


Hypothesis Testing Simplified.
Last Updated on May 9, 2024 by Editorial Team
Author(s): Karan Kaul | カラン
Originally published on Towards AI.
Storytime
Imagine this —
- You got a new personal high score of 98 on your favourite game.
- You feel proud of this achievement & you share this news with a friend.
- However, your friend isn't impressed 🙁
- He implies that a score of 98 is fairly common for that game & isn’t such a big deal.
- You don't believe him & you decide to challenge his statement.
- You propose that by using statistics, you can prove how rare/less likely it is to get a score of 98.
What we just saw, is a scenario where we are trying to test a claim. Your friend said that a score of 98 is fairly common for the game. This statement is a status quo or ground truth or a statement that we know normally holds true.
By rejecting or proving his statement wrong, we are indirectly proving our own statement correct. We can prove him wrong if we somehow manage to prove that the mean score for this game is less than 98, which means our score is higher than what most people usually score.
Okay, so what are the Null & Alternate Hypotheses?
Whatever is already true or evident, forms the Null Hypothesis.
H0 : “Our score is less than or equal to the mean scores”
The claim that we are trying to prove, forms the Alternate Hypothesis.
H1 : “Our score is greater than the mean scores”
How do we test our claim & reject his statement?
First, we need to figure out whether our event of scoring, is dependent on other player scores or not.
It is quite apparent that this event is indeed “Independent”. Other players don't affect our scoring at all. Hence we will employ an Independent samples t-test to test our claim.
What is an Independent Sample t-test?
We employ this test when –
- The population standard deviation is unknown
- Samples are independent
This test gives us a statistic or a value. This value represents how far away from the mean, our sample lies. To be specific — how many std. devs away are we from expected average scores.
We can also find the p-value(probability) associated with this result from a t-table.
Note — If we say that our sample is 2 Std.dev away from the mean, we don't necessarily imply that our sample is 2 std.dev above the mean or lower.
If we only care about being different from the mean, we don't care if we score higher or lower, it just has to be different from the mean. In this scenario, we employ a 2 tailed independent sample t-test.
However, in our case, we want to prove that we scored higher than the average. Hence, we need to be above the mean. This calls for a 1 tailed independent sample t-test.
😲 This is a lot of information to grasp if you are a beginner. I recommend going through this wonderful playlist on statistics for a better understanding. (This is my fav stats playlist on YT!)
But how far above should our value be from the mean, to prove our friend wrong?
Suppose the average score is 60.
Can we say — that a score of 70 & being 1.2 Std. dev above the mean is enough? Or a score of 75 & being 1.5 std. dev above the mean is? …
We need a fixed value, above which we can reject our friend's claim & prove ours correct.
This value of std. dev, above which we can reject our friend's claim, is called the Critical Value.
This critical value relates to a defined alpha/significance level. A 95 % significance level(alpha 0.05), when paired with a one-sided t-test signifies — most scores are expected to lie within 95% of the distribution or within 2 std. devs above the mean.

This critical value is associated with the alpha chosen, it is not random. If we instead chose alpha = 0.01 or 99% significance level, the std. dev value(critical value) associated with it, would be further towards the right above the mean.
You might now be able to infer —
- If we want to be very specific in our test i.e. our value should lie significantly far from the average values, then we will employ a small alpha such as 0.01 which means 99% significance. (The critical value/std.dev to beat would be higher)
- If we don't want such specificity, we can choose a normal alpha such as 0.1, which means 90% significance. This would result in a higher probability of rejecting the null since we don't expect our sample to be very far from the mean & would reject the null even with this smaller difference. (The critical value/std.dev to beat would be smaller ~)
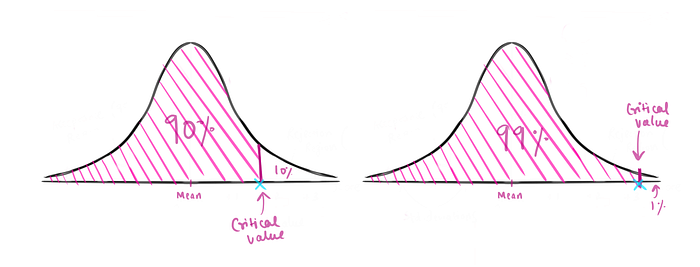
Suppose our test statistic that we calculate using the t-test exceeds the critical value that we got using alpha & a t-table. In that case, observing the value we got would be considered a rare event & this would provide us with enough statistical evidence regarding the difference between the expected & observed values.
Hence, we would reject the claim “Our score is less than or equal to the mean scores”.
Hypothesis testing (Python & Scipy)
Libraries
Import the following libraries. We will also employ some basic visualizations to understand the data better.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
sns.set()
Data/Samples
We need a sample of scores from other players. A list called sample_scores contains these scores —
sample_scores = [1,5,6,10,15,20,25,27,31,35,40,40,41,41,41,46,46,45,46,47,50,51,52,58,60,60,60,60,60,61,61,62,65,66,67,70,70,71,71,73,74,75,75,75,76,78,80,81,81,82,92,83,85,86,86,88,90,98,102,113]
print(len(sample_scores))
# 60
Let’s get a summary of our samples —
summary = stats.describe(sample_scores)
print(summary)
# DescribeResult(nobs=60, minmax=(1, 113), mean=59.266666666666666, variance=637.012429378531, skewness=-0.43382097754515087, kurtosis=-0.2625823356606394)
Save the mean and std. dev in separate variables. We need to take the square root of variance to get the std. dev —
# mean is the 2nd item in the list
mean = np.round(summary[2],3)
# variance is the 3rd item in list, we sqrt it to get std. dev
std = np.round(np.sqrt(summary[3]),3)
print(mean, std)
# 59.267 25.239
Visualize
Visualize the distribution of the samples, along with the mean & 2 standard deviations on both sides of the mean —
plt.figure(figsize=(10,5))
sns.histplot(sample_scores, kde=True)
plt.axvline(mean, color='r', linestyle='dashed', linewidth=2, label='Mean')
plt.axvline(mean + std, color='g', linestyle='dashed', linewidth=2, label='+1 Std Dev')
plt.axvline(mean - std, color='g', linestyle='solid', linewidth=2, label='-1 Std Dev')
plt.axvline(mean + std*2, color='b', linestyle='dashed', linewidth=3, label='+2 Std Dev')
plt.axvline(mean - std*2, color='b', linestyle='solid', linewidth=3, label='-2 Std Dev')
plt.legend()
plt.show()

Some inferences we can make from this plot —
- The avg. score is around 60
- Scores are distributed Normally
- A score of ~85 is +1 std. dev above the mean
- A score of ~32 is -1 std. dev under the mean
- A score of ~115 is +2 std. dev above the mean
- A score of ~8 is -2 std. dev under the mean
Looking at the histogram, how many std. dev away, do you think our score of 98 is?
It’s around ~1.7 std. dev above the mean, but to get an exact value, we need to perform the t-test.
Choosing Alpha & the Test Type
We will choose alpha = 0.1(90% significance), which means that if the probability of getting a score of 98 comes out to be < 10%, we will reject the null & accept the alternate hypothesis.
In other words — A score of 98 had a very low probability & we still got it, which means this is not a random or by-chance outcome, so we must believe that this result is significantly different from the expected results.
Similarly, if we choose alpha = 0.01(99% significance), then we will reject the null if the probability of getting a score of 98 comes out to be < 1%.
(0.01 alpha would be a very hard case to beat, considering a score of 98. Maybe a score of 105 or higher would beat an alpha of 0.01? hmm…)
# the score we got
our_Score = 98
# alpha level for testing
alpha = 0.1
Calculate the t-statistic & p-value —
# Perform independent sample t-test
# set alternate = "greater" as we want to check if our score is > avg scores
t_statistic, p_value = stats.ttest_ind(our_Score, sample_scores, alternative="greater")
# Display the t-statistic and p-value
print("t-statistic:", round(t_statistic,5))
print("p-value:", round(p_value, 5))
if p_value < alpha:
print(f"Given alpha {alpha}, we can reject the H0. A score of {our_Score} is {t_statistic} std.dev away from the sample mean.")
else:
print(f"Given alpha {alpha}, we cannot reject the H0. A score of {our_Score} is {t_statistic} std.dev away from the sample mean.")
# t-statistic: 1.52202
# p-value: 0.06667
# Given alpha 0.1, we can reject the H0. A score of 98 is 1.5220244457378458 std.dev away from the sample mean.
Interpreting the Results
- t-statistic came out to be 1.52. Now we know, a score of 98 is precisely 1.52 std. dev above the mean.
- p-value for a t-static of 1.52 is 0.066. This means the probability of getting a score of 98 was only 6%.
- 6 % is less than our chosen alpha of 10%, hence we reject the null & accept the alternate hypothesis.
Conclusion
At a 90% significance level, we have statistical evidence that a score of 98 is significantly higher than the average.
Let’s test at a smaller alpha of 0.01 or 99% significance level —
our_Score = 98
alpha = 0.01
t_statistic, p_value = stats.ttest_ind(our_Score, sample_scores, alternative="greater")
print("t-statistic:", round(t_statistic,5))
print("p-value:", round(p_value, 5))
if p_value < alpha:
print(f"Given alpha {alpha}, we can reject the H0. A score of {our_Score} is {t_statistic} std.dev away from the sample mean.")
else:
print(f"Given alpha {alpha}, we cannot reject the H0. A score of {our_Score} is {t_statistic} std.dev away from the sample mean.")
# t-statistic: 1.52202
# p-value: 0.06667
#Given alpha 0.01, we cannot reject the H0. A score of 98 is 1.5220244457378458 std.dev away from the sample mean.
Interpreting the Results
- t-statistic came out to be 1.52. Hence, a score of 98 is 1.52 std. dev above the mean.
- p-value for a t-static of 1.52 is 0.066. This means the probability of getting a score of 98 is 6%.
- 6 % is greater than our chosen alpha of 1%, hence we fail to reject the null.
Conclusion
At a 99% significance level, we dont’ have any statistical evidence that a score of 98 is significantly higher than the average.
That’s all for this post! 🙌
I hope this article explains Hypothesis testing or the idea behind it. Please drop some claps, comments & share this post if you found it useful. If I mentioned anything wrong or if you have any suggestions, I would love to hear them.
Check out these other useful articles —
Langchain x OpenAI x Streamlit — Rap Song Generator🎙️
Learn how to create a web app that integrates the Langchain framework with Streamlit & OpenAI’s GPT3 model.
pub.towardsai.net
After reviewing tons of resources, here is — How To Make Your Python Code Run Faster 🏃🏻💨
Practical tips on improving your Python code’s performance, with time comparisons. (Try them out & see the difference!)
python.plainenglish.io
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

