
#tokenize and produce the training set
tagged_data = []
for index, row in trainset.iterrows():
part = TaggedDocument(words=word_tokenize(row[0]), tags=[str(index)])
tagged_data.append(part)
#define the model
model = Doc2Vec(vector_size=250, min_count=3, epochs=20, dm=1)
model.build_vocab(tagged_data)
#train and save
model. Train(tagged_data, total_examples=model.corpus_count, epochs=model.epochs)
model.save("d2v.model")
print("Model Saved")
In the spirit of limiting the size of the data and time, I will filter for one news source.
maindataset.groupby('publication').count()['index']

maindatasetF = maindataset[maindataset["publication"]=="Guardian"]
Now, I vectorize the text information for the selected publication.
a = []
for index, row in maindatasetF.iterrows():
nlptext = row['NLPtext']
ids = row['index']
vector = model.infer_vector(word_tokenize(nlptext))
vector = pd.DataFrame(vector).T
vector.index = [ids]
a.append(vector)
textvectors = pd.concat(a)
textvectors

Standardize the embeddings and PCA (reduce the number of dimensions)
def properscaler(simio):
scaler = StandardScaler()
resultsWordstrans = scaler.fit_transform(simio)
resultsWordstrans = pd.DataFrame(resultsWordstrans)
resultsWordstrans.index = simio.index
resultsWordstrans.columns = simio.columns
return resultsWordstrans
datasetR = properscaler(textvectors)
def varred(simio):
scaler = PCA(n_components=0.8, svd_solver='full')
resultsWordstrans = simio.copy()
resultsWordstrans = scaler.fit_transform(resultsWordstrans)
resultsWordstrans = pd.DataFrame(resultsWordstrans)
resultsWordstrans.index = simio.index
resultsWordstrans.columns = resultsWordstrans.columns.astype(str)
return resultsWordstrans
datasetR = varred(datasetR)
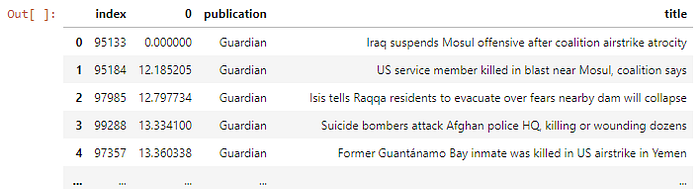
The first exercise I want to attempt now is a similarity search. Find articles similar to the provided example.
#Find by index and print the original search object
index = 95133
texttofind = maindatasetF[maindatasetF["index"]==index]["title"]
print(str(texttofind))
id = index
print(str(id))
cat = maindatasetF[maindatasetF["index"]==index]["publication"]
print(str(cat))
embdfind = datasetR[datasetR.index==id]
#calculate Euclidian pairwise distances and extract the most similar to the provided example
distances = pairwise_distances(X=embdfind, Y=datasetR, metric='euclidean')
distances = pd.DataFrame(distances).T
distances.index = datasetR.index
distances = distances.sort_values(0)
distances = distances.reset_index(drop=False)
distances = pd.merge(distances, maindatasetF[["index","title","publication","content"]], left_on=["index"], right_on=["index"])
pd.options.display.max_colwidth = 100
distances.head(100)[['index',0,'publication','title']]
We can see that the extracted texts make sense, they are similar in nature to the example provided.
For clustering, the first step is finding an ideal number of clusters. At this point, we want to maximize the silhouette and Calinski Harabasz scores while at the same time keeping a logical number of clusters (not too low that are hard to interpret or to high that are too granular).
#Loop to try models and clusters
a = []
X = datasetR.to_numpy(dtype='float')
for ncl in np.arange(2, int(20), 1):
clusterer = Birch(n_clusters=int(ncl))
#catch warnings that clutter the output
with warnings.catch_warnings():
warnings.simplefilter("ignore")
cluster_labels2 = clusterer.fit_predict(X)
silhouette_avg2 = silhouette_score(X, cluster_labels2)
calinski2 = calinski_harabasz_score(X, cluster_labels2)
row = pd.DataFrame({"ncl": [ncl],
"silKMeans": [silhouette_avg2], "c_hKMeans": [calinski2],
})
a.append(row)
scores = pd.concat(a, ignore_index=True)
#plot results
plt.style.use('bmh')
fig, [ax_sil, ax_ch] = plt.subplots(1,2,figsize=(15,7))
ax_sil.plot(scores["ncl"], scores["silKMeans"], 'b-')
ax_ch.plot(scores["ncl"], scores["c_hKMeans"], 'b-')
ax_sil.set_title("Silhouette curves")
ax_ch.set_title("Calinski Harabasz curves")
ax_sil.set_xlabel('clusters')
ax_sil.set_ylabel('silhouette_avg')
ax_ch.set_xlabel('clusters')
ax_ch.set_ylabel('calinski_harabasz')
ax_ch.legend(loc="upper right")
plt.show()

I pick up then 5 clusters and run the algorithm.
ncl_birch = 5
with warnings.catch_warnings():
warnings.simplefilter("ignore")
clusterer2 = Birch(n_clusters=int(ncl_birch))
cluster_labels2 = clusterer2.fit_predict(X)
n_clusters2 = max(cluster_labels2)
silhouette_avg2 = silhouette_score(X, cluster_labels2)
sample_silhouette_values2 = silhouette_samples(X, cluster_labels2)
finalDF = datasetR.copy()
finalDF["cluster"] = cluster_labels2
finalDF["silhouette"] = sample_silhouette_values2
#plot the silhouette scores
fig, ax2 = plt.subplots()
ax2.set_xlim([-0.1, 1])
ax2.set_ylim([0, len(X) + (n_clusters2 + 1) * 10])
y_lower = 10
for i in range(min(cluster_labels2),max(cluster_labels2)+1):
ith_cluster_silhouette_values = sample_silhouette_values2[cluster_labels2 == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_clusters2)
ax2.fill_betweenx(
np.arange(y_lower, y_upper),
0,
ith_cluster_silhouette_values,
facecolor=color,
edgecolor=color,
alpha=0.7,
)
ax2.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper + 10
ax2.set_title("Silhouette plot for Birch")
ax2.set_xlabel("Silhouette coefficient values")
ax2.set_ylabel("Cluster labels")
ax2.axvline(x=silhouette_avg2, color="red", linestyle="--")
ax2.set_yticks([])
ax2.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])

These results are telling me that cluster number 4 might appear less “tied together” than the rest. On the contrary, cluster numbers 3 and 1 are well-defined. This is a sample of the results.
showDF = finalDF.sort_values(['cluster','silhouette'], ascending=[False,False]).groupby('cluster').head(3)
showDF = pd.merge(showDF[['cluster','silhouette']],maindatasetF[["index",'title']], left_index=True ,right_on=["index"])
showDF

I can see that cluster 4 is news related to tech, cluster 3 is for war / international events, cluster 2 is entertainment, cluster 1 is sports, and 0, as usual, is a spot that can be considered as “other”.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

