



A Beginner’s Guide To Twitter Premium Search API
Last Updated on January 6, 2023 by Editorial Team
Author(s): Eugenia Anello
Programming
How to use Python and Twitter API to create your own Twitter dataset
Social networks are constantly part of our life nowadays. Their popularity can be explained by accessibility and convenience, which allow users to provide huge amounts of information with limited or no restrictions on content. This continuous and rich mass of data is made available by these platforms with the purpose of studying sentiments about brands, products, events, recent news, social and political issues.
In this covid-19 period, there has been a dramatic growth on these platforms. In Twitter, there has been an increased use of the platform for misinformation related to the pandemic. For this reason, I am going to collect tweets from the last seven days that mention Corona Virus and Giuseppe Conte, that is the Prime Minister in Italy. My objective is to explain step by step how to extract data using Twitter API.
Twitter API
Twitter API provides access to a variety of different resources: tweets, users, direct messages, lists, trends, media, places. In this case, we are only focusing on tweets. This API currently consists of 2 supported versions, v1.1 and v2, which is still in development [1]. So we are focusing on version v1.1. Moreover, the v1.1 version offers different tiers: Standard, Premium and Enterprise. The Standard version is a free solution, but it’s limited. It returns only tweets published in the last 7 days and has a rate limit of 450 requests per time window. Then, we are interested in the Premium version, that offers a Paid Premium access that provides increased access and free SandBox access with a lower set of limits and capabilities than Premium access. In particular, there are two types of SandBox:
- 30-day provides Tweets from the previous 30 days.
- Full-archive provides complete and instant access to Tweets dating all the way back to the first Tweet in March 2006.
Below there is the table that summaries the differences between SandBox and Premium tiers.

In this article, I will use the Full Archive SandBox because it’s free and allows to download data older than one month.
Step 1: Apply for a developer account
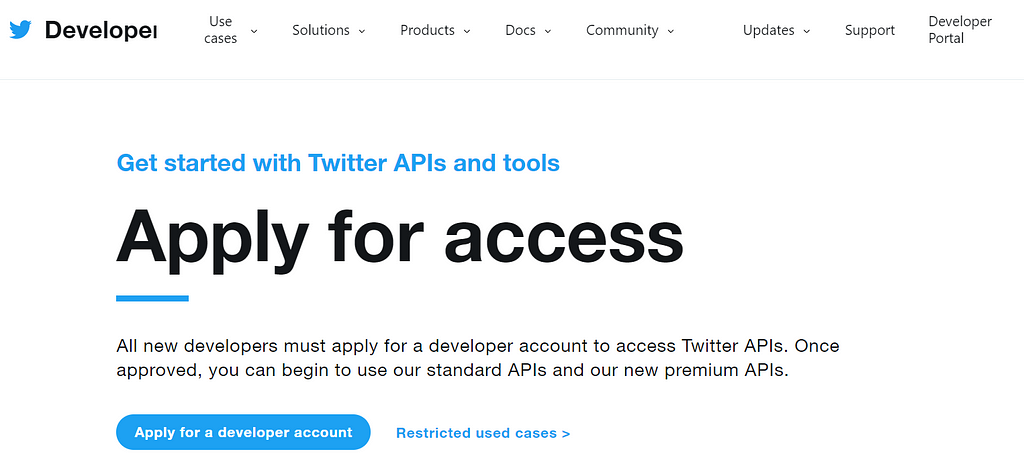
Before downloading the tweets, you must first apply for a developer account, that needs to be approved. When applying, you will need to submit information about your intended use of Twitter APIs in a specific form. After you finish to compile the form, you’ll receive the emails with additional questions from Twitter’s team. I warn you that it will take time to create the Developer account, on average between 1 week and 2 weeks.
Step 2: Create your Twitter project and App
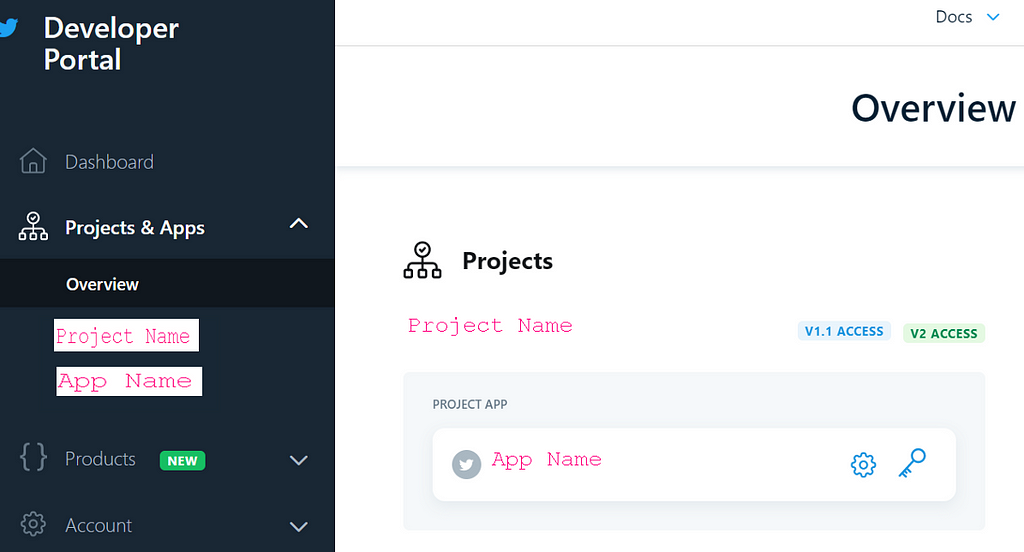
Once approved, you can create a Project and connect an associated developer App, which will provide a set of credentials that you will use to authenticate all requests to the API. To begin using your API, you need to set up the dev environment for the endpoint. What is the endpoint? The endpoint is a GET connection authenticated using a bearer token. Once a connection is established, Tweets are delivered in JSON format through a persistent HTTP Streaming connection. In this tutorial I choose the Full Archive
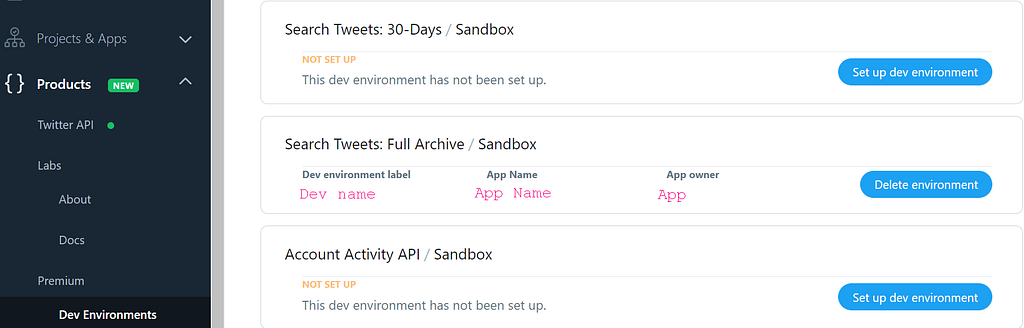
Once you finished the set-up of the environment, you need to save only your App’s Bearer token, that will be used later to download the tweets.

Step 3: Create the file twitter_keys.yaml
To write and run the Python code, I suggest to use Google colab, a tool released by Google. It provides a free Jupiter notebook environment with pre-installed packages such as pandas, numpy, keras and hosts entirely on Google Cloud. Moreover, it saves automatically the notebooks on the user’s Google Drive, making possible to share the files easily with other people. Moreover, if offers free GPU and TPU!
Before writing Python code, we need to create a file, called twitter_keys.yaml. It’s useful to keep all the credentials in separate file, instead of having them in the code. Paste and edit the following lines:
There are few things to remember:
- When you past these lines, check if there are the two indentations after the first row, otherwise the code won’t work!
- The account type can be premium or enterprise. In this case, I’m focusing on Premium setup.
- In the file, you need only to substitute your dev environment name with env_name in the link https://api.twitter.com/1.1/tweets/search/fullarchive/env_name.json. To find the name of the dev environment, you must relook you dev set-up again.
- Specify your bearer token.
We don’t need to specify consumer key and consumer secrete, the credentials inserted until now are enough to download the tweets.
Step 4: Write Python code
Let’s install the library we’ll use in this tutorial.
searchtweets is a Python library, that serves as a wrapper for the Twitter premium and enterprise search APIs [2].
After we can import the libraries:
Once imported the libraries, we load the credentials of the file:
gen_rule_payload is a function that formats search API rules into valid json queries. So, it generates the rules, that match tweets with hashtags #covid19 and #giuseppeconte and select the Italian language. It has sensitive defaults, such as pulling more Tweets per call than the default 100.
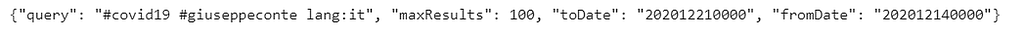
Now we create the ResultStream object, that takes as input the rules and other configuration parameters, including a hard stop on the number of pages to limit the API call usage.

The function stream handles requests and pagination for a given query. It returns a generator. To grab our 500 Tweets that mention the words specified in the rules, we can do this:
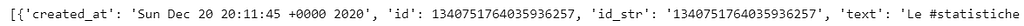
Below there are the fields accessible through Tweet Parser Tweet module.

Finally, we preprocess the data and we create the DataFrame.

In end, we save the DataFrame into a CSV file.
Congratulations! You extracted the tweets from Twitter. The creation of Developer account is the step that takes more time than the others, but after you have done it, it’s all uphill. I hope that this tutorial helped you. The entire code is on GitHub. I also suggest you to try the other SandBox, 30-days, if you only need to download the tweets of the last month. In order to do it, you need to change the endpoint field in the file. In the second link of the references, you can find all the informations about the python library searchtweets.
References:
[1] https://developer.twitter.com/en/docs
[2] https://github.com/twitterdev/search-tweets-python
A Beginner’s Guide To Twitter Premium Search API was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.




Recent Posts





")
