



From Pixels to Artificial Perception
Last Updated on July 25, 2023 by Editorial Team
Author(s): Ali Moezzi
Originally published on Towards AI.
Understanding Computer Vision Fundamentals: An Introduction to Image Intrinsic, Representation, Features, Filters and Morphological Operations
Computer vision is a fascinating field that aims to teach machines how to “see” the world as we do. It has numerous practical applications in areas such as self-driving cars, facial recognition, object detection, and medical imaging. In this article, I will first go over what constitutes features in images and how we can manipulate them, and then I will go over various priors from computer vision that are being used in deep learning.
Unsurprisingly, we humans only perceive a portion of the electromagnetic spectrum. As a result, imaging devices are adapted to represent human perception of scenes as possible. Cameras process raw sensor data through a series of operations to achieve a highly familiar representation of human perception. Likewise, even radio-graphic images are calibrated to aid humans perception [2].
The camera sensor produces a grayscale grid structure that is constructed through a Bayer color filter mosaic. Cells in this grid represent intensities of a particular color. Thus, instead of recording a 3×8-bit array for every pixel, each filter in the Bayer filter records one color. Inspired by the fact that the human eye is more sensitive to green light, Bryce Bayer allocated twice the filters for green color than blue or red.
Camera ISP then reconstructs the image by applying a demosaicing algorithm in the form of color space. In computer vision, images are represented using different color spaces. The most common color space is RGB (Red, Green, Blue), where each pixel is interpreted as a 3D cube with dimensions of width, height, and depth (3 for RGB).
Another widely used color space is BGR (Blue, Green, Red), which was popular during the development of OpenCV. Unlike RGB, BGR considers the red channel as the least important. After this, a series of transformations such as black level correction, intensity adjustment, white balance adjustment, color correction, gamma correction, and finally, compression is applied.
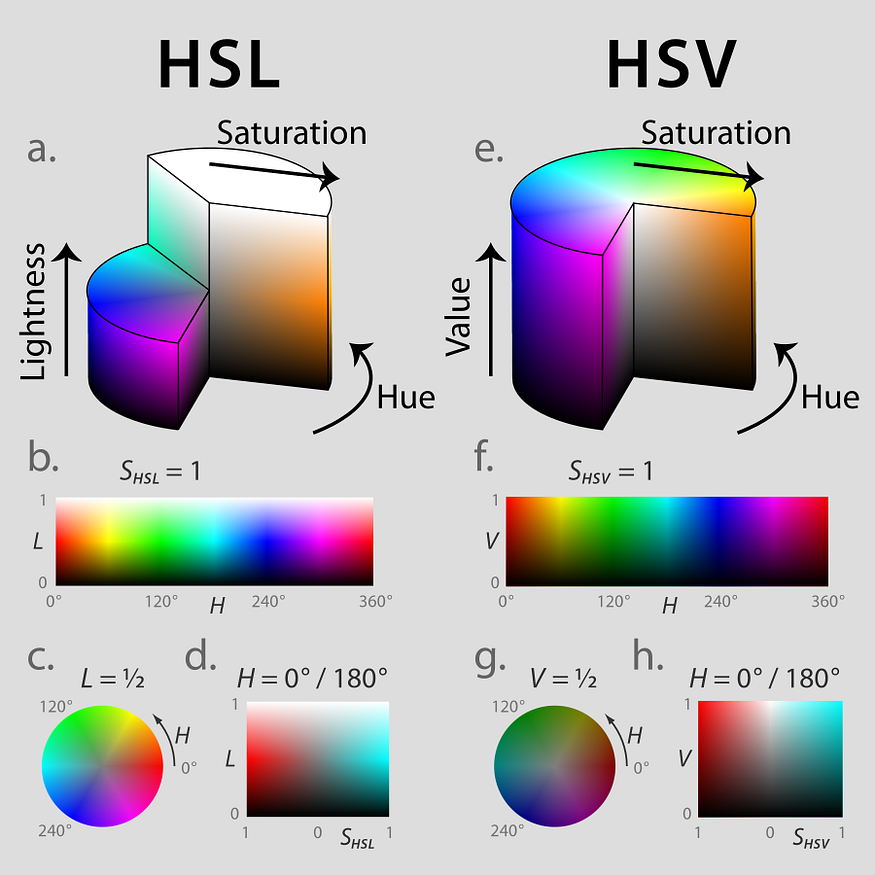
Apart from RGB and BGR, there are other color spaces like HSV (Hue, Saturation, Value) and HSL (Hue, Lightness, Saturation). HSV isolates the value component of each pixel, which varies the most during changes in lighting conditions. The H channel in HSV remains fairly consistent, even in the presence of shadows or excessive brightness. HSL, on the other hand, represents images based on hue, lightness, and saturation values.
Features
In computer vision, we look for features to identify relevant patterns or structures within an image. Features can include edges, corners, or blobs, which serve as distinctive attributes for further analysis. Edges are areas in an image where the intensity abruptly changes, often indicating object boundaries. Understanding the frequency of images is also essential, as high-frequency components correspond to the edges of objects.

The Fourier Transform is used to decompose an image into frequency components. The resulting image in the frequency domain helps identify low and high-frequency regions, revealing details about the image’s content.
Corners represent the intersection of two edges, making them highly unique and useful for feature matching. Blobs, on the other hand, are regions with extreme brightness or unique texture, providing valuable information about objects in an image.
The ultimate goal of understanding features in images is to preciously align them with our specific requirements or leverage them for other tasks such as object detection. Next, I will discuss some fundamental operations to help us through this process.
Morphological Operation
Features I talked about in the previous section are sometimes not perfect. They might have some noise or extra artifacts that interfere with the rest of our pipeline. However, some simple operations on the image can enhance edges, shapes, and boundaries to reduce these artifacts. We borrow the term “Morphology” from biology as in this subfield, the shapes and structures of plants and animals are studied.
Similarly, in computer vision, we have a large number of operations to help us process the image better. These operations work by moving a “structured element” across the image. The structured element is a small grid, fairly similar to filters that we cover in the coming sections, yet it has only 0, 1 to include or exclude nearby pixels. In other words, a pixel is kept, only if nearby pixels corresponding to elements with value 1 have value > 0; otherwise discarded.

Dilation
Dilation grows the foreground object by adding pixels to the boundaries of that object. It is useful to connect disjointed or fragmented parts of an object.

Erosion
This operation removes pixels and peels the object along the boundaries. Erosion is particularly useful for removing noise and small artifacts.

Opening
The opening is a compound operation consisting of erosion followed by dilation. While erosion eliminates small objects, it has a caveat where it manipulates object shape. Dilation alleviates this by growing back object boundaries.
Closing
In case, the noise is inside object boundaries, we may want to close these small gaps in the object. As a result, unlike opening, we first apply Dilation to fill in small holes, followed by an Erosion operation to peel object boundaries that should be kept intact but might be diluted by the previous operation.
Filters
Filters play a fundamental role in computer vision, allowing the isolation or enhancement of specific frequency ranges within an image. They are used to filter out irrelevant information, reduce noise, or amplify important features. One popular filter is the Canny Edge detection, which employs both low-pass and high-pass filters in combination for accurate edge detection.
High-pass Filters

High-pass filters amplify high-frequency components, such as edges, while suppressing low-frequency information. They emphasize changes in intensity, making them valuable for edge detection and enhancing image features. One commonly used high-pass filter is the Sobel filter, which is designed to detect vertical or horizontal edges. By calculating the gradient magnitude and direction of an image, the Sobel filter identifies the strength and orientation of edges, enabling precise edge detection.
Low-pass Filters

Low-pass filters, on the other hand, are used to reduce noise and blur an image, thus smoothing out high-frequency components. They block high-frequency parts of an image and take an average of surrounding pixels. One common low-pass filter is the averaging filter, which applies a 3×3 matrix to weight each pixel and its neighbors equally. This filter brightens the corresponding pixel in the filtered image, resulting in a smoother appearance.
Another widely used filter is the Gaussian filter, which not only blurs the image but also preserves edges better compared to the averaging filter.
Convolution Kernels
Convolution kernels, in general, are matrices that modify an image during filtering. For edge detection, it is crucial that the elements in the kernel sum to zero, allowing the filter to compute the differences or changes between neighboring pixels.
Image Intrinsics

Humans have an extraordinary ability to recognize objects in unfamiliar scenes regardless of viewing angle or lighting. Early experiments by Land et al. [3] and Horn et al. [4] have let us understand more about Retinex Theory. Based on this Theory, Barrow et al. distinguished an image into three intrinsic components — reflectance, orientation, and illumination. In practice, most methods consider intrinsic image decomposition as decomposing an image into its material-dependent properties, referred to as reflectance or Albedo, and its light-dependent properties, such as shading. Theory suggests reflectance changes result in sharp gradient changes in our retina while, the shading makes smooth gradient changes [3].
Altogether, although deep learning has enabled implicit learning many previous prior where it was used to design image decomposition algorithms, few priors are more often used to enhance the convergence and robustness of models [1].
First, the independent perception of colors from illumination conditions in the human perception system is the basis for the assumption that Albedo is piece-wise flat of high frequency and sparse [1]. Che et al. [6] and Ma et al. used this prior to forming an L1 loss function. On the contrary, a differentiable filtering operation can guide the network towards generating a piece-wise flat Albedo, like seen in works by Fan et al. [8].
The second prior is to ensure the smoothness of shading based on Retinex theory [3]. In deep learning, Cheng et al. [6] modeled this as an L1 norm, while Ma et al. [7] used second-order optimization to ensure smooth shading gradients.
Fast forward today, many researchers have used these priors as inductive bias in their network. In essence, the main lines of work are learning from weak supervision that uses human-annotated similar Albedo regions in an image, full-supervision where a complete set of Albedo and shadow labels are provided, and self-supervision. Supervised approaches require a vast amount of data to generalize adequately [1].
Hence, self-supervised approaches by incorporating them into loss functions in the form of Render Loss or Image Formation Loss can more efficiently decompose intrinsic components.

Final Thoughts
Deep Learning has helped us perform computer vision tasks in an end-to-end fashion. Nonetheless, the challenge of generalization in Deep Learning has transformed the role of legacy computer vision techniques from primarily tedious feature engineering to data augmentation or as priors embedded in models. By mastering these concepts, we can develop a deeper understanding of how these building blocks can elevate our computer vision pipelines.
I will write more articles in CS. If you’re as passionate about the industry as I am ^^ and find my articles informative, be sure to hit that follow button on Medium and continue the conversation in the comments if you have any questions. Don’t hesitate to reach out to me directly on LinkedIn!
References:
[1] Garces, E., Rodriguez-Pardo, C., Casas, D., & Lopez-Moreno, J. (2022). A survey on intrinsic images: Delving deep into lambert and beyond. International Journal of Computer Vision, 130(3), 836–868.
[2] Oala, L., Aversa, M., Nobis, G., Willis, K., Neuenschwander, Y., Buck, M., … & Sanguinetti, B. Data Models for Dataset Drift Controls in Machine Learning With Optical Images. Transactions on Machine Learning Research.
[3] Land, E.H., & McCann, J.J. (1971). Lightness and retinex theory. Journal of the Optical Society of America, 61 1, 1–11.
[4] Horn, B.K. (1974). Determining lightness from an image. Comput. Graph. Image Process., 3, 277–299.
[5] Tang, Y., Salakhutdinov, R., & Hinton, G. (2012). Deep lambertian networks. arXiv preprint arXiv:1206.6445.
[6] Cheng, L., Zhang, C., & Liao, Z. (2018). Intrinsic image transformation via scale space decomposition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 656–665).
[7] Ma, W. C., Chu, H., Zhou, B., Urtasun, R., & Torralba, A. (2018). Single image intrinsic decomposition without a single intrinsic image. In Proceedings of the European Conference on computer vision (ECCV) (pp. 201–217).
[8] Fan, Q., Yang, J., Hua, G., Chen, B., & Wipf, D. (2018). Revisiting deep intrinsic image decompositions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 8944–8952).
[9] Sengupta, S., Gu, J., Kim, K., Liu, G., Jacobs, D. W., & Kautz, J. (2019). Neural inverse rendering of an indoor scene from a single image. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 8598–8607).
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")