



Underwater Object Segmentation Using MonkAI
Last Updated on January 6, 2023 by Editorial Team
Author(s): Omkar Tupe
Computer Vision
Table of contents
- About the project
- Monk Toolkit
- Segmentation
- Unet
- Inference based on an already trained model
- Training
- Inference(Post Training)
- Conclusion
- References
1. About the project
This project focuses on segmenting different objects such as animals, plants, plastic, and ROV(Remotely Operated Vehicle) using a low code wrapper Monk [2]toolkit via Unet[1]. It is essential to understand the sea garbage collection. For employing an automatic river or sea trash cleaner system should have a proper understanding of different objects present in the water. This project helps to develop such a system on small scale. Through this blog, I will share some insights about MonkAI, and how it can be used to simplify the process of object segmentation and build other computer vision applications.
Tutorial available on Github

2. Feature of Monk AI[6]
- Quick mode for beginners
- It is possible to access PyTorch, MXNet, Keras, TensorFlow, etc. with a common syntax.
- Standard workflows for simple transfer learning applications
- For Competition and Hackathon participants: The hassle-free setup makes prototyping faster and easier
3. Segmentation[4]
By segmentation, we can understand the category of each pixel which can help us to understand the location of the object in an image, shape of an object. Image segmentation helps to generate output a pixel-wise mask of the image. Image segmentation finds application in medical imaging, self-driving cars, and satellite imaging.
A. Semantic segmentation
Semantic segmentation helps to label each pixel of an image with a corresponding class of what being represented. The following picture can help us to understand the difference between object detection, semantic segmentation, and instance segmentation.

B.Instance segmentation
For example, in the image above there are 3 people, technically 3 instances of the class “Person”. But semantic segmentation does not differentiate between the instances of a particular class.
4. Unet
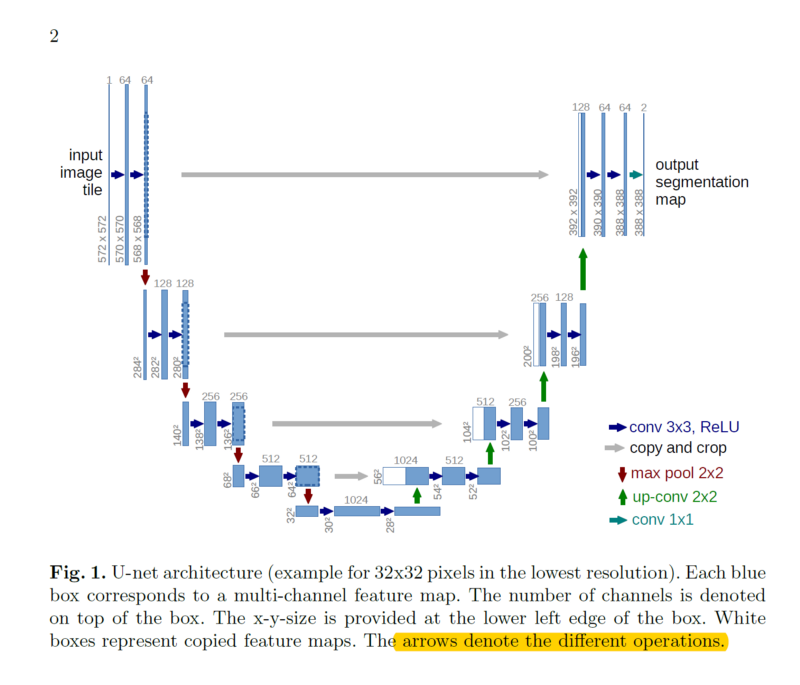
The Unet[1] was developed by Olaf Ronneberger et al. for BioMedical Image Segmentation. The architecture contains two paths.
The first path i.e encoder or contraction path is used to capture the context of the image. The encoder consists of a traditional stack of convolutional and max-pooling layers. The second path i.e decoder or symmetric expanding is used to enable precise localization using transposed convolutions.
In the original paper, the UNET is described as follows:
5. Inference based on an already trained model
A. Installation instructions
For training the network a CUDA GPU is preferrable (which is also provided by Google Colab); but one can use a local device or Kaggle notebook. Now we will set up the MonkAI toolkit and dependencies on the colab
B. Inference(Pre-trained model)
We need to set required libraries for inference and some hyper-parameters along with a dictionary of classes.
Downloading the pre-trained model.
Now we will define the model, backbone, and path for the pre-trained model.
From the unzipped folder, we are using some images for inference purposes.
Inference-1

Inference-2

6. Training
We are using a dataset from the Data repository[3]
Time to download our dataset.
Monk directory
Before generating the mak images we need to check whether the dataset is balanced or not
“Everyone wants to be perfect. So why should our dataset not be perfect? Let’s make it perfect”

In the given dataset, we can easily see that data is highly imbalanced which is harmful to better generalized accuracy. To achieve approximately equal accuracy for all classes we should have an equal number of objects from each class.
From the above stats, we can see that data is highly imbalanced especially rov and trash category objects are more as compared to the other classes. For demonstration purpose, we are using 4 classes i.e plant, rov, animal, trash
We are choosing 20 objects from each category and grouping them according to the main category
The above discussion is implemented through code on Github.
4 Main categories
- ROV
- Plant
- Animal-animal_eel, animal_crab, animal_etc, animal_fish, animal_shells, animal_starfish
- Trash-trash_etc, trash_fabric, trash_fishing_gear, trash_metal, trash_paper,trash_plastic,trash_rubber,trash_wood
So in the final count, we have approximately 150 objects for each main category. Now based on balanced data we will make mask images of selected images. We are assigning pixel value-
0- Background
1- ROV
2- Plant
3- Animal
4- Trash
We have 443 images having a total of 580 trainable objects this implies that we have more than 1 object in some images.
Now we will generate mask images based on the above-selected images. (Code)For segmentation training, we need a path for original images as well as mask images. In the class dictionary, we have 5 categories with pixel-values from which we are excluding background for training, as we are interested in the main categories.
Monk is providing a wide range of backbones from which we are using efficientnetb3 along with the Unet model which is one of the recommended and image size-(384,384). We are setting the learning rate as 0.0001 and 120 epochs. (For detailed implementation please check the file).IoU=0.45 is achieved
7. Inference(Post-training)
Now we are interested to understand the results of our trained model. It will be similar to the pre-trained model but now we will use our own trained model so the model path will be different.
- Set inference engine
- Define classes
3. Provide some images for testing.
Test image-1

Test image-2

We can observe good results from the above test images. You can find more results on Github.
8. Conclusion
As compared to other categories area covered by rov in images is more so we have more pixels for training so the result is slightly biased towards rov. We have obtained these results by simultaneously adjusting a large number of hyperparameters — which usually takes a long time to do. However, we were able to complete this challenging task within a considerably small time frame because of Monk. We created segmentation pipelines with just a few lines of code with Monk. Trying out multiple pairs of backbone and models can also help to get better results. Overall, Monk AI is a great library which considerably simplifies performing computer vision tasks. You can find the code in this article here.
For more examples of detection and segmentation, please visit the application model zoo.
Thanks for Reading! I hope you find this article informative & useful. Do share your feedback in the comments section!
9. References
- Unet-https://arxiv.org/abs/1505.04597
- Monk AI-https://github.com/Tessellate-Imaging/Monk_Object_Detection
- Dataset-https://conservancy.umn.edu/handle/11299/214865
- Segmentation-https://towardsdatascience.com/computer-vision-instance-segmentation-with-mask-r-cnn-7983502fcad1
- Features of Monk AI-https://devpost.com/software/monkai
Underwater Object Segmentation Using MonkAI was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

![Top 15 Computer Vision Datasets [2026]](https://miro.medium.com/v2/resize:fit:700/1*e9tj4kRR7dH_IV8topwfdw.png "Top 15 Computer Vision Datasets [2026]")

")
Recent Posts




")

