



Use Google Vertex AI Search & Conversation to Build RAG Chatbot
Last Updated on November 5, 2023 by Editorial Team
Author(s): Euclidean AI
Originally published on Towards AI.
Google has recently released their managed RAG (Retrieval Augmented Generator) service, Vertex AI Search & Conversation, to GA (General Availability). This service, previously known as Google Enterprise Search, brings even more competition to the already thriving LLM (Large Language Model) chatbot market.
This article assumes that you have some knowledge on the RAG framework for building LLM-powered chatbots. The diagram below from Langchain provides a good introduction to RAG:

In this article, we are mainly focused on setting up an LLM Chatbot with Google Vertex AI Search & Conversation (we will use Vertex AI Search in the rest of the article).
Solution Diagram
Datastore
Vertex AI Search currently supports html, pdf, and csv format source data.

Vertex AI Search currently supports html, pdf, and csv format source data. Source data is collected from Google’s search index (the same index used for Google Search). This is a major advantage compared to other providers that require separate scraping mechanisms to extract website information.
For unstructured data (currently, only pdf and html are supported), files first need to be uploaded to a Cloud Storage bucket. This storage bucket can be in any available region.
U+26A0️ The datastore on Vertex AI Search is different from Cloud Storage. It is similar to the “vector databases” often referred by other providers.
Each app on Vertex AI Search currently will have its own datastore(s). It’s possible to have multiple datastores under a single App.
For demonstration purposes, we will use a student handbook sample pdf available online (https://www.bcci.edu.au/images/pdf/student-handbook.pdf). Note: we are not affiliated with this organization (it’s just a sample pdf we can find online…)
Step 1 — Prepare the pdf files:
Split the single pdf handbook into multiple pages using Python. This only takes seconds.
from PyPDF2 import PdfWriter, PdfReader
inputpdf = PdfReader(open("student-handbook.pdf", "rb"))
for i in range(len(inputpdf.pages)):
output = PdfWriter()
output.add_page(inputpdf.pages[i])
with open("./split_pdfs_student_handbook/document-page%s.pdf" % i, "wb") as outputStream:
output.write(outputStream)
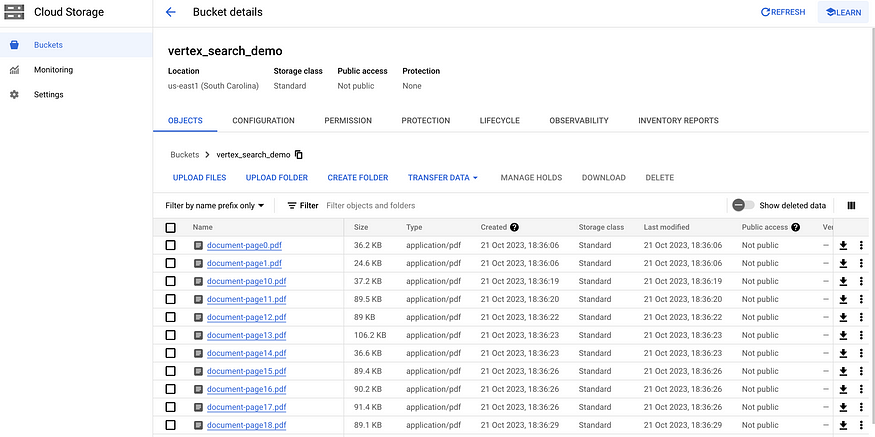
Step 2 — Upload to GCS Bucket:
We will need to upload the pdfs to a google Cloud Storage. You can either do it through the Google Console or Use GCP SDK with any language of your choice.
If only a single pdf document is required, ‘clickops’ will suffice for this demonstration.
Let’s drop the pdfs to a Cloud Storage bucket.
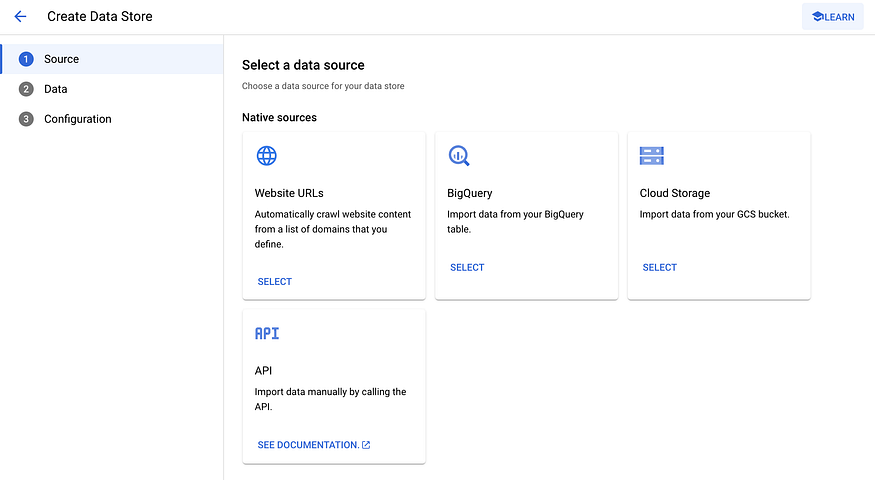
Step 3 — Set up App and Datastore:
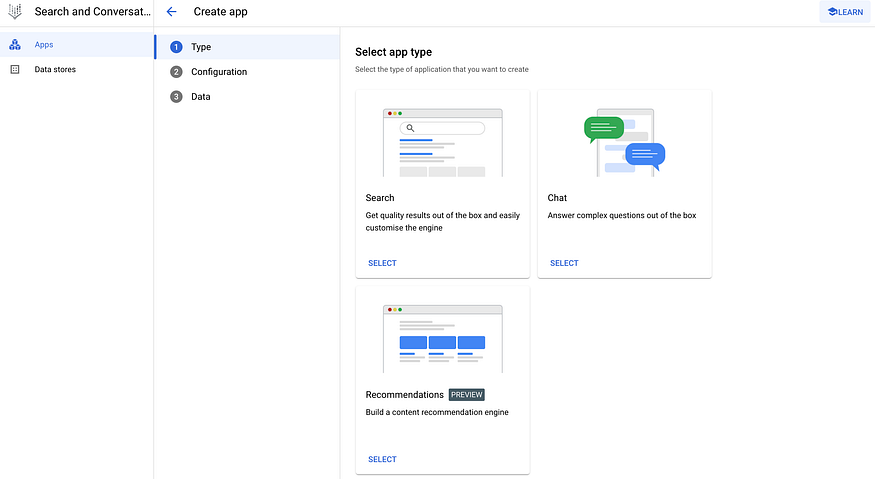
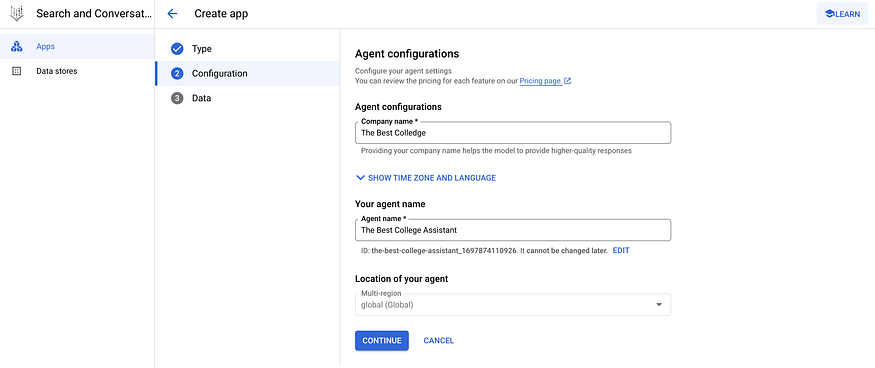
In the GCP console, find ‘Search and Conversation’ and click on ‘Create App’. Select the Chat app type. Configure the app by naming the company and agent. Note: the agent is only available in the Global region.
Next, create a data store. Select ‘Cloud Storage’ and choose the bucket created in step 2.
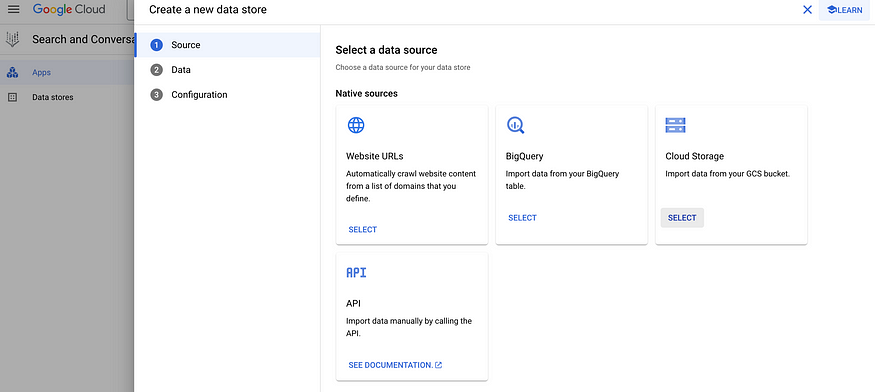
Then, it will ask you to create a data store. Again, this is actually a vector datastore that stores the embeddings for semantic search and LLM to work.
Select ‘Cloud Storage’. Then, select the cloud storage that we created in the last step.

After this, click on ‘Continue’. Then, the embedding will start. This process will take anywhere from a few minutes to an hour, depending on the amount of data. Also, GCP has sdk libraries with async clients available, which can expedite the whole process. Otherwise, you can always use GCP console. It uses synchronous API calls by default.
You can check the import (embedding) progress under the activity tab.

Once the import is completed, head over to ‘Preview’ on the left, it will take you to a Dialogflow CX Console.
Step 4 — Dialogflow:
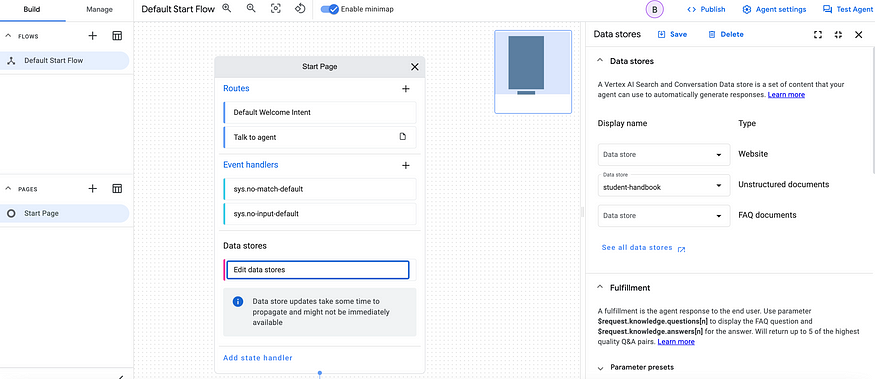
On the Dialogflow Console, click on ‘Start Page’. It will open the data store settings on the right. You can select multiple data stores (website, pdfs, etc. at the same time). In this case, leave it to be the student handbook that we created in Step 3.
Find ‘Generator’ under data store settings.

Add the following prompt:
You are a virtual assistant who works at The Best College. You will provide general advice to the student based on the student handbook. Always respond politely and with constructive language.
The previous conversation: $conversation \n
This is the user's question $last-user-utterance \n
Here are some contextual knowledge that you need to know: $request.knowledge.answers \n
You answer:
$conversation, $last-user-utterance, $request.knowledge.answers are Dialogflow parameters.
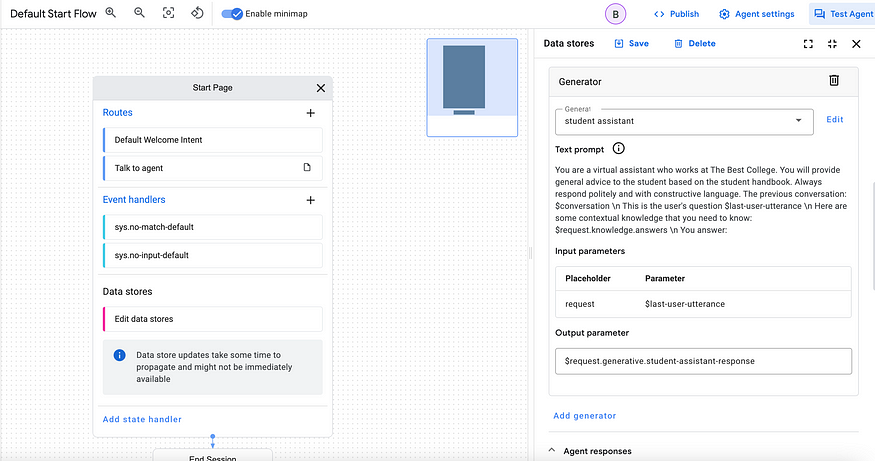
In the ‘Input Parameter’, type in $last-user-utterance. This will pass the user’s question to the generator. In the ‘Output Parameter’, type in $request.generative.student-assistant-response. Always remember to hit ‘Save’ button on the top!
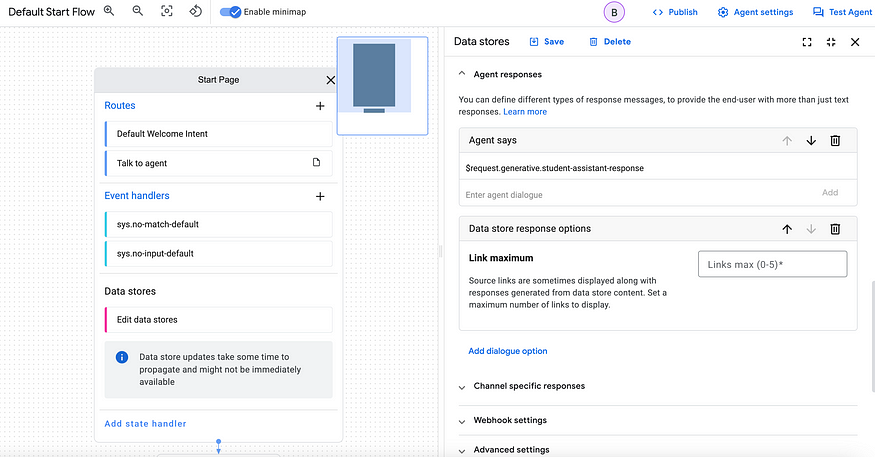
Under Agent says, don’t forget to type in $request.generative.student-assistant-response. This will make sure the output from the generator gets picked up in the agent chat.
Step 5 — Testing & Integration:
To test this bot, you can either click on the ‘Test Agent’ simulator in the top right corner or use the Manage Tab on the Left to pick an integration. Personally, I prefer using ‘Dialogflow Messenger’ to ‘Test Agent’, as it shows me the final response format.

Once you click Dialogflow Messenger, choose ‘enable the unauthenticated API’. This is just for testing. In the real case scenario, depending on your authentication requirements, you can choose whether you want to enable this.


Now, you can type in the questions you have. The answers generated by RAG will be based on the student handbook pdf. It also comes with a reference link at the bottom. If you click on it, it takes you to the particular pdf page that contains the information.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

