



Technical Post-Mortem of a Data Migration Event
Last Updated on June 11, 2024 by Editorial Team
Author(s): Vishnu Regimon Nair
Originally published on Towards AI.
In this data-driven landscape, extracting the maximum value from data is crucial for success. As data volumes grow exponentially, organizations face considerable pressure to optimize their data storage and accessibility strategies.
Data models are the fundamental building blocks of data systems. As applications evolve and become more complex, engineering teams often face the inevitable need to redesign and refactor these models. This need would compel companies to migrate data to more powerful and efficient systems to take advantage of improved operational performance and features.
Data migrations are complex technical projects that require careful planning, execution, and monitoring. Even with the best preparations, things can still go wrong. Any financial loss to the organization is unacceptable, and user experience degradation is highly frowned upon. This post analyzes a recent data migration event I was involved with and the critical lessons learned from it.
TL;DR
- It is essential to know which tables depend on which sources, configurations, and ETL pipelines. More dependencies mean that a failure of one would cause a failure in production. This will allow us to understand the blast radius in the event of a failure.
- Migrating small batches of production data allowed for comprehensive testing without huge drawbacks. Failures happened faster, which allowed for faster iterations of fixes.
- Tables had many upstream and downstream dependencies that hadn’t been mapped thoroughly before. This interdependency caused delays in figuring out how to move them safely without breaking production.
- Legacy systems can have dependencies that are no longer compatible with current industry standards. Some ETL pipelines depend on outdated dependencies, so we had to maintain multiple versions of different libraries to keep them running. This also happens when older versions continue to be used even though new versions have emerged.
- Sometimes, legacy solutions are so tightly coupled with mission-critical data that the organization is willing to continue with these older versions, even if they miss out on many security features and updates.
- Migrations can become the critical inflection point at which teams examine their past technical debt and push for newer, better upgrades.
Table of Contents
· The most visible pain point
· Migration criteria
· Which tables to prioritize moving?
· Migration Steps
· Unexpected Roadblocks
· What went right
· What went wrong
· Conclusion
The most visible pain point
I noticed a high CPU usage of >90% during peak traffic due to a high number of requests and not enough resources to handle such a heavy load. The high usage is causing increased database latencies and affecting user experiences. Sometimes, there are deadlines for payment and submission of crucial financial information to authorities, which can get delayed if there is too much friction while accessing such information.
I ran a time series analysis of queries that hit our database and analyzed which caused the maximum CPU usage spike. The database traffic analysis showed that a significant portion of the delay came from write operations, especially gathering and updating records from tables having multiple dependencies. So, if a table has multiple source dependencies that have to be updated for the primary table to be updated with complete information, that causes a lot of delay in the client-side response time. This wait becomes longer when the hardware can’t handle new queries due to high incoming traffic. So, the tables that cause the highest strain on the servers are prime candidates for migration.
Migration criteria
The criteria for which tables should be prioritized for migration:
- Business Requirements
a) Identify tables with mission-critical data essential for operations.
b) Identify tables that are most used by users or applications. - Performance Impact
a) Identify tables that take up the most amount of hardware resources
b) Identify tables involved in complex join operations or aggregations that slow down system performance. - Database dependencies
a) Identify tables with significant foreign key relationships
b) Identify tables with dependencies on other tables or data sources
Which tables to prioritize moving?
I ran a time series analysis of queries that hit our database and analyzed which caused the maximum CPU usage spike. The database traffic analysis showed that a significant portion of the delay came from write operations, especially gathering and updating records from tables having multiple dependencies. So, if a table has multiple source dependencies that have to be updated for the primary table to be updated with complete information, that causes a lot of delay in the client-side response time. This wait becomes longer when the hardware can’t handle new queries due to high incoming traffic. So, the tables that cause the highest strain on the servers are prime candidates for migration.
Tables with multiple upstream and downstream dependencies filled with mission-critical data proved to be the hardest to migrate. They have the highest blast radius in case of failure. So, when we are migrating, we have to worry about two different sides of dependencies. One is database dependencies, which are tables or data sources on which the primary table depends. Another is the custom dashboards, third-party reporting tools, and self-service analytics tools that use this table. If the source is changed suddenly without updating these tools, then downstream users will face errors and failures. So, identifying all of the upstream and downstream dependencies of the table being migrated is of significant importance.
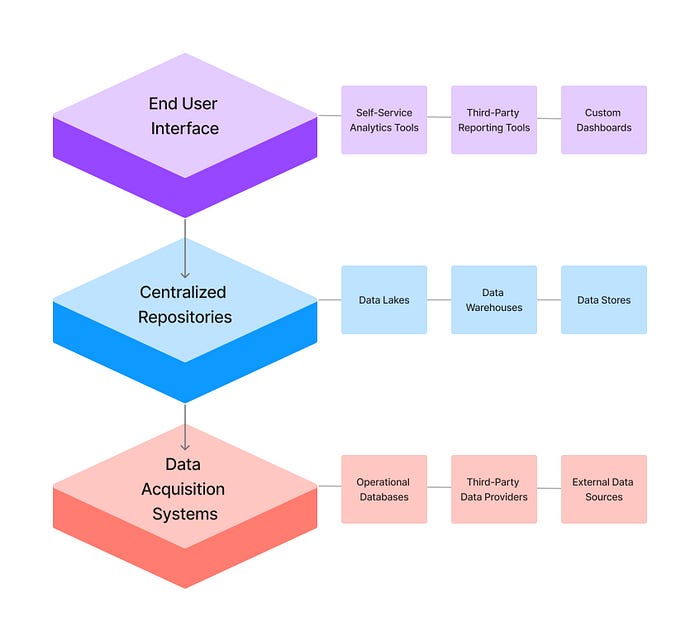
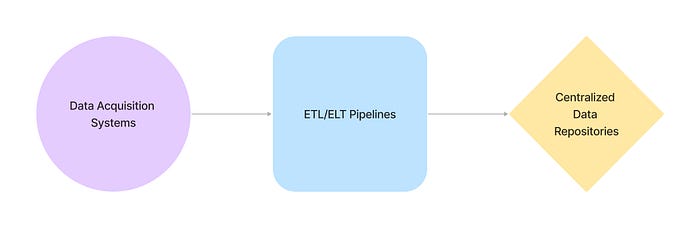
Identifying all the dependencies in a table has proved to be an immense challenge. Generally, ETL pipelines show only the dependencies for that particular source for that particular dataset/datasets. [Data Acquisition Systems -> Centralized Data Repositories] Data models for dashboards like Power BI only have dependencies from the table/combination of tables in the repositories. [Centralized Data Repositories -> End-User Interface] The output from an ELT/ETL pipeline becomes an input for downstream user interfaces, creating an intricate web of interdependencies. There wasn’t a clear mapping connecting Data Acquisition Systems, Centralized Data Repositories, and End-User Interfaces.
Without correctly mapping these dependencies, it becomes challenging to understand the impact of changes made to a particular pipeline or dataset. Modifying a dataset can affect multiple downstream user interfaces, leading to unexpected behavior or data inconsistencies. This challenge showed a need for more visibility and documentation of dependencies between various data pipelines and datasets in a data ecosystem.
I was using the SQL Server Stack for the data systems. The following was used extensively:
- SQL Server Integration Services(SSIS) — Used to transfer data from data acquisition systems to the centralized data repository
- SQL Server + SQL Server Management Studio(SSMS) — The centralized data repository
- SQL Server Agent Jobs — Runs the SSIS Packages(ETL pipelines) in a scheduled way(Helps to set which package to run at what time)
Since no out-of-the-box solution was available, I had to build a custom solution for this challenge. I created Python scripts that captured all the upstream dependencies for tables in ETL/ELT pipelines by extracting the metadata. The Python scripts would iterate through each pipeline, identifying the source and target datasets where the transformed data is loaded. The scripts could map the data lineage and identify dependencies by parsing the metadata. I identified the tables used for the end-user interface by reviewing the data models on which these interfaces rely.
Suppose there are 2 SSIS packages in a directory, as shown below, and they are in the following formats.
E:\SSISOrchestrator\obj\Development\SSIS_folders
│
├── Package1.dtsx
└── SubFolder
└── Package2.dtsx
The SSIS packages are in a ‘.dtsx’ file format with an XML structure. The two package structures are given below:
-- First SSIS package
<Executable xmlns:SQLTask="www.microsoft.com/sqlserver/dts/tasks/sqltask">
<SQLTask:SqlTaskData SQLTask:Connection="Connection1" SQLTask:SqlStatementSource="DELETE FROM [dbo].[Table1] WHERE [Id] = 1" />
<SQLTask:SqlTaskData SQLTask:Connection="Connection2" SQLTask:SqlStatementSource="TRUNCATE TABLE [Schema1].[Table2]" />
</Executable>
-- Second SSIS package
<Executable xmlns:SQLTask="www.microsoft.com/sqlserver/dts/tasks/sqltask">
<SQLTask:SqlTaskData SQLTask:Connection="Connection3" SQLTask:SqlStatementSource="DELETE FROM [dbo].[Table3] WHERE [Name] = 'Test'" />
</Executable>
Therefore, to get the tables and the associated ETL pipelines, we have to open each package XML and connect it to the related tables.
This is the final query output. It has parsed through all the packages in the directory and sub-folders and retrieved the packages with the associated tables.

The SQL Server and SSMS provided information about the SSIS Packages and the SQL Server Agent Jobs that run it. By parsing the data using SQL, I could combine the tables containing SSIS packages and the tables containing SQL Server Agent Jobs.
The SQL query creates a temporary table called ProcessedData with columns for the SSIS package, job name, step name, etc. It selects data from the ‘sysjobsteps’ and ‘sysjobs’ tables. These tables have information about the SQL Server Agent jobs. It has information like which ETL pipelines are running during a particular job. SQL Server Agent Jobs can have multiple ‘steps’ where each step can be an SSIS package(ETL Pipeline). The query collects and stores the distinct SSIS packages updated by the jobs. So, a table is now created with the SSIS packages, the job that runs it, and the step number on which it is run. Finally, the temporary table is dropped.
USE msdb;
-- Create a temporary table to store the results of ProcessedData
CREATE TABLE #ProcessedData (
SQLInstance NVARCHAR(50),
[job] NVARCHAR(128),
Enabled INT,
[step] NVARCHAR(128),
SSIS_Package NVARCHAR(255),
StorageType NVARCHAR(50),
[Server] NVARCHAR(255)
);
-- Insert the data into the temporary table
INSERT INTO #ProcessedData (SQLInstance, [job], Enabled, [step], SSIS_Package, StorageType, [Server])
SELECT
'cgysql1',
j.name,
j.Enabled,
s.step_name,
CASE
WHEN CHARINDEX('/ISSERVER', s.command) = 1 THEN SUBSTRING(s.command, LEN('/ISSERVER "\"') + 1, CHARINDEX('" /SERVER ', s.command) - LEN('/ISSERVER "\"') - 3)
WHEN CHARINDEX('/FILE', s.command) = 1 THEN SUBSTRING(s.command, LEN('/FILE "') + 1, CHARINDEX('.dtsx', s.command) - LEN('/FILE "\"') + 6)
WHEN CHARINDEX('/SQL', s.command) = 1 THEN SUBSTRING(s.command, LEN('/SQL "\"') + 1, CHARINDEX('" /SERVER ', s.command) - LEN('/SQL "\"') - 3)
ELSE s.command
END,
CASE
WHEN CHARINDEX('/ISSERVER', s.command) = 1 THEN 'SSIS Catalog'
WHEN CHARINDEX('/FILE', s.command) = 1 THEN 'File System'
WHEN CHARINDEX('/SQL', s.command) = 1 THEN 'MSDB'
ELSE 'OTHER'
END,
CASE
WHEN CHARINDEX('/ISSERVER', s.command) = 1 THEN REPLACE(REPLACE(SUBSTRING(s.command, CHARINDEX('/SERVER ', s.command) + LEN('/SERVER ') + 1, CHARINDEX(' /', s.command, CHARINDEX('/SERVER ', s.command) + LEN('/SERVER ')) - CHARINDEX('/SERVER ', s.command) - LEN('/SERVER ') - 1), '"\"', ''), '\""', '')
WHEN CHARINDEX('/FILE', s.command) = 1 THEN SUBSTRING(s.command, CHARINDEX('"\\', s.command) + 3, CHARINDEX('\', s.command, CHARINDEX('"\\', s.command) + 3) - CHARINDEX('"\\', s.command) - 3)
WHEN CHARINDEX('/SQL', s.command) = 1 THEN REPLACE(REPLACE(SUBSTRING(s.command, CHARINDEX('/SERVER ', s.command) + LEN('/SERVER ') + 1, CHARINDEX(' /', s.command, CHARINDEX('/SERVER ', s.command) + LEN('/SERVER ')) - CHARINDEX('/SERVER ', s.command) - LEN('/SERVER ') - 1), '"\"', ''), '\""', '')
ELSE 'OTHER'
END
FROM dbo.sysjobsteps s
INNER JOIN dbo.sysjobs j ON s.job_id = j.job_id AND s.subsystem = 'SSIS';
-- Find Distinct SSIS Packages being updated by SQL Server Agent Job along with step name
SELECT
[job] as 'SQL Server Agent Job',
'SSIS Package Name' = REVERSE(SUBSTRING(REVERSE(SSIS_Package), 1, CHARINDEX('\', REVERSE(SSIS_Package)) - 1)),
[step]
FROM #ProcessedData
AND REVERSE(SUBSTRING(REVERSE(SSIS_Package), 1, CHARINDEX('\', REVERSE(SSIS_Package)) - 1)) IN (
SELECT
REVERSE(SUBSTRING(REVERSE(SSIS_Package), 1, CHARINDEX('\', REVERSE(SSIS_Package)) - 1))
FROM #ProcessedData
GROUP BY REVERSE(SUBSTRING(REVERSE(SSIS_Package), 1, CHARINDEX('\', REVERSE(SSIS_Package)) - 1))
HAVING COUNT(DISTINCT [job]) = 1
)
ORDER BY [job], 'SSIS Package Name';
-- Drop the temporary table
DROP TABLE #ProcessedData;

Since I need only a few columns, I will select them and generate the final output.

So, now, I have two lists.
- A list of source datasets and target datasets from the Python scripts.
- A list of target datasets in our centralized repository and the end-user interface from the data models.
Combining these lists using inner join gives me the entire list of tables and their dependencies. This list lets me know what upstream and downstream dependencies to monitor while migrating the tables.
SELECT
j.JobName AS 'SQL Server Agent Job',
j.StepName AS 'Step Name',
j.PackageName AS 'Package Name',
p.TableName AS 'Table Name'
FROM
SQL_Jobs j
INNER JOIN
SSIS_Packages p ON j.PackageName = p.PackageName
ORDER BY
j.JobName, j.StepName;

Migration Steps
- Replicate the ETL/ELT pipelines that loaded into the original data repository and change the target to the new target system. Thus, new data will now be coming into both repositories. The latest data is small enough to be used as test data compared to the table’s historical records.
- Once the testing with new data is complete, transfer over the historical records of respective tables. Now, identical replicas of the repositories are created.
- Test the new repository in production and observe any variations from the old repository. Then, use the new repository to recreate the data models for end-user interfaces. Test the end-user interfaces and see if the client-side response times are faster.
- Update all relevant read and write locations to reflect the repositories accessed.
- Remove unused ETL/ELT pipelines and data in the old repository.

Unexpected Roadblocks
When I began migrating, I noticed some variations in our target server. Initially, I installed various global dependencies, settings, and configurations in the new server. I migrated low-volume, non-mission critical data to verify the functionality of the target system. This allowed testing the compatibility of the source data’s data definition language (DDL) with the destination’s DDL. The DDL will be changed if the source and destination database schemas are incompatible. But then, there were some errors. On further inspection, I discovered that the new server didn’t support certain dependencies. These were outdated legacy dependencies that were incompatible with the new system.
Once this was identified, I decided to keep the legacy system dependencies, especially the outdated ones, on our old server. The new one has newer system dependencies, even Python versions. This was the compromise I settled on while trying to deal with the technical debt accrued. Now, two servers had dependencies for their workflows that didn’t have conflicts. I tried to migrate whatever I could, but the rest remained on the old server. I tested the new server to verify its functionality. I confirmed that this data is working correctly and rendered on the target side without errors or corruption.
I started migrating the data using the list generated from mapping and testing the dependencies on the new server. I found which tables should be migrated based on performance and server load. Then, I figured out which tables depend on a minimal number of ETL pipelines and no other tables. So, higher server loads with minimal dependencies were shifted first. This allowed for maximum impact and minimal blast radius in case of failure. After that, based on the migration criteria, I moved the rest of the data compatible with the new data infrastructure. You can transfer data incrementally in stages, test at frequent intervals, and keep the old and new systems running in parallel until we have a replica.
What went right
- After setting up the correct configurations and infrastructure in the new repository, the production data was transferred without any failure.
- Transferring small batches of production data allowed for comprehensive testing without huge drawbacks. Failures happened faster, which allowed for faster iterations of fixes.
- Referential integrity and consistency were maintained by mapping the table’s dependencies, and reliable data transfer was possible.
What went wrong
- The overall migration took longer than expected since we created a full replica of the old repository and all end-user interface data models. This new staging area was also tested rigorously, adding more time to complete the migration.
- The old system had many transient errors. These network glitches caused manual or automated restarts of many ELT/ETL pipelines, slowing the migration process.
- Tables had many upstream and downstream dependencies that hadn’t been mapped thoroughly before. This interdependency caused delays in figuring out how to move them safely without breaking production.
Conclusion
The data migration was successful. I set up an automated system that migrates the data to allow for minimum downtime, optimized performance, and increased stakeholder satisfaction. The initial objective of decreased database latencies and increased scalability was met. CPU utilization is around 70% during peak traffic, and workloads are distributed better. There are fewer complaints about “this never works when we want it to” and “the system is so slow and breaks constantly.” The improved user experience boosts morale and increases satisfaction.
The following are the key results achieved:
- Faster client-side response times
a) Better user experience
b) Increased user productivity - Performance improvement of servers
a) Faster processing of client requests
b) Reduced bottlenecks during peak-hour traffic. - Lesser “deadlock” scenarios where queries compete for limited resources and fail
a) Higher system reliability
b) Optimized resource allocation - Better visibility of end-to-end data flow within the organization
a) A better understanding of data dependencies
b) Improved the organization’s ability to track data flow - More scalability for future data volumes
a) Can handle larger volumes of data in the future without significant performance degradation.
b) Enables the organization to handle more users and data-intensive workloads
As the number of users and scale increases, the complexity increases significantly. Some technical debt was paid off, giving some breathing room. The migration will allow us to be better prepared to answer business needs for now.
I hope this will assist teams in their migration strategies and improving their data systems.
I’d love to hear any thoughts, comments, or questions about this blog. Feel free to reach out at my website or LinkedIn.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")