



Attention Mechanism
Last Updated on February 8, 2024 by Editorial Team
Author(s): Dr Barak Or
Originally published on Towards AI.
Attention Mechanism
Self Attention -concept
At the heart of the Transformer model lies the attention mechanism, a pivotal innovation designed to address the fundamental challenge of learning long-range dependencies within sequence transduction tasks. Traditionally, the effectiveness of neural networks in these tasks was hampered by the lengthy paths that signals needed to traverse, making the learning process cumbersome.
The attention mechanism revolutionizes this process by dramatically reducing the distance between any two positions in the input and output sequences, thereby streamlining the learning of these critical dependencies. As described by Vaswani and colleagues in their seminal 2017 paper, “Attention is all you need”, this mechanism allows the model to ‘focus’ on the most relevant parts of the input sequence when generating each element of the output sequence.
The attention mechanism operates on the principle of mapping a query alongside a series of key-value pairs to produce an output, where each component is represented as a vector. This architecture enables the model to compute the output as a weighted sum of the input values, with the weights themselves being determined through a compatibility function between the query and each key, as shown in the equation below and in the original attention architecture, above.
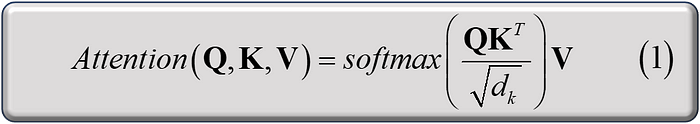
Queries, keys, and values
Let’s simplify the concepts of queries, keys, and values in the attention mechanism with a straightforward, detailed example:

Imagine you’re reading a book and come across the sentence, “The cat sat on the mat.” We want to understand the importance of “sat” in this context.

Query
This might be representing the word “sat” if we’re trying to understand how “sat” relates to other words in the sentence. The query is essentially asking, “What is relevant to ‘sat’ in this sentence?“
Queries represent our interest or what we are trying to understand or find more about. It reflects our quest for knowledge.
Key
Keys could be all the other words in the sentence or certain features of these words that help to identify their role or relationship to “sat.” Each word acts as a “key” that the attention mechanism will use to determine how relevant it is to the query. For example, “cat” and “mat” would be keys.
Keys are like the topics of the conversations happening around you. Each conversation has a key topic.
Value
In a straightforward application, the values could also be the words themselves or some representation of them that provides more context about the sentence. The value associated with each key provides the content that we care about once we’ve decided which keys are relevant to our query.
Values are the actual content of the conversations, what’s being said.
Calculating the attention, step by step
Let’s put some numbers and calculate the attention for our example.
First, we have embeddings for a small vocabulary, consisting only of the words in our sentence, each one is represented by a different 2D vector. As we focus on the word sat. Q for “sat” is given by the vector [1,1] focusing on action-related context.

Let’s build a vector for the query “sat” and a vector for the keys in our sentence. For simplicity, the key vector has the same embedding as the query vector. As mentioned above, keys are like tags for every word, indicating how relevant they might be to your focus. In our sentence, each word will have a key suggesting its relation to the concept of sitting. The second action to take is to calculate the dot product scores, where our query vector, in the example, for focusing on “sat” is [1,1]. We calculate the dot product score:

With this result, we have the nominator (in blue):

The third operation is the scaling of the resulting dot product by the square root of the dimensionality of the key vectors. This scaling is done to prevent extremely large values in the dot product, which can lead to gradients that are too small for effective learning during the following softmax step.
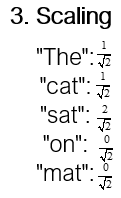
Up until now, we have obtained the blue items in the attention, as a result:

The forth operation is the Softmax activation function aims to convert the result into a probability distribution.

This step essentially transforms the raw scores into attention weights that sum up to 1, indicating the relative importance or relevance of each item in the sequence with respect to the query.

Thus far, we have essentially completed the entire attention mechanism calculation, with the final step being the multiplication by the V vector.

Let’s put side by side our attention scores from the softmax (what we have up to this step) and the value vector V:

The fifth and final step is computed as a weighted sum of the value vectors (V), where the weights are the attention scores from the softmax step.

The final output vector for “sat” is [0.7, 0.5]. This vector is a weighted representation of the word “sat” in the context of the sentence, focusing more on itself and the word “cat”.
Explanation: “sat” and “cat” are both related to the second dimension (as they the term “1” in the second cell of their vector representation (seen in their word vectors). The attention mechanism assigned a higher weight to the second dimension when computing the attention scores. The specific values, 0.7 and 0.5, indicate the degree of attention or emphasis placed on each dimension when calculating the weighted sum.
We demonstrated how the attention mechanism can dynamically emphasize certain parts of the input based on their relevance, allowing models to capture nuanced relationships in the data.
In real-world applications, these calculations involve high-dimensional vectors and are performed for every word in the sequence, enabling the model to understand complex dependencies in a given context.
In practical applications, the attention function is applied to a collection of queries at once, which are consolidated into a single matrix Q. Similarly, keys and values are grouped into matrices K and V, respectively.
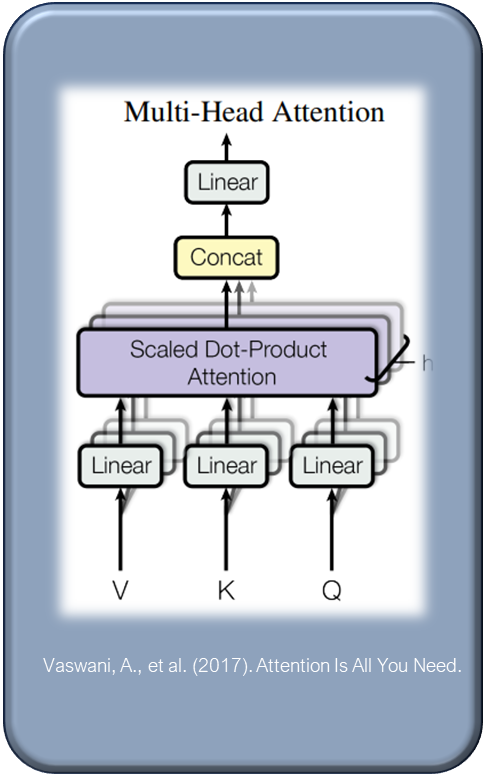
Multi-head Attention
This method innovates beyond the traditional attention mechanism, which utilizes keys, values, and queries of a uniform model dimension. Multi-head attention diverges by projecting these elements into different dimensions multiple time through unique, learned linear projections. This isn’t merely an expansion but a deliberate strategy to diversify attention across various dimensions.

Multi-head attention projects keys, queries, and values into multiple dimensions using distinct, learned linear transformations, creating several sets of these elements.
The benefits of multi-head attention are profound. It allows the model to simultaneously focus on distinct representation subspaces and positions, offering a comprehensive view of the information. It concatenates multiple heads of V K and Q.
Traditional single-head attention mechanisms might average out critical nuances, but multi-head attention maintains and emphasizes these distinctions.
The multi-head attention is described the following equations:
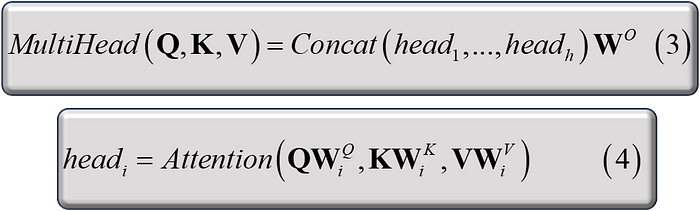
Equation (3) combines multiple attention heads (1 to h) using concatenation and a learned weight matrix Wo to produce the final output.
Equation (4) defines a single attention head (i), which takes the queries (Q) multiplied by the weight matrix WQ, keys (K) multiplied by WK, and values (V) multiplied by WV as inputs to compute attention scores and produce a weighted output. All of these W matrices are the weights for Q, K, and V, respectively (for a single head)
-Overcomes the averaging issue of single-head attention.
-Parallel attention layers, enhancing the model’s ability to capture diverse aspects of data
Conclusions
In conclusion, self-attention is a foundational concept in the Transformer model, addressing the challenge of learning long-range dependencies in sequences. It allows models to focus on relevant elements using queries, keys, and values. Multi-head attention further enhances this by diversifying attention across dimensions, providing a comprehensive view of information and improving the model’s ability to capture complex relationships in data.
References
[1] Vaswani, A., et al. (2017). Attention Is All You Need.
[2] Bahdanau, D., et al. (2015). Neural Machine Translation by Jointly Learning to Align and Translate.
[3] Luong, M. T., et al. (2015). Effective Approaches to Attention-based Neural Machine Translation.
About the Author
Dr. Barak Or is a professional in the field of artificial intelligence and sensor fusion. He is a researcher, lecturer, and entrepreneur who has published numerous patents and articles in professional journals. Dr. Or leads the MetaOr Artificial Intelligence firm. He founded ALMA Tech. LTD holds patents in the field of AI and navigation. He has worked with Qualcomm as DSP and machine learning algorithms expert. He completed his Ph.D. in machine learning for sensor fusion at the University of Haifa, Israel. He holds M.Sc. (2018) and B.Sc. (2016) degrees in Aerospace Engineering and B.A. in Economics and Management (2016, Cum Laude) from the Technion, Israel Institute of Technology. He has received several prizes and research grants from the Israel Innovation Authority, the Israeli Ministry of Defence, and the Israeli Ministry of Economic and Industrial. In 2021, he was nominated by the Technion for “graduate achievements” in the field of High-tech.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")