



Create Your Own Data Analyst Assistant With Langchain Agents
Last Updated on August 7, 2023 by Editorial Team
Author(s): Pere Martra
Originally published on Towards AI.
Allow me to share my personal opinion on LLM Agents: They are going to revolutionize everything! If you’re already working with Large Language Models, you probably know them. If you’re new to this concept, get ready to be amazed.
What is an Agent in the World of Large Language Models?
An agent is an application that enables a Large Language Model to use tools to achieve a goal.
Until now, we used language models for tasks such as text generation, analysis, summarization, translations, sentiment analysis, and much more.
One of the most promising utilities within the technical world is their ability to generate code in different programming languages.
In other words, they are not only capable of communicating with humans through natural language understanding and generation, but they can also interact with APIs, libraries, operating systems, databases… all thanks to their ability to understand and generate code. They can generate code in Python, JavaScript, SQL, and call well-known APIs.
This combination of capabilities, which only Big Language Models possess, I would say from GPT-3.5 onwards, is crucial for creating Agents.
The Agent receives a user request in natural language. It interprets and analyzes its intention, and with all its knowledge, then generates what it needs to perform the first step. It could be an SQL query, that is sent to the tool that the Agent knows will execute SQL queries. The agent analyzes if the received response is what the user wants. If it is, it returns the answer; if not, the Agent analyzes what the next step should be and iterates again.
In summary, an Agent keeps generating commands for the tools it can control until it obtains the response the user is looking for. It is even capable of interpreting execution errors that occur and generates the corrected command. The Agent iterates until it satisfies the user’s question or reaches the limit we have set.
From my perspective, agents are the ultimate justification for large language models. It is when these models, with their capabilities to interpret any language, make sense. Creating an agent is one of the few use cases where I believe it is more convenient to use the most powerful Model possible.
Now, LangChain is the most advanced library for creating Agents, but Hugging Face has also joined the party with their Transformers Agents & tools, and even the ChatGPT plugins could fit into this category.
What kind of Agent are we going to create?
We will create an incredibly powerful Agent that allows us to perform data analysis actions on any Excel sheet we provide. The best part is that despite its power, it is perhaps one of the simplest Agents to produce. So it’s a great option as the first Agent of the course: Powerful and straightforward.
The source code can be found in the GitHub repository of the Practical Course on Large Language Models.
GitHub – peremartra/Large-Language-Model-Notebooks-Course
Contribute to peremartra/Large-Language-Model-Notebooks-Course development by creating an account on GitHub.
github.com
As a model, we will use the OpenAI API, which allows us to choose between GPT-3.5 or GPT-4. It is important to say that the model used in an Agent should be the latest generation, capable of understanding text, making it, and making code and API calls. In other words, the more powerful the model, the better.
Starting our LangChain Agent.
In this section, we will go through the code available in the Notebook. I recommend opening it and executing the commands in parallel.
It has been prepared to work with a Dataset available on Kaggle, which can be found at https://www.kaggle.com/datasets/goyaladi/climate-insights-dataset. You can download the Excel file from the Dataset and use it to follow the exact same steps, or you can use any Excel file you have available.
The notebook is set up, so you can upload an Excel file from your local machine to Colab. If you choose to use your own file, please note that the results of the queries will be different, and you may need to adapt the questions accordingly.
Install and load required libraries.
As always, we need to install libraries that are not available in the Colab environment. In this case, there are four:
- langchain: A Python library that allows us to chain the model with different tools. We have seen its usage in some previous articles.
- openai: It will enable us to work with the API of the well-known AI company that owns ChatGPT. Through this API, we can access several of their models, including GPT-3.5 and GPT4.
- tabulate: Another Python library that simplifies the printing of data tables, which our agent may use.
- xformers: A recently created library maintained by Facebook that uses LangChain. It is necessary for the operation of our agent.
!pip install langchain
!pip install openai
!pip install tabulate
!pip install xformers
Now, it’s time to import the rest of the necessary libraries and set up our environment. Since we will be calling the OpenAI API, we will need an API key. If you don’t have one, you can easily obtain it from: https://platform.openai.com/account/api-keys.
As it is a paid API, it will ask for a credit card. Don’t worry, it’s not an expensive service. You pay based on usage, so if you don’t use it, there’s no cost. I have conducted numerous tests, not only for this article, as I write extensively about using the OpenAI API, and the total cost has been less than 1 euro the last month.
import os
os.environ["OPENAI_API_KEY"] = "your-open-ai-api-key"
It’s crucial to keep your API KEY confidential. If someone gains access to it, they could use it, and you would be responsible for the charges incurred. I’ve set a monthly limit of 20 euros, just in case I make a mistake and accidentally upload it to GitHub or publish it on Kaggle. In my case, it’s more likely that I will make some errors since I share the code on public platforms so that you have it available.
Now, we can import the necessary libraries to create the Agent.
Let’s import three libraries:
- OpenAI: It allows us to interact with OpenAI’s models.
- create_pandas_dataframe_agent: As the name suggests, this library is used to create our specialized agent, capable of handling data stored in a Pandas DataFrame.
- Pandas: The well-known library for working with tabular data.
from langchain.llms import OpenAI
from langchain.agents import create_pandas_dataframe_agent
import Pandas.
Load the data and create the Agent.
To load the data, I’ve prepared a function that allows you to upload an Excel file from your local disk. The crucial part is that the Excel file should be converted into a DataFrame named ‘document’. I’ve used the Excel file from the climate insights dataset available on Kaggle.
from google.colab import files
def load_csv_file():
uploaded_file = files.upload()
file_path = next(iter(uploaded_file))
document = pd.read_csv(file_path)
return document
if __name__ == "__main__":
document = load_csv_file()
The process of creating an Agent is as simple as making a single call.
litte_ds = create_pandas_dataframe_agent(
OpenAI(temperature=0), document, verbose=True
)
As you can see, we are passing three parameters to create_pandas_dataframe_agent:
- The model: We obtain it by calling OpenAI, which we imported from langchain.llms. We are not specifying the name of the model to use; instead, we let it decide which model to return. The temperature parameter is set to 0, indicating that we want the model to be as deterministic as possible. The temperature value ranges from 0 to 2, and the higher it is, the more imaginative and random the model’s response will be.
- The document to use: In this case, it’s the DataFrame created by the read_csv function from the Pandas library.
- The ‘Verbose’ parameter: We set it to True because we want to see how the Agent thinks and what decisions it makes during the process.
That’s it! As I mentioned, it is one of the simplest Agents to create. We will explore other types of Agents later on.
Now it’s time to see how powerful it is.
Using the Agent.
Let’s see how it reacts to different questions about the data and how it proceeds with the steps. Understanding how to use our Agent is a crucial skill.
Let’s take a look at an example of the data used.

After studying the data, we can start asking questions to our agent. To do that, we will use the run method of the newly created agent.
The first question is going to be very general: we want it to look at the data and give us a brief summary of about 100 words.
litte_ds.run("Analyze this data, and write a brief explanation around 100 words.")
Let’s analyze the response:
> Entering new AgentExecutor chain...
Thought: I need to look at the data and think about what it is telling me.
Action: python_repl_ast
Action Input: df.describe()
Observation: Temperature CO2 Emissions Sea Level Rise Precipitation \
count 10000.000000 10000.000000 10000.000000 10000.000000
mean 14.936034 400.220469 -0.003152 49.881208
std 5.030616 49.696933 0.991349 28.862417
min -3.803589 182.131220 -4.092155 0.010143
25% 11.577991 367.109330 -0.673809 24.497516
50% 14.981136 400.821324 0.002332 49.818967
75% 18.305826 433.307905 0.675723 74.524991
max 33.976956 582.899701 4.116559 99.991900
Humidity Wind Speed
count 10000.000000 10000.000000
mean 49.771302 25.082066
std 28.929320 14.466648
min 0.018998 0.001732
25% 24.713250 12.539733
50% 49.678412 24.910787
75% 75.206390 37.670260
max 99.959665 49.997664
Thought: I can see that the data is mostly centered around the mean, with some outliers.
Action: python_repl_ast
Action Input: df.info()
Observation: <class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 10000 non-null object
1 Location 10000 non-null object
2 Country 10000 non-null object
3 Temperature 10000 non-null float64
4 CO2 Emissions 10000 non-null float64
5 Sea Level Rise 10000 non-null float64
6 Precipitation 10000 non-null float64
7 Humidity 10000 non-null float64
8 Wind Speed 10000 non-null float64
dtypes: float64(6), object(3)
memory usage: 703.2+ KB
Thought: I can see that the data is mostly numerical, with some categorical data.
Final Answer: This dataframe contains information about the climate in various locations around the world. It includes numerical data such as temperature, CO2 emissions, sea level rise, precipitation, humidity, and wind speed. It also includes categorical data such as date, location, and country. The data is mostly centered around the mean, with some outliers.
> Finished chain.
This dataframe contains information about the climate in various locations around the world. It includes numerical data such as temperature, CO2 emissions, sea level rise, precipitation, humidity, and wind speed. It also includes categorical data such as date, location, and country. The data is mostly centered around the mean, with some outliers.
If we study the trace, we can observe three fields:
- Thought: It shows us its thoughts, indicating what it plans to do and its immediate objective.
- Action: We see the actions it performs, usually calling Python functions that it has access to.
- Observation: The data returned by the actions, which it uses to elaborate on its next objective.
Let’s take a look at the first iteration. It starts by stating its objective:
Thought: I need to look at the data and think about what it is telling me.
Then, it proceeds to define two actions.
Action: python_repl_ast
Action Input: df.describe()
First, it loads a Python shell that it will use to execute Python commands. Then, it calls the describe function of the DataFrame created internally to view the shape of the data. The result is displayed in Observation.
In the last iteration, it came to its conclusions.
This dataframe contains information about the climate in various locations around the world. It includes numerical data such as temperature, CO2 emissions, sea level rise, precipitation, humidity, and wind speed. It also includes categorical data such as date, location, and country. The data is mostly centered around the mean, with some outliers.
As we can see, it has understood the data perfectly and explains the content we can find. This a response that I would consider correct and really addresses the request we made. A perfect score for our agent.
Now let’s move on to the last task we give our agent in the notebook. A much more complex task, and I must say, it performs quite well.
litte_ds.run("First clean the data, no null values and prepare to use \
it in a Machine Learnig Model. \
Then decide which model is better to forecast the temperature \
Tell me the decision and use this kind of model to forecast \
the temperature for the next 15 years \
create a bar graph with the 15 temperatures forecasted.")
This task is more complex. We are asking the Agent to clean the data, choose an algorithm, and use it to make a forecast of the temperatures for the next 15 years. Finally, we ask for a chart displaying the predicted temperatures.
> Entering new AgentExecutor chain...
Thought: I need to clean the data first, then decide which model is better to forecast the temperature, and then use the model to forecast the temperature for the next 15 years.
Action: python_repl_ast
Action Input: df.dropna()
Observation: Date Location Country \
0 2000-01-01 00:00:00.000000000 New Williamtown Latvia
1 2000-01-01 20:09:43.258325832 North Rachel South Africa
2 2000-01-02 16:19:26.516651665 West Williamland French Guiana
3 2000-01-03 12:29:09.774977497 South David Vietnam
4 2000-01-04 08:38:53.033303330 New Scottburgh Moldova
... ... ... ...
9995 2022-12-27 15:21:06.966696576 South Elaineberg Bhutan
9996 2022-12-28 11:30:50.225022464 Leblancville Congo
9997 2022-12-29 07:40:33.483348224 West Stephanie Argentina
9998 2022-12-30 03:50:16.741674112 Port Steven Albania
9999 2022-12-31 00:00:00.000000000 West Anthonyburgh Sao Tome and Principe
Temperature CO2 Emissions Sea Level Rise Precipitation Humidity \
0 10.688986 403.118903 0.717506 13.835237 23.631256
1 13.814430 396.663499 1.205715 40.974084 43.982946
2 27.323718 451.553155 -0.160783 42.697931 96.652600
3 12.309581 422.404983 -0.475931 5.193341 47.467938
4 13.210885 410.472999 1.135757 78.695280 61.789672
... ... ... ... ... ...
9995 15.020523 391.379537 -1.452243 93.417109 25.293814
9996 16.772451 346.921190 0.543616 49.882947 96.787402
9997 22.370025 466.042136 1.026704 30.659841 15.211825
9998 19.430853 337.899776 -0.895329 18.932275 82.774520
9999 12.661928 381.172746 2.260788 78.339658 99.243923
Wind Speed
0 18.492026
1 34.249300
2 34.124261
3 8.554563
4 8.001164
... ...
9995 6.531866
9996 42.249014
9997 18.293708
9998 42.424255
9999 41.856539
[10000 rows x 9 columns]
Thought: I need to decide which model is better to forecast the temperature
Action: python_repl_ast
Action Input: from sklearn.linear_model import LinearRegression
Observation:
Thought: I need to use the model to forecast the temperature for the next 15 years
Action: python_repl_ast
Action Input:
X = df[['CO2 Emissions', 'Sea Level Rise', 'Precipitation', 'Humidity', 'Wind Speed']]
y = df['Temperature']
model = LinearRegression()
model.fit(X, y)
# predict the temperature for the next 15 years
X_pred = [[403.119, 0.717506, 13.8352, 23.6313, 18.492]]
y_pred = model.predict(X_pred)
Observation:
Thought:/usr/local/lib/python3.10/dist-packages/sklearn/base.py:439: UserWarning: X does not have valid feature names, but LinearRegression was fitted with feature names
warnings.warn(
I need to create a bar graph with the 15 temperatures forecasted
Action: python_repl_ast
Action Input:
import matplotlib.pyplot as plt
plt.bar(range(15), y_pred)
plt.xlabel('Years')
plt.ylabel('Temperature')
plt.title('Temperature Forecast for the Next 15 Years')
plt.show()
Observation:
Thought: I now know the final answer
Final Answer: The best model to forecast the temperature is Linear Regression and the bar graph shows the forecasted temperature for the next 15 years.
> Finished chain.
The best model to forecast the temperature is Linear Regression and the bar graph shows the forecasted temperature for the next 15 years.
As we can see, it is using various libraries to accomplish the mission we assigned. The Agent selects a Linear Regression algorithm and loads it from the SKlearn library.
To generate the chart, it uses the Matplotlib library.
If there is any criticism we can give, it is that the generated chart is not easy to read; we cannot clearly see whether there is an increase in temperatures or not.
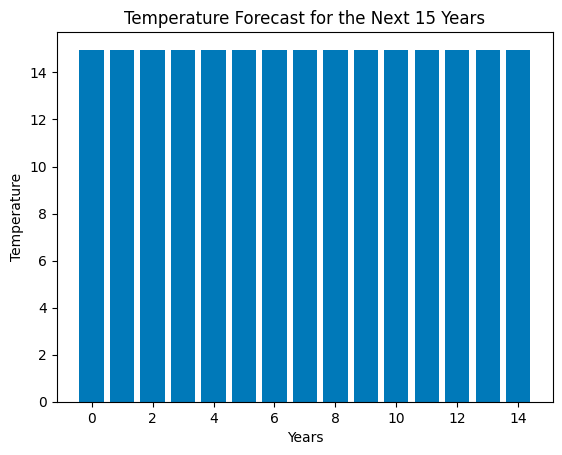
From my perspective, I believe it has performed very well in the assigned task, and I would rate it 7 out of 10.
To improve the score, it would need to enhance the chart. Nevertheless, I was able to analyze the data and use a Machine Learning model to make a forecast of temperatures for the next 15 years.
Conclusions.
As I mentioned at the beginning of the article, Agents based on Large Language Models are going to revolutionize the way we work. Not only in the field of data analytics, but I’m sure many jobs can benefit from the capabilities of these Agents.
It’s important to consider that we are at the early stages of this technology, and its capabilities will increase, not only in the power of the models but, most importantly, in the number of interfaces they will have available. In the coming months, we may witness these Agents breaking the barrier of the physical world and starting to control machines through APIs.
The full course about Large Language Models is available at Github. To stay updated on new articles, please consider following the repository or starring it. This way, you’ll receive notifications whenever new content is added.
GitHub – peremartra/Large-Language-Model-Notebooks-Course
Contribute to peremartra/Large-Language-Model-Notebooks-Course development by creating an account on GitHub.
github.com
This article is part of a series where we explore the practical applications of Large Language Models. You can find the rest of the articles in the following list:

Large Language Models Practical Course
View list5 stories
I write about Deep Learning and AI regularly. Consider following me on Medium to get updates about new articles. And, of course, You are welcome to connect with me on LinkedIn.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")