



Behind the glory: the dark sides of AI models that big tech will not tell you.
Last Updated on February 13, 2023 by Editorial Team
Author(s): Lan Chu
Originally published on Towards AI.
Behind the Glory: The Dark Sides of AI Models That Big Tech Will Not Tell You
Let’s take the journey to become less ignorant
With ChatGPT blowing the internet, we are at a critical juncture that demands us to again ask hard questions about the impact of AI models on society, a conversation that starts but never ends. In this article, I aim to bring attention to the importance of knowing that, even though large AI models are impressive, there are often unacknowledged costs behind them. It is like saying “ data is the new oil” to describe its value, but this analogy often ignores the costs of the oil and mining industries.
AI and Climate change
Mining for AI: Natural Resource Extraction
To understand what AI is made from, we need to leave Silicon Valley and go to the place where the stuff for the AI industry is made. The term “artificial intelligence” may evoke the ideas of algorithms and data, but it is powered by the rare earth’s minerals and resources that make up the computing components [1]. The cloud, which consists of vast machines, is arguably the backbone of the AI industry. And it is built from resources like rocks, lithium brine, and crude oil. It converts water and electricity into computing power.
Image generated by OpenAI’s Dall-E 2. The prompt was: The lithium mines in Nevada where the materials are extracted to make vast machines in the printing style
From the lithium mines in Nevada to the extraction of “gray gold” (white lithium crystal) in San Francisco — once a hub for gold mining, the AI industry relies on extracting minerals from the earth’s crust. Building natural language processing and computer vision models that run on the computational infrastructures of Amazon Web Services or Microsoft’s Azure is energy-intensive.
The Myth of Clean Tech: Cloud Data Centers
The data center has been a critical component of improvements in computing. These centers, being among the largest energy consumers globally [3], require water and electricity from sources such as coal, gas, nuclear or renewable energy to power their vast computers. China’s data center industry gets 73% of its power from coal, emitting roughly 99 million tons of CO2 in 2018 [4]. In the Netherlands, for example, Microsoft’s second data center in Middenmeer was reported to have used 84 million liters of water, higher than the expected 12–20 million liters [5], during a time of severe drought in the country.
 Photo by Karsten Würth on Unsplash
Photo by Karsten Würth on Unsplash
Addressing water-intensive and energy-intensive infrastructure is a major issue. Certainly, the industry has made significant efforts to make data centers more energy efficient and to increase the use of renewable energy. Some corporations, such as Apple and Google, are responding to concerns about the energy consumption of large-scale computation by claiming to be carbon neutral — which obviously means they offset their carbon emissions by purchasing carbon credits [1].
Microsoft supported the use of renewable energy at its data center in Dublin by using lithium batteries, which provide backup power for the data center in case the demand exceeds the power supply generated by the wind turbines [6]. However, this is far from a perfect solution to carbon dioxide emissions. The mining, production, and transport of the lithium battery itself have a negative impact on the environment, not to mention, lithium batteries have a limited lifespan; once degraded, they are discarded as waste [1].
The Carbon Footprint of AI
AI industry has a meaningful carbon footprint. As estimated, the total greenhouse gas emission of the world’s computational infrastructure has matched that of the aviation industry at its height, and it is increasing at a faster rate [7].
In 2018, OpenAI released an analysis showing that since 2012, the amount of computing used in the largest AI training runs has been increasing exponentially, with a doubling time of 3–4 months [8]. This represents an increase by a factor of 10 each year, mainly due to researchers building hundreds of versions of a given model by experimenting with different neural architectures and hyperparameters to find the optimal design and repeatedly finding ways to use more chips in parallel [8].
The carbon footprint of the world’s computational infrastructure has matched that of the aviation industry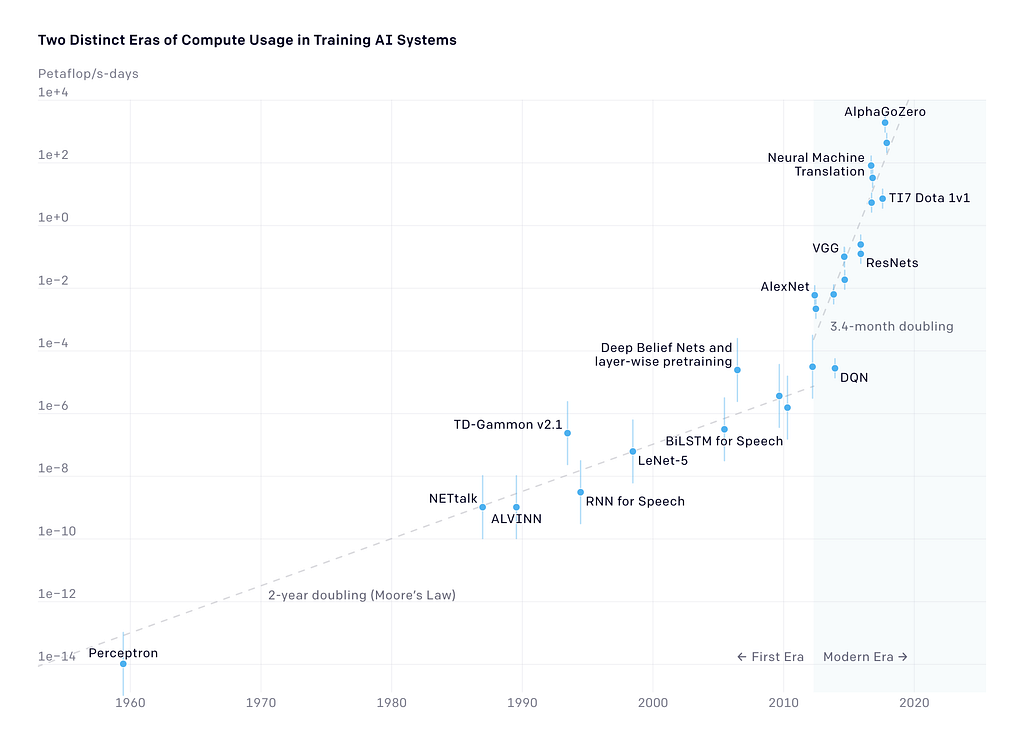 The total amount of compute, in petaflop/s-days, used to train selected results that are relatively well known, with a doubling time of 3–4 months since 2012. By comparison, Moore’s Law had a 2-year doubling period. Source: openAI [8]
The total amount of compute, in petaflop/s-days, used to train selected results that are relatively well known, with a doubling time of 3–4 months since 2012. By comparison, Moore’s Law had a 2-year doubling period. Source: openAI [8]
In a study published in 2019, Emma Strubell and her team at the University of Massachusetts Amherst conducted research on the carbon footprint of NLP models. They sketch out potential estimates by running AI models over hundreds of thousands of computational hours. While the average human is responsible for an estimated 5 tons of Co2e per year, Strubell’s team estimated that training a single deep learning model can generate up to 284 tons of Co2 emissions — roughly equal to the total lifetime carbon footprint of five cars [9].
It is easy to put a price on metals and computers, but how can we estimate the price of clean water and breathable air?
The Cost of Larger Models: Diminishing Returns
Diminishing return is a growing concern in the AI industry, as stated in the 2019 paper from the Allen Institute. The study provides detailed data documenting the diminishing returns of image recognition models since the pace of model growth, and training size far exceeds the increase in model performance.
For instance, in the figure below (on the right), an improved version of the Resnet152 (60.2M parameters), known as ResNeXt(83.5M parameters), requires an increase of roughly 35% in computational resources (measured by total floating-point operations — FPO ) to achieve only a 0.5% accuracy improvement [10].
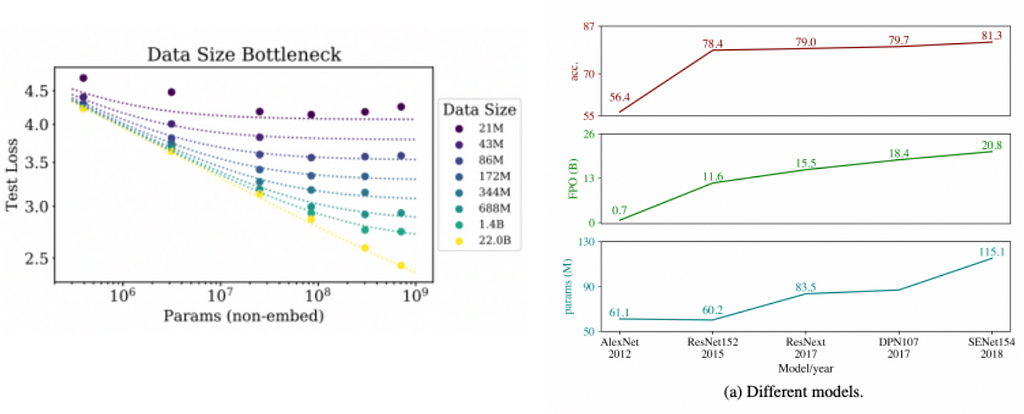 Left: For large models, performance is a straight power law. For smaller models, performance stops improving as the size of the data increases. Source: [24] Right: An increase in FPO results in a diminishing return for object detection model accuracy. Plots (bottom to top): model parameters (in million), FPO (in billions), accuracy on ImageNet. Source: [9]
Left: For large models, performance is a straight power law. For smaller models, performance stops improving as the size of the data increases. Source: [24] Right: An increase in FPO results in a diminishing return for object detection model accuracy. Plots (bottom to top): model parameters (in million), FPO (in billions), accuracy on ImageNet. Source: [9]
In 2020 researchers at OpenAI [24] published a paper where they investigated how the performance of large transformer and LSTM models scale as a function of model size (number of parameters) and training dataset size (number of tokens). As shown in the above figure (on the left), the model performance can be saturated both by the size of the training dataset and by the size of the model.
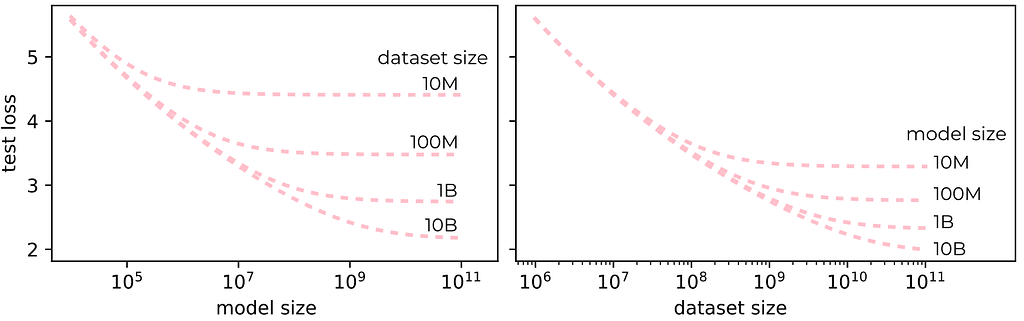 Test loss follows simple power-law behavior as a function of both model and training dataset size. Source: image by the author using data from [24].
Test loss follows simple power-law behavior as a function of both model and training dataset size. Source: image by the author using data from [24].
It seems that currently, the investment in more resources, e.g., training data and computation, still pays off in terms of downstream performance, although at an increasingly lower rate [9]. However, the AI industry’s desire to build much larger models for incremental performance improvements may come at a high cost to the planet. Finding the saturation point is an important question to be looked into.
The Hidden Costs of AI: Labor, Wage and Psychological Impact
The Human-fueled AI
The story of AI is a story about labor. Large language models like ChatGPT are impressive, but they are not magic — they rely on massive human labor, which often goes unacknowledged. This unseen labor helps build, maintain, and test AI systems and takes many forms, from the mining sector, where resources are extracted to create the core infrastructure of AI systems, to the software side, where labor is needed to manually label training data and review toxic content.
Setting the Low Rate for Crowworkers
Workers do repetitive tasks such as labeling data or reviewing contents that are essential to sustaining AI systems but rarely receive credit for making the systems work and are even poorly compensated in some places[1]. A study from the United Nations International Labour Organization surveyed 3,500 crowd workers from 75 countries who offered their labor on popular task platforms like Amazon Mechanical Turk, Figure Eight and Microworkers. The report found that a substantial number of people earned below their local minimum wage even though the majority of respondents were highly educated [11].
 Image generated by OpenAI’s Dall-E 2. The prompt was: African workers at desks in front of computer screens to label data in a printmaking style.
Image generated by OpenAI’s Dall-E 2. The prompt was: African workers at desks in front of computer screens to label data in a printmaking style.
Psychological Impact of Content Moderation and Labelling Data
Those who do content moderation and labeling work, such as assessing violent videos and hate speech, can suffer from lasting forms of psychological trauma [12]. The internet contains a significant amount of toxic content such as child sexual abuse, murder, torture, self-harm, etc. This makes it difficult to purify the training data. Even a team of hundreds of people would have taken years to go through the giant datasets and label them manually. Hence the development of an AI-powered safety mechanism that can detect toxic language is crucial in removing harmful data and making AI tools safer [13].
Take chatGPT as an example. In order to train AI to recognize and remove toxic content, a labeled database of toxic content is required. These labeled examples are used to train an AI tool to detect those forms of toxicity. That detector will be built into ChatGPT to check whether the toxic text is included in its training data and filter it out before it reaches the users.
To get labeled data, OpenAI outsourced the labeling to Sama — a San Francisco-based firm that employs workers in Kenya to label data for Silicon Valley clients like Google and Meta. However, the process of labeling such data was emotionally draining for Sama’s employees, who had to handle disturbing text and images on a daily basis. One worker reported suffering from recurring nightmares after reading a graphic description of sexual abuse involving a child and an animal [13]. Due to the traumatic nature of the work, Sama ultimately ended its contract with OpenAI eight months earlier than planned in February 2022 [13].
Data in AI: Bias, unfair algorithms and privacy concerns
Those who own the data own the future
It can’t be denied that data has become a driving force in the success of AI. Back in those days, data was remarkably hard to find. You couldn’t even get a million words in computer-readable text easily. The internet, however, changed everything. As more people began to write online and upload photos to social media platforms, the digital era has created large-scale labeled data. Suddenly, training sets could reach a size that we could never have imagined. As an example, on an average day in 2019, approximately 350 million photographs were uploaded to Facebook, and 500 million tweets were sent [14].
This abundance of data has put tech giants in a powerful position — as they have access to a never-ending pipeline of images and texts that can be used to train AI models. This has been made easier by people happily labeling their photos with names and locations, resulting in more accurate, labeled data for computer vision and language models.
Yet, this also raised ethical concerns that start but never end.
Bias in Data
Let’s discuss the elephant in the room: AI safety aims to align AI systems with human values. However, research has shown that large AI models have various forms of bias, such as stereotypical associations or negative sentiments toward specific groups [15]. This is largely due to the characteristics of the training data.
Because the size does not guarantee the diversity
The Internet is vast and diverse, and accordingly, it is easy to think that very large datasets, such as Common Crawl, which includes petabytes of data collected over 8 years of web crawling, must therefore be a good representative of the ways different people view the world.
However, let us start with who is contributing to the texts on the Internet. The access to the internet itself is not evenly distributed, resulting in Internet data overrepresenting younger users and those from developed countries [15]. Furthermore, the data sources for large language models, such as Reddit and Wikipedia don’t represent the views of the general population. For instance, GPT-2’s training data is sourced by scraping data from Reddit, and Pew Internet Research’s 2016 survey reveals that 67% of Reddit users in the United States are men, and 64% are between the ages of 18 and 29 [15].
AI bias comes from humans.
Training data reflects existing human worldviews and social bias because the language we produce reflects our own biases. A human knows and agrees that it is unethical to discriminate against black people and women, but then, when a black woman applies for a job, the human subconsciously discriminates against her and decides not to hire her. Similarly, research has shown that language models like BERT and GPT-3 associate phrases related to disabilities with negative sentiment and overrepresent topics like gun violence, homelessness, and drug addiction in texts discussing mental illness due to the characteristics in its training data [16,17].
AI technology is an echo of our own bias.
Listen to the algorithms — AI bias is the real killer
The use of biased data can lead to unfair algorithms. A case exhibiting this was the Dutch childcare benefits scandal that led to the resignation of the Dutch government in 2021. The Dutch tax authority used a classification algorithm to detect fraudulent behaviors. This algorithm used an imbalanced data set because most of the observations were parents with an immigration background. Second, the model used the Dutch/non-Dutch nationality indicator as a predictor for the fraudulent risk model [18], resulting in the model negatively discriminating against people with non-Dutch nationality and wrongfully accusing 26000 parents of fraud [19].
In another example, a group of researchers developed an automatic system for classifying crimes using a crime dataset from the Los Angeles Police Department that includes thousands of crimes labeled by police as gang-related [1]. These researchers used a neural network that employs only four pieces of information, including weapons, suspects, neighborhood, and location, to predict gang-related violence. However, the police database is heavily skewed because not every crime is recorded. For instance, crimes that are more likely to be recorded are those areas heavily patrolled by police. Therefore, locations that are often checked by the police are over-represented in the data, leading to machine learning predictions that amplify existing bias.
Project Maven, funded by the Pentagon, aims to build AI war machines that comb through drone footage and detect objects such as vehicles and humans as they move between locations [1]. This raises a fundamental ethical question surrounding the use of AI in warfare. Lucy Suchman argues that the problems with AI in warfare go far beyond whether the “killing was correct”. Questions such as who built the training sets and which data was used, how objects are labeled as a threat, and what kinds of activities trigger a drone attack are crucial. Attaching life-or-death issues to potentially unstable and political algorithms is a risky gamble. In 2021, a US drone strike in Afghanistan wrongly killed 10 civilians who were originally believed to be associated with Islamic State. The Pentagon acknowledges the drone strike was a “tragic mistake”, blaming the confirmation bias [20]. Imagine you are a soldier fighting in the war or just a normal individual who wrongfully got killed by your country’s drones due to the mistake of AI. How terrifying that sounds.
The Drama of Privacy
The collection of people’s data to build AI systems raises clear privacy concerns. A noteworthy instance is a partnership between the Royal Free National Health Service Foundation Trust in Britain and Google’s subsidiary DeepMind, where the trust agreed to share the health records of 1.6 million patients. But when the agreement with DeepMind was investigated, the company was found to have violated data protection laws by not sufficiently informing patients [22]. The advancement of technology should not come at the cost of compromising fundamental privacy rights.
The End of Consent
The AI industry marks a shift away from consent-driven data collection. Those responsible for collecting the data believe that the internet’s contents were theirs for the taking. Neither the people in the photos nor those who write the texts have a say in how the data they create is used.
For example, a professor at the University of Colorado was reported to have installed a camera on the main walkway of the campus and secretly captured photos of more than 1700 students to train his own facial recognition algorithm for government-backed research [23].
Another example is Microsoft’s dataset MS-Celeb, which scraped roughly 10 million photos of 100,000 humans from the internet in 2016. At the time, the dataset was described as the largest publicly available facial dataset in the world. Microsoft later took down the data set after a report from the FTs found that many of the people represented in the dataset were not aware of it and did not consent to have their photos used [24].
The success of AI relies on getting ever-larger datasets, but why would we accept this practice, despite the foundational problem like data privacy and consent?
Conclusion
In this article, I discussed a few hidden costs and consequences related to the use of large AI models. Firstly, the environmental impact is significant due to the high consumption of energy and water to power AI systems.
Secondly, there is the issue of human labor involved in the development and maintenance of AI systems. Despite being crucial to the functioning of AI systems, crowd workers are often underpaid and may suffer from lasting psychological trauma. This highlights the need for better compensation and support for these workers.
Finally, there are ethical concerns surrounding the abundance of data created in the digital era, which AI relies on to function. Unfair algorithms and violation of privacy are examples that need to be addressed to ensure the fair use of AI technology.
Join the Medium membership program to continue learning without limits. I’ll receive a portion of your membership fee if you use the following link at no extra cost to you. If you decide to do so, thanks a lot!
Join Medium with my referral link – Lan Chu
Bibliography
[1] Crawford, K. (2021). The atlas of AI: Power, politics, and the planetary costs of artificial intelligence. Yale University Press.
[2] Hu, Tung-Hui. A Prehistory of the Cloud. MIT press, 2015.
[3] Cook, Gary, David Pomerantz, Kassie Rohrbach, Brian Johnson, and J. Smyth. “Clicking clean: A guide to building the green Internet.” Greenpeace Inc., Washington, DC (2015).
[4 ] Datacenter Microsoft Wieringermeer slurpte vorig jaar 84 miljoen liter drinkwater. https://www.noordhollandsdagblad.nl/cnt/dmf20220810_68483787
[5] Microsoft datacenter batteries to support growth of renewables on the power grid. https://news.microsoft.com/source/features/sustainability/ireland-wind-farm-datacenter-ups/
[6] Cloud sustainability. https://cloud.google.com/sustainability/
[7] Masanet, E. (2018). How to stop data centres from gobbling up the worlds electricity (vol 561, pg 163, 2018). Nature, 561(7722).
[8] AI and Compute. https://openai.com/blog/ai-and-compute/
[9] Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. arXiv preprint arXiv:1906.02243.
[10] Schwartz, R., Dodge, J., Smith, N. A., & Etzioni, O. (2020). Green ai. Communications of the ACM, 63(12), 54–63.
[11] Berg, Janine, Marianne Furrer, Ellie Harmon, Uma Rani, and M. Six Silberman. “Digital labour platforms and the future of work.” Towards Decent Work in the Online World. Rapport de l’OIT (2018).
[12] Gillespie, Tarleton. Custodians of the Internet: Platforms, content moderation, and the hidden decisions that shape social media. Yale University Press, 2018.
[13] Exclusive: OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic. https://time.com/6247678/openai-chatgpt-kenya-workers
[14] “Facebook by the Numbers (2019)”; and “Advertising on Twitter.”
[15] Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?🦜. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency (pp. 610–623). https://dl.acm.org/doi/pdf/10.1145/3442188.3445922
[16] Gehman, S., Gururangan, S., Sap, M., Choi, Y., & Smith, N. A. (2020). Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462. https://doi.org/10.18653/v1/2020.findings-emnlp.301
[17] Hutchinson, B., Prabhakaran, V., Denton, E., Webster, K., Zhong, Y., & Denuyl, S. (2020). Social biases in NLP models as barriers for persons with disabilities. arXiv preprint arXiv:2005.00813. https://doi.org/10.18653/v1/2020.acl-main.487
[18] The dutch benefits scandal: a cautionary tale for algorithmic enforcement. EU Law Enforcement. https://eulawenforcement.com/?p=7941
[19] Belastingdienst werkte ouders die recht hadden op kinderopvangtoeslag bewust tegen. https://www.trouw.nl/nieuws/belastingdienst-werkte-ouders-die-recht-hadden-op-kinderopvangtoeslag-bewust-tegen~bf13daf9/#:~:text=De%20Belastingdienst%20heeft%20bewust%20aangestuurd,kort%20ontkend%20door%20de%20Belastingdienst.
[20] Pentagon acknowledges Aug. 29 drone strike in Afghanistan was a tragic mistake that killed 10 civilians. https://www.nytimes.com/2021/09/17/us/politics/pentagon-drone-strike-afghanistan.html
[21] Bergen, M. (2018). Pentagon Drone Program Is Using Google AI
[22] Revell, T. (2017). Google DeepMind’s NHS data deal ‘failed to comply’with law. New Scientist.
[23] Hernandez, E., & Ehern, E. (2019). CU Colorado Springs students secretly photographed for government-backed facial-recognition research. The Denver Post.
[24] Microsoft quietly deletes largest public face recognition data set. https://www.ft.com/content/7d3e0d6a-87a0-11e9-a028-86cea8523dc2
[25] Kaplan, Jared, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).
Behind the glory: the dark sides of AI models that big tech will not tell you. was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

