



READ Avatars: Realistic Emotion-controllable Audio Driven Avatars
Last Updated on August 26, 2023 by Editorial Team
Author(s): Jack Saunders
Originally published on Towards AI.
Adding Emotional Control to Audio-Driven Deepfakes
One of the critical limitations of existing audio-driven deepfakes is the need for more ability to control stylistic attributes. Ideally, we would like to change these aspects, for example, making a generated video happy vs. sad, or to use the speaking style of a particular actor. READ Avatars looks to do exactly this, by modifying existing, high-quality, person-specific models to work with direct control over styles.
Having written several blog posts covering deepfake models in the past, this one has special significance to me, as it is my own. The paper has just been accepted to this year’s BMVC and it is my first accepted paper! In this article, I will cover the motivation, intuition and methodology behind the work.
What is Style?
The first place to start when considering stylistic control is to ask exactly what is meant by style. The answer I usually give is a bit of a cop-out: Style is anything in our data that is not considered content. This may seem to merely shift the definition from one word to another, but it does make the task easier. In the context of audio-driven deepfakes, content is the speech itself, the lip movements that match the audio, as well as the face’s appearance.
That means style is anything that modifies the video while looking like the same person and maintaining lip sync.
In the case of my research, I usually look at two particular forms of style: emotional and idiosyncratic. Emotional style is simply the emotion expressed on the face, whereas idiosyncratic style refers to the difference in expression between individual people. For example, the way a smile looks on my face compared to yours is an example of idiosyncratic style. These are not the only kinds of styles, but they are among the easiest to demonstrate and work with. For this work, we used emotion styles only, as we worked on person-specific models.
Representing Emotional Style
READ Avatars is not the first paper to look at altering emotional style in audio-driven video generation. However, previous methods have represented emotion as either a one-hot vector or an abstract latent representation (check out EVP and EAMM for respective examples). The former does not have enough precision to allow for fine-grained emotional control and the latter does not have semantic meaning. For this reason, we decided to use a different representation of emotion.
To represent N different emotions, we use an N-dimensional vector where each dimension represents one of the emotions and has a real value between 0 and 1. We let 1 be the maximum possible expression of that emotion. A vector of all zeros is, therefore the absence of emotion (aka neutral).
The Baseline
In order to achieve the highest possible visual quality, we base our model on the 3DMM-based approach of previous work. I have covered these in a previous article if you’re interested! In particular, we use the neural textures approach, where we train a uv-based, many-channeled texture jointly with an image-to-image UNET.
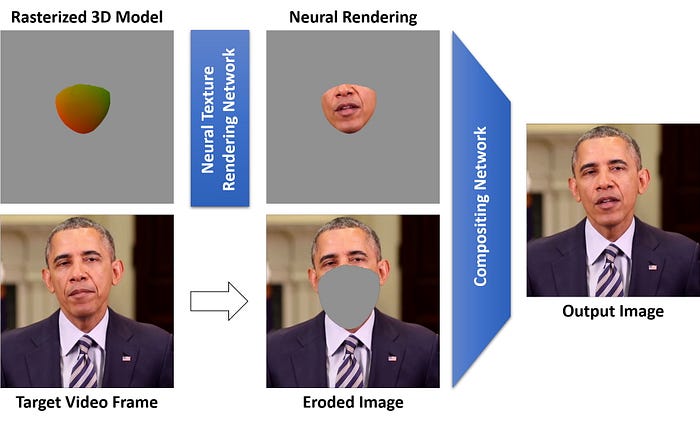
As we want to work with emotion, we need to generate the whole face, not just the mouth region. To do this, all we need to do is change the mouth mask (as can be seen in the image above) into a full face mask.
A naive approach may simply be to condition the audio-to-expression network on the emotional code we just defined (check out my past post for more details on audio-to-expression networks). This does not work as well as one would hope, however. We suggest two potential reasons for this, the lack of detail in the underlying 3DMM and the over-smoothing effects of regression losses.
Lack of Detail in 3DMMs
The first of the issues has to do with the inability of 3DMMs to represent the geometry of the face. The problem is twofold. First, the 3DMM struggles to capture the “O” shape of the lips. This can be seen in the figure below. More of an issue though, is the complete lack of any form of representation of the mouth interior, including the teeth and tongue.

This leads to potential ambiguities in the renderings passed to the image-to-image network. For example, without the tongue the sounds “UH” and “L” are expressed in the same way, in this case, how does the network know what to generate inside the mouth?
To overcome this issue, we add audio directly into the video generation process. We do this by conditioning the neural texture on the audio. We use the intermediate layers of Wav2Vec2 as a feature extractor and encode that audio to a latent representation. This is then used to condition a SIREN network, using 2D positional encodings, that outputs a 16-channel neural texture that varies with audio (see below). For more details on the architecture, you can have a look through the arxiv version of the paper.

This inclusion allows the image-to-image network to have enough information to resolve such ambiguities.
Smoothness From Regression Losses
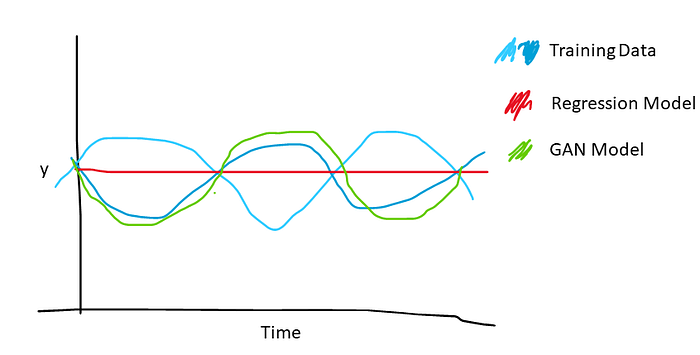
Existing audio-to-expression models are trained with regression-based losses, usually L1 or L2. These have a noticeable drawback for facial animation: they create very smooth motion. Where there are two possible sequences valid for a given audio, a regression-based model will select an average of the two leading to the peaks of the motion being averaged out and producing muted motion. This is particularly important for emotional animation generation as the parts of the face not correlated with audio, such as the eyebrows, may move at any time, leading to a lot of smoothing and worse representation of emotion.
GAN-based models alleviate this. A discriminator will learn to label any smooth motion as fake, and therefore, the generator is forced to produce realistic, lifelike motion.
Results

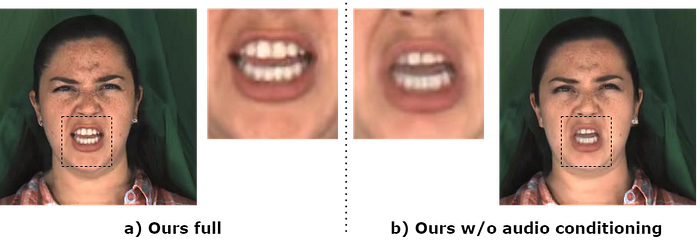
Indeed the modifications we proposed led to an improvement of the results. We have been able to produce superior results to the current state-of-the-art.
Conclusion and Future Work
READ Avatars has made a few important modifications that allow for the extension of ultra-high quality, 3DMM-based models to include emotional style. The work produces interesting results! With that being said, there are some clear drawbacks. While the lip sync is better than any existing emotional model, it is still a way off-ground truth. We think this could be improved by the addition of an expert discriminator, such as the one used in wav2lip, and with the use of better audio-to-expression models, such as Imitator.
In the future, it would be useful to modify more styles, for example, idiosyncratic style. This could be used to make, for example, Joe Biden speak with Donald Trump’s lip movements, which could be interesting! To do this, we would need to build generalized neural texture models, which is an interesting research direction and the current goal for future work.
Overall, this has been a really interesting project to work on, and I’m thrilled to get my first published paper. I’m looking forward to the research that leads on from this work. As always, if you have any questions or feedback, please let me know in the comments!
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

