



Gradient Descent and the Melody of Optimization Algorithms
Last Updated on January 11, 2024 by Editorial Team
Author(s): Abhinav Kimothi
Originally published on Towards AI.
If you work in the field of artificial intelligence, Gradient Descent is one of the first terms you’ll hear. It is the fundamental optimization algorithm used for training models.
The primary application of gradient descent is to minimise the loss function by adjusting the model parameters.
The primary application of gradient descent is in training machine learning models. During training, the model’s parameters are adjusted iteratively to minimize the difference between the predicted outputs and the actual targets. Gradient descent does this by iteratively moving along the slope of the loss function (difference between the predicted values and the actual target) to reach the global minima of the function(where the aforementioned difference is minimum)
How does Gradient Descent Work?
Mathematical Representation — The step-by-step update
The math of gradient descent is actually quite simple. Gradient descent iteratively updates the value of a parameter (say θ) by taking a small ‘step’ in the direction of the slope of the loss J(∇J(θ)). The length or the value of this ‘step’ is determined by a hyperparameter called the learning rate (α). The length of the ‘step’ is α times the slope ∇J(θ).
The new value of the parameter becomes the old value minus the length of the step.
θnew=θold−α∇J(θold)
where θ represents parameters, α is the learning rate, and ∇J(θ) is the gradient of the loss function with respect to θ.
Why minus? Mathematically, when you take the gradient of a function, the result points in the direction of the steepest increase. To move in the opposite direction (the steepest decrease), you subtract the gradient.
Analogous Intuition — Climbing down the mountain
The basic intuition of gradient descent can be understood by imagining a person stuck in a mountain on a foggy evening, trying to get down to the valley (the global minima). The visibility is extremely low and the path down the mountain is not visible. They must rely only on the very short distance that they can see. They can use the method of gradient descent by moving in the direction of the steepest slope from the point they are currently at. Taking multiple such steps will lead to the valley (lowest point).

Graphical Contours
Take the example of a contour plot, where each contour level represents a different level of loss. The gradient descent changes the value of θ in the direction of the steepest slope, thereby reaching the middle of the plot in a certain number of steps
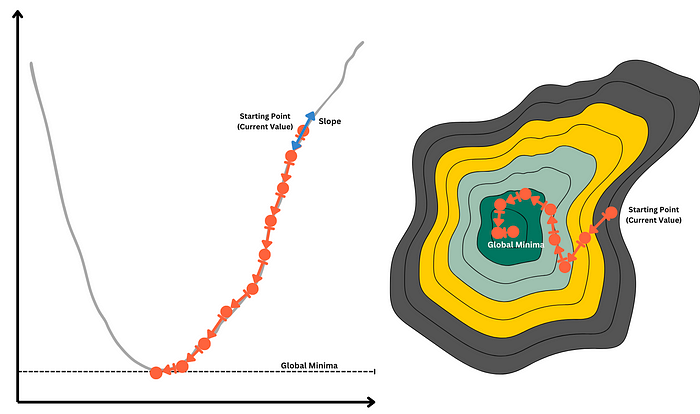
Jump, Leap, or Baby Steps — Learning Rate α
The size of the step for the update of parameter values is, perhaps, the most crucial factor in Gradient Descent. This size is decided by a hyperparameter called the learning rate (represented as α).
Learning rate has become one of the most important hyperparameter in the field of ML research
Choosing the right learning rate is the art of machine learning. If you take the learning rate to be too small, you model will take an extremely long time to converge to the minima.
On the other hand, if the learning rate is too large, you might jump over the minima and reach the other side of the valley.

Thankfully, there are various methods like GridSearch, Learning Rate Scheduling, Cyclic learning rates, Adaptive Algorithms, etc., that are helpful in optimizing for the right learning rates.
Global vs Local
We’ve been talking about global minima. However, not all loss functions are simple convex functions with only one minima. Taking the analogy of mountainous terrain, there can be various irregular features like holes, plateaus, ridges, etc. If the function encounters a “hole”, it might falsely believe it to be the minimum value. On the other hand, if it encounters a long plateau, the function might endlessly take small steps along the plateau and never arrive at a minima.

Thankfully, again, these challenges are not encountered a lot in practice (which is pleasantly surprising) and functions like the mean squared error are convex by nature which plays to the advantage of gradient descent.
Three types of Gradient Descents
The primary computation for the implementation of gradient descent is the calculation of the gradient of the loss function (a partial derivative of the loss with respect to the parameter θ).
There are three variations of this calculation with respect to the number of training observations.
Batch Gradient Descent
This approach considers the entire training data (all observations) to compute the gradient. The model parameters are then updated taking the average of the gradient across data points.
It’s simple, stable and guarantees convergence. However, it’s computationally expensive and memory intensive (imagining storing all the data in memory for the calculation)
Stochastic Gradient Descent
In this approach, the algorithm chooses a single observation, at random, for the calculation of gradient at each step. The parameter values are then updated based on the gradient.
This approach is fast, especially on large datasets. However, as we’d expect, there’s a lot of variance in parameter update and convergence.
Mini-Batch Gradient Descent
This approach is a balance between BGD and SGD. In this approach, instead of taking the entire training data, a small subset (a mini-batch) is randomly selected.
It’s the best of both BGD and SGD. It also works well for parallel computation, making it highly efficient for large datasets. There’s still some variability and the size of the mini-batch needs to be tuned.
from tensorflow.keras.optimizers import SGD
sgd_optimizer = SGD(learning_rate=0.01)
The Optimization of the Deep Networks
Training deep-learning neural networks is a slow process. There are multiple calculations, and optimization needs to be done at every level. Initialization of the weights, the right activation function, normalization, and transfer learning are approaches to speed up the training process.
Who will cry when ReLUs die? : Exploring the World of ReLU Variants
If you’re familiar with Neural Networks and Artificial Intelligence, Activation Functions is a term you must have come…
ai.gopubby.com
Gradient descent is a computationally intensive algorithm. Using an optimizer to accelerate the updation of the parameter value results in a huge boost to the training speed.
Momentum: A little push in the right direction!
The idea of Momentum Optimization is to accumulate velocity during the descent. In regular Gradient Descent, the length of the step only depends on the gradient or the slope at that particular point. It does not consider how the slope was at the previous step.
It’s like a ball rolling down a slope, gaining speed as it rolls down
Momentum Optimization introduces a moment vector ‘m’ and subtracts the slope x learning rate (α∇J(θ)) from it, at every step.
m= βm— α∇J(θ)
The parameter is θ then updated by adding the momentum vector
θ= θ + m
A hyperparameter ‘β’ (also called momentum) controls velocity and takes a value between 0 and 1.
There are two advantages of using the momentum optimizer –
- It increases the speed of convergence
- In some cases, it can also help in overcoming the local minima

One typical drawback of the Momentum Optimizer is that the algorithm tends to oscillate at the minima (like a ball rolling down a v shaped valley) before stopping at the minima.
from tensorflow.keras.optimizers import SGD
optimizer=SGD(lr=0.001, momentum=0.9)
Nesterov Accelerated Gradient: Small Change for Big Gain
A simple modification to Moment Optimizer, introduced by Yurii Nesterov in 1983, almost guarantees even more speed. The only difference in the Nesterov Accelerated Gradient (NAG) is that instead of using the partial differential of loss with respect to θ (∇J(θ)) it uses the partial differential of the entire momentum vector (∇J(θ+βm))
m= βm — α∇J(θ+βm)
θ= θ + m
The addition of this small term helps always point the update closer to the optima. This helps in two ways —
- It increases the speed of convergence
- It reduces the oscillations around the optima
from tensorflow.keras.optimizers import SGD
optimizer=SGD(lr=0.001, momentum=0.9, nesterov=True)
The curse of the elongated valleys: In cases where the scale of the model features is different, the loss function has an elongated valley. In such cases, the model convergence slows down. This is because the steepest slope does not point directly towards the optima.
AdaGrad: Adapt to Speed Up
AdaGrad algorithm solves the problem of the elongated valleys by pointing the update step slightly towards the global minima. It achieves this by scaling down the gradient along the steepest dimension.
It first accumulates the square of the gradients
s = s + square (∇J(θ) or s = s + ∇J(θ) ⦻ ∇J(θ)
⦻ indicates element-wise multiplication
In the update step, the gradient is scaled down (element-wise division) by a factor of √(s+ε) (ε is a smoothening term)
θ=θ-α∇J(θ) divided by √(s+ε)
division here is element-wise
In a way, the algorithm decays the learning rate — faster for steep slopes and slower for gentle slopes. Therefore, it helps point the results towards the global minima.
This decaying learning rate is called the Adaptive Learning Rate
AdaGrad is suitable for simple problems like regression but stops too early for neural networks because the learning rate gets scaled down.
from tensorflow.keras.optimizers import Adagrad
optimizer=Adagrad(learning_rate=0.01)
RMSProp: Every descent is a smooth ride
To solve the problems of AdaGrad (i.e. scaling down of learning rate resulting in slower convergence), RMSProp modifies the algorithm by accumulating gradients only from the recent iterations. It does so by introducing a hyperparameter ρ, which introduces exponential decay
s = ρ*s + (1-ρ)∇J(θ) ⦻ ∇J(θ)
⦻ indicates element-wise multiplication
The second step remains the same
θ=θ-α∇J(θ) divided by √(s+ε)
division here is element-wise
from tensorflow.keras.optimizers import RMSprop
optimizer=RMSprop(learning_rate=0.01)
Adam: The One To Rule Them All
Adam or Adaptive Moment Estimation combines the best of the worlds of Momentum Optimizer and RMSProp. It keeps track of the exponentially decaying average of past gradients and the exponentially decaying average of past squared gradients.
m=β*m — (1-β)∇J(θ)
s = ρ*s + (1-ρ)∇J(θ) ⦻ ∇J(θ)
m*=m/(1-β)
s*=s/(1-ρ)
θ=θ+α*m divided by √(s+ε)
division here is element-wise
Adam has become the choice of optimizer since it outperforms all momentum and adaptive optimizers
Adam has another variant which is quite powerful. It’s called Nadam. Nadam is Adam plus the Nesterov trick (∇J(θ+βm) instead of ∇J(θ)). Nadam generally outperforms Adam.
Adaptive methods generally converge faster to a good solution. However, sometimes you can also achieve faster results with a simpler NAG or SGD with momentum.
from tensorflow.keras.optimizers import Adam, Nadam
adam_optimizer=Adam(learning_rate=0.01)
nadam_optimizer=Nadam(learning_rate=0.01)
The world of optimizers is an area of active research. So far, only the first-order derivatives (or Jacobians) are applied for optimizations. The second-order derivatives (or Hessians) are computationally prohibitively expensive and slow. The choice of optimizers can vary depending on the use case and, more so, on training data. However, there are some indications that Adaptive optimizers perform better for large datasets and deep networks.
If you’re someone who follows Machine Learning, Data Science, Generative AI, and Large Language Models, let’s connect on LinkedIn — https://www.linkedin.com/in/abhinav-kimothi/
Also, please read a free copy of my notes on Large Language Models —
Generative AI with Large Language Models (Coursera Course Notes)
Generative AI with LLMs The world of Language Model-based AI has captured the imagination of all tech enthusiasts and…
abhinavkimothi.gumroad.com
Connect with me to read what I publish — https://medium.com/@abhinavkimothi
Here are a few of my popular blogs —
Getting the Most from LLMs: Building a Knowledge Brain for Retrieval Augmented Generation
The advancements in the LLM space have been mind-boggling. However, when it comes to using LLMs in real scenarios, we…
medium.com
Evaluation of RAG Pipelines for more reliable LLM applications
Building a PoC RAG pipeline is not overtly complex. LangChain and LlamaIndex have made it quite simple. Developing…
medium.com
RAG Value Chain: Retrieval Strategies in Information Augmentation for Large Language Models
Perhaps, the most critical step in the entire RAG value chain is searching and retrieving the relevant pieces of…
medium.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")