



Making Hyper-personalized Books for Children: Faceswap on Illustrations
Last Updated on December 12, 2020 by Editorial Team
Author(s): Francesco Fumagalli
Computer Vision
Stories have always been part of human nature: we’ve been telling stories to children for as long as we’ve been around, to teach them about life, to warn them about dangers, to build up their character without risking their safety.
Stories are extremely important, and books are one of the main means by which they are told. With books, the reader identifies with the characters and feels their emotions. We want the reader to connect with the book as deeply as possible, and we want both the story and the illustrations to reflect who you are, personally: imagine a book whose main character actually looks like you; imagine a book where problems are solved the way you’d solve them; imagine a book that is truly about you, uniquely you. This is our goal.

Personalized books already exist. Where’s the difference?
If you’re familiar with the world of literature for kids, you’ll know that personalized books have been a thing for a very long time, so where’s the difference between this project and something that can be found on Wonderbly or Dinkleboo?
Those books allow you to choose the main features of an avatar among a number of available choices (blonde or brown hair? Green or blue eyes?), whereas in our implementation, the main character’s face actually looks like the reader, accomplished by doing a faceswap.
The personalized text is also different. It isn’t just the name you choose that gets printed in the book, but also the way the protagonist tackles problems: will he succeed because of his overwhelming strength or cunning intellect? A few key personality traits are inserted while ordering the book and affect the way the story unfolds, making it truly unique.
The focus of this article is on the illustration problem: developing a program able to position and adapt the user’s face on a drawn body. The clients should be able to see a preview of the illustrations before purchasing the book, so our implementation must provide results quickly and efficiently.
What is a faceswap?
A faceswap is the process of swapping faces between two individuals on an image (usually a picture) or video.
From a computer’s point of view, images are rows and columns of pixels, matrices of numbers representing colors and shapes. Computer Vision is a subfield of AI and Machine Learning dedicated to studying how to make a machine see images the way we see them: in our use case, understanding which pixel values represent a face.
Once this first step of facial detection has been completed, the program has to swap the pixels of the face areas between the two targets, adapting the colors and shapes to make the final result smoother.
Deepfakes and other face-swapping applications for realistic images have hogged the spotlight because of their impressive results, but little attention has been paid to different contexts, such as the one concerning our task: will technologies developed to work well on pictures also be effective on drawings? Let’s find out.
Differences from picture-to-picture faceswap
The first thing we did was trying various established face-swapping techniques to see what kind of issues may arise when working with drawings instead of pictures.
A widely adopted approach is dlib’s face detection process: identifying the Facial Keypoints in order to swap faces between pictures later on. It learns how to recognize a face using Machine Learning techniques (Haar cascades or HOG + Linear SVM detectors), but we’ve noticed there were drawings where a face was harder for the machine to recognize: if the face had too few details, the software could use a little help.

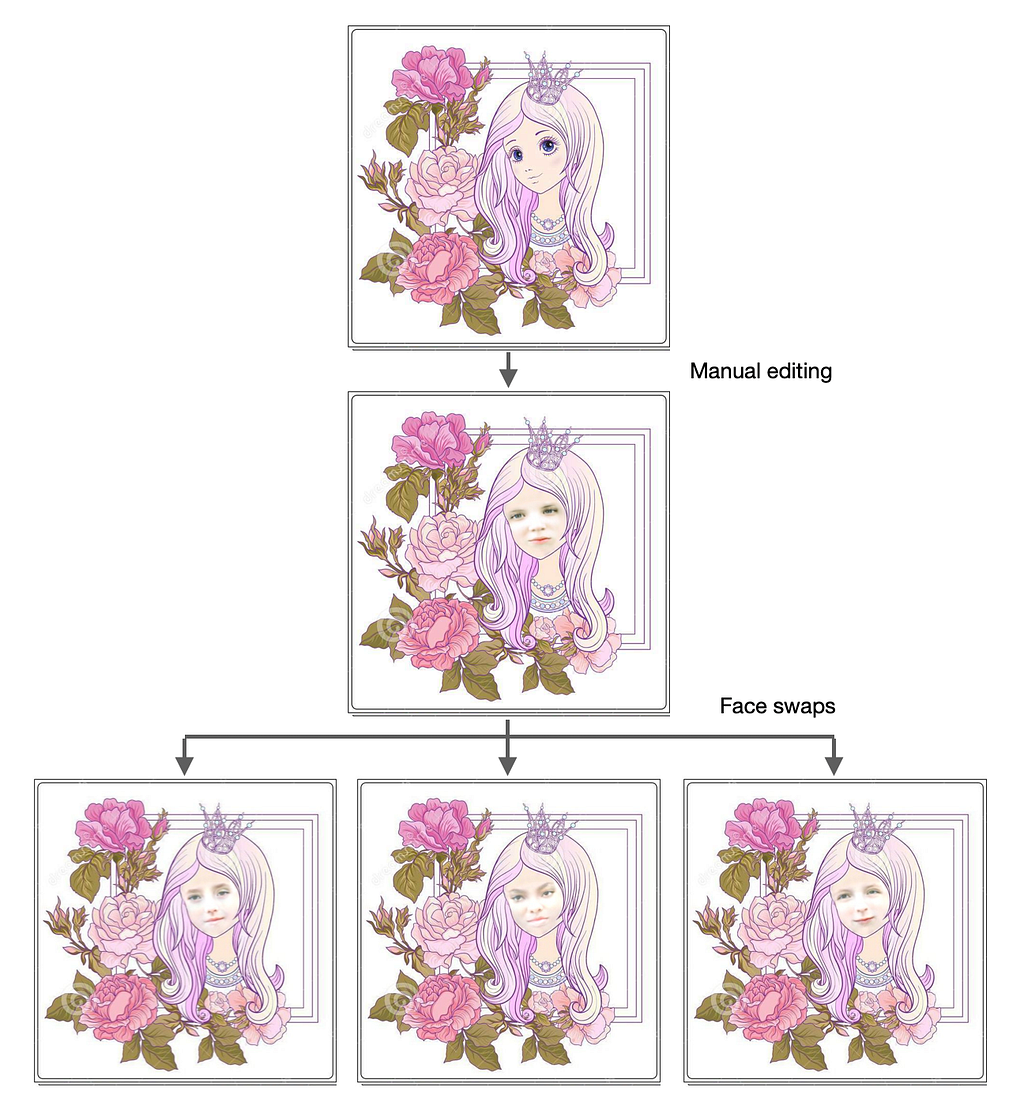
To solve this issue, a realistic face can be manually edited on problematic drawings before the faceswap. It’s slightly time-consuming but ensures proper performance in the face detection process and, if done properly, it won’t be noticed by the final user, being something that only happens behind the screen.
The first face-swapping application we tried to get a baseline on the quality of the results was Reflect’s FaceSwapping. In our experiments, its effectiveness varied a lot depending on the style of the drawing: drawings with too few details often resulted in poor performances.
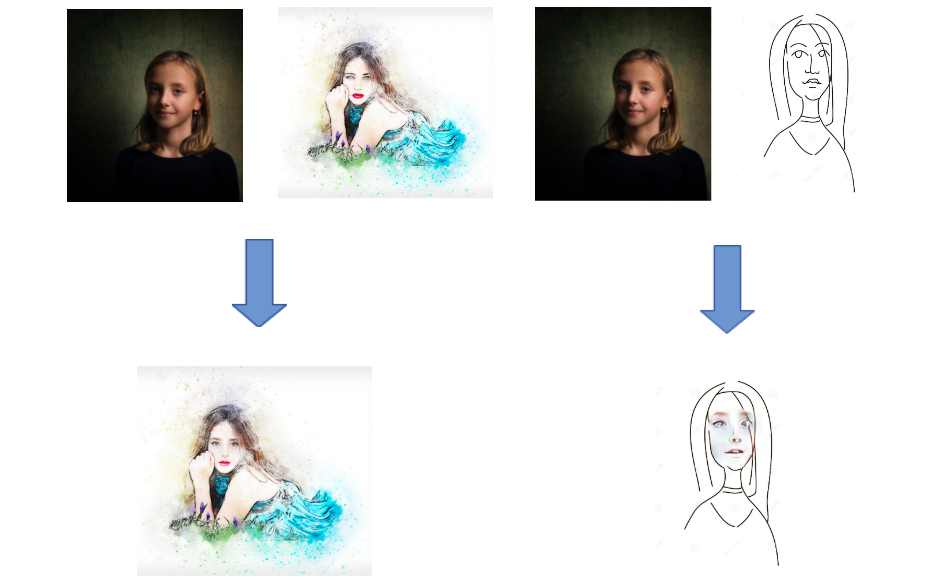
To get another baseline, we tried DeepFaceLab: DeepFaceLab is a household name in the DeepFake industry; its main focus being swapping faces in videos, not exactly our goal. The program is optimized for learning shadows and angles from many frames, and from what we gathered through trial and error, it doesn’t seem to perform too well on drawings (or requires too much hyperparameter tuning to get appreciable results). It also took way too much time to be useful for our goal: remember, our customers should be able to get a preview of the edited image in a matter of seconds or minutes at most.
We also tried shaping the face into the same hand-drawn style of the illustrations using Deep Dream Generator to see whether a Neural Style Transfer was worth working on, but the results we got weren’t very encouraging (perhaps there weren’t enough details in the drawings to correctly implement them as a style).

Those kinds of results, on top of still having to properly crop the face and perform the faceswap later on and thus requiring additional time and computational resources, made us dismiss this approach.
Our solution
Comparing the above-mentioned results, we realized that, for this project:
- Photo-realism isn’t an issue, and we don’t need a lifelike result but something that looks like a drawing
- Delivery time is essential: we need something that produces results quickly to present them to a potential customer
- We only have one picture and a few drawings to feed to our algorithm
- We need a program that works reliably. We can’t fine-tune parameters for each iteration or discard bad results. The user should be able to use it autonomously
- dlib’s Face Detection works well (with the occasional adjustment mentioned above)
Hence we opted not to use a Neural Network, i.e., the technology used by each previously shown application, even though very effective for picture-to-picture swaps.

Instead, once dlib applied the facial landmark detector to obtain the (x, y)-coordinates of face regions, our algorithm proceeds as follows:
- First, it maps both faces via a Delaunay triangulation, basically maximizing the minimum angle of the triangles created among landmark points, avoiding overlaps and very acute angles;
- It calculates the affine transformation matrix for each triangle vertex from the “mask” (the face in the picture) to the face in the drawing in order for it to assume the same shape;
- At last, it uses Poisson Blending to overlap this mask on the drawing while also applying bilinear interpolation to smoothen shapes and gaussian blur to correct colors (in addition to a few more checks and small corrections) to make sure the face is properly edited.
Here’s the final result:

This is almost as good as the State of the Art, Neural Network-driven best results and applicable to a wider range of drawings for a fraction of the cost (it only takes a few seconds for the program to run and only requires the source and target images as inputs), making it the ideal solution for our task.
Thank you for reading!

About Digitiamo
Digitiamo is a start-up from Italy focused on using AI to help companies manage and leverage their knowledge. To find out more, visit us.
About the Authors
Fabio Chiusano is the Head of Data Science at Digitiamo; Francesco Fumagalli is an aspiring data scientist doing an internship.
Making Hyper-personalized Books for Children: Faceswap on Illustrations was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts

![Top 15 Computer Vision Datasets [2026]](https://miro.medium.com/v2/resize:fit:700/1*e9tj4kRR7dH_IV8topwfdw.png "Top 15 Computer Vision Datasets [2026]")

")
Recent Posts




")

