



Learning Curves: A Picture Says More Than a Thousand Words
Last Updated on March 25, 2024 by Editorial Team
Author(s): Jonte Dancker
Originally published on Towards AI.

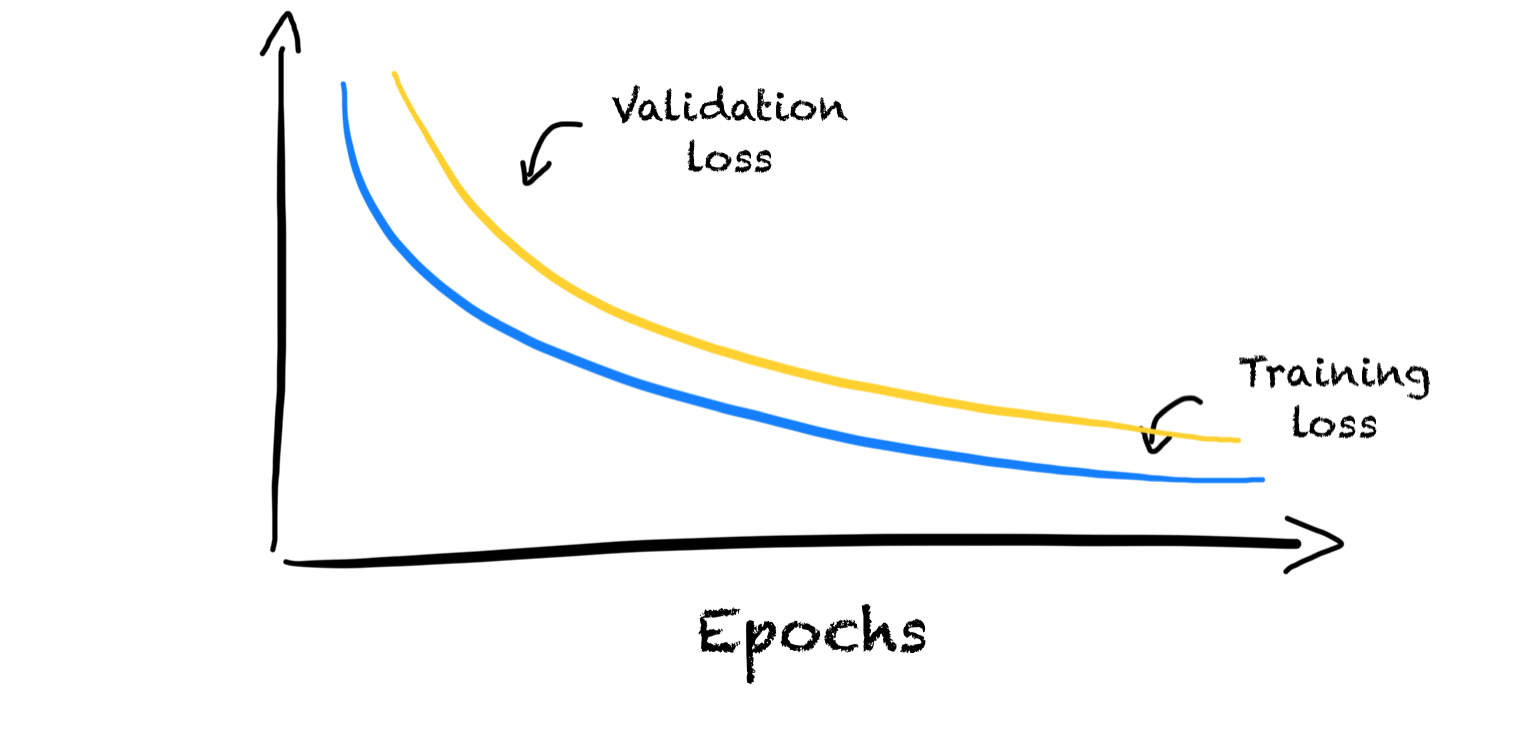


We want our ML models to learn and generalize well to unseen data. A model that does not learn or generalize to unseen data is useless.
Hence, we need to identify if the model is learning and generalizing well before we can do anything about it. But how do we tell?
Imagine a teacher who wants to know how well students learn a new topic. He measures the mistakes over time using a set of practice questions and quizzes. He then plots the results.
We can do the same with our ML model. We measure the model performance in the training phase after each update. For this, we train the model and compute the error on the same data set.
While the teacher plots the error over time, we show the error over training iterations or epochs.
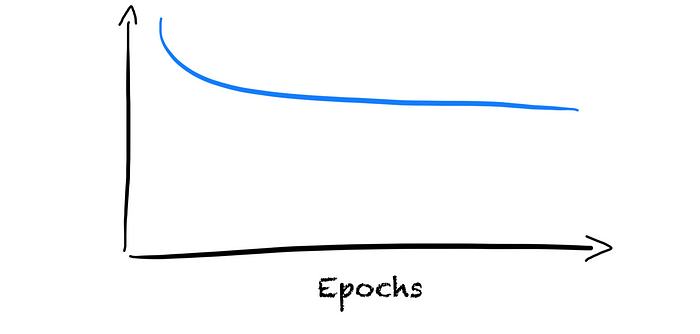
We see that the error on the training set stays high. The model does not seem to learn. Even if it has all the advantages to do well, it does not. We call this underfitting as the model does not fit the training data.
Depending on the learning curve, the teacher has different options. If the learning curve is not decreasing, he could adapt his way of teaching. Whereas, if the learning curve continues decreasing, he could give his students more time. The more often students review the material, the fewer errors they make on practice questions and quizzes.
We can do the same to improve our model. We can add more complexity to the model, allowing the model to better fit the data. Or we can extend the number of training iterations until the learning curve levels off. We can also finetune hyperparameters. For example, we can increase the learning rate, making the model learn faster.
Our goal is to have a smooth learning curve that levels off. A smooth learning curve shows that the model learns steadily and continuously. Whereas, when the learning curve flattens the model stops learning from the training data. We call this convergence.

Now, we know that the model learns well and that it has learned everything there is to learn from the training set. But how do we know if the model can generalize well?
The teacher does not know if the students are actually learning or if they only memorize the answers. Will the students struggle with the new questions or can they draw new conclusions?
The teacher can test his students’ ability to generalize with an exam of unseen questions. Similarly, we can test our model’s performance on a hold-out validation set.
If we do this evaluation after each training iteration, we can add a second learning curve to our plot. The error on the training set shows us how well the model is “learning.” Whereas the error on the validation set shows us how well the model is “generalizing.”
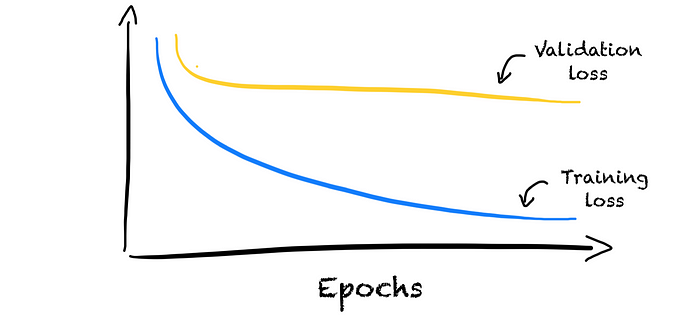
In the above picture, we can see that the training learning curve decreases and converges. The model is learning. But the error on the validation set stays high. The model is not generalizing well. The model rather memorizes the training data. We call this overfitting as the model fits our training set too well.
To handle overfitting, we can reduce the model complexity or use regularization approaches. The goal is to reach a small gap between the training and validation learning curve. This gap shows the generalization error. We thus call it the generalization gap.
We want both learning curves to converge.

The model is learning and generalizing well as long as the training and validation learning curve is decreasing. But if the validation learning curve begins increasing, our model starts overfitting. The model begins to memorize the training set. In this case, we can use early stopping to avoid overfitting. We stop training the model as soon as the validation loss starts increasing.
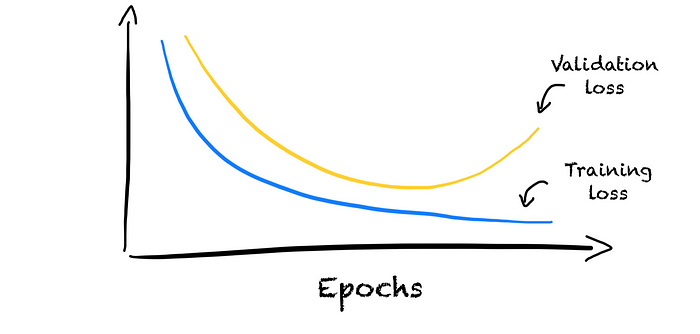
But this is not where learning curves end up being helpful. They can tell us more than if the model is underfitting or overfitting. Learning curves can tell us if our training and validation set are good enough. Moreover, they can guide our hyperparameter tuning.
Problems with the training set can show in decreasing learning curves with a large gap. The training data does not provide enough information for the model to generalize well. There are two reasons for such a behavior. The training set is too small or the training and validation set come from different distributions.
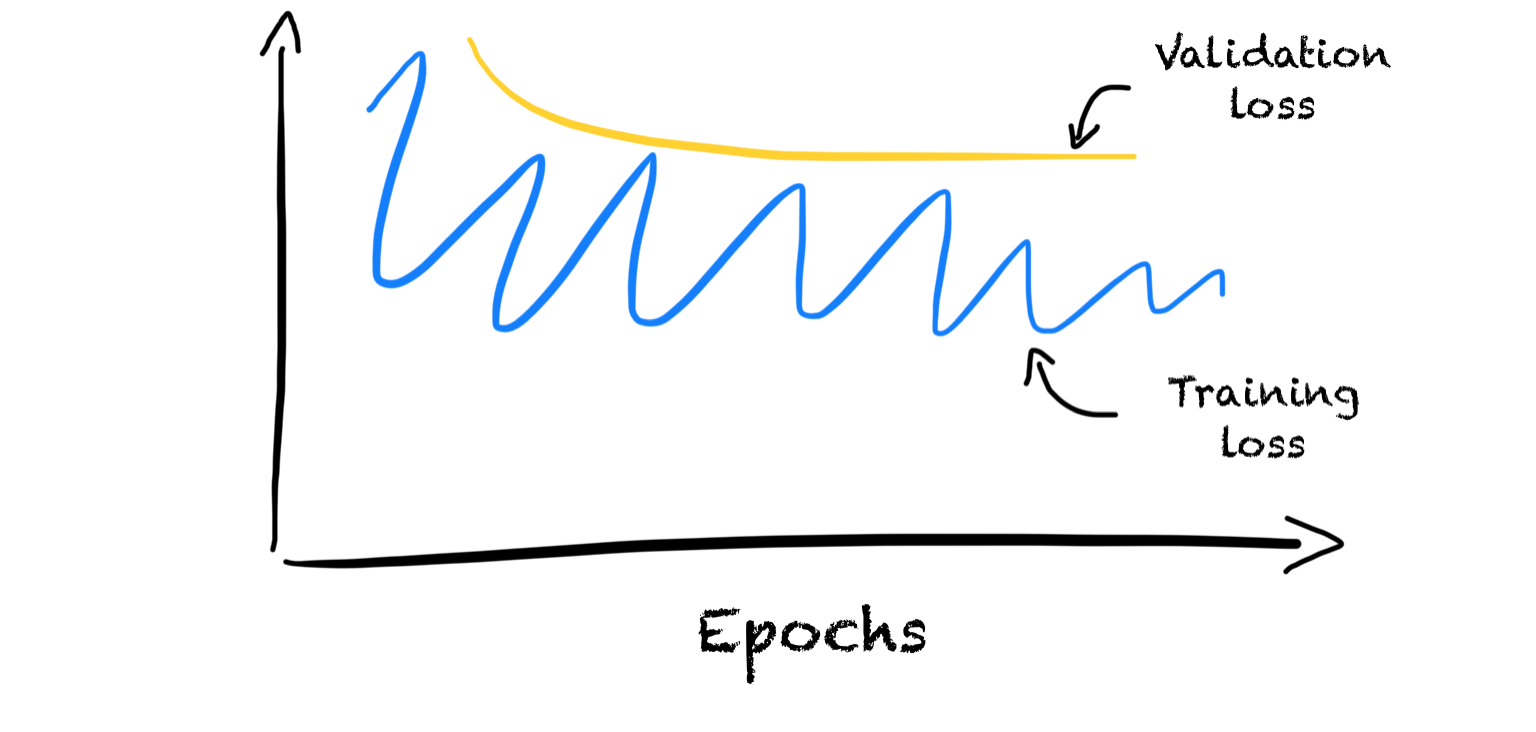
Problems with the validation set can appear in two ways. First, the training learning curve looks like a good fit but the validation learning curve is very jagged. Second, the validation loss is smaller than the training loss. Reasons for such a behavior could be that the validation set is too small or easier to predict.
An unstable training learning curve usually indicates a wrong choice of hyperparameters. One solution can be to decrease the learning rate or increase the batch size.

Learning curves are a valuable tool to identify problems with our ML models. But they are often overlooked. Learning curves help us to
- diagnose model performance during training. Is the model underfitting or overfitting?
- communicate results.
- estimate if our training and validation sets are suitable and sufficient for model evaluation.
- finetune hyperparameters, such as learning rate, batch size, and regularization.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


