



Understanding BERT
Last Updated on July 24, 2023 by Editorial Team
Author(s): Shweta Baranwal
Originally published on Towards AI.
Natural Language Processing
BERT (Bidirectional Encoder Representations from Transformers) is a research paper published by Google AI language. Unlike previous versions of NLP architectures, BERT is conceptually simple and empirically powerful. It obtains a new state of the art results on 11 NLP tasks.
BERT has a benefit over another standard LM because it applies deep bidirectional context training of the sequence meaning it considers both left and right context while training whereas other LM model such as OpenAI GPT is unidirectional, every token can only attend to previous tokens in attention layers. Such restrictions are suboptimal for sentence-level tasks (paraphrasing) or token level tasks (named entity recognition, question-answering) where it is crucial to incorporate context from both directions.
What is BERT?
In earlier versions of LM such as Glove, we have fixed embeddings of the words, for example, for the word “right” the embedding is the same irrespective of its context in the sentence. Does it mean “correct” or “right direction”? Then came ELMo (bi-directional LSTM), it tried to solve this problem by using the left and right context for generating embeddings but it simply concatenated the left-to-right and right-to-left information, meaning that the representation couldn’t take advantage of both left and right contexts simultaneously. Then BERT with its attention layers outperformed all the previous models.

The basic architecture of the Transformer, a popular attention model, has two major components: Encoder and Decoder. The encoder part reads the input sequence and processes it and the Decoder part takes the processed input from Encoder and re-process it to perform the prediction task. To understand more about the transformer refer: here. Since here we are interested in generating the Language Model (LM), only the Encoder part is necessary. BERT uses this transformer encoder architecture to generate bi-directional self-attention for the input sequence. It reads the entire sentence in one go and attention layers learn the context of a word from all of its left and right surrounding words.
Pre-training BERT:
The pre-training of the BERT is done on an unlabeled dataset and therefore is un-supervised in nature. There are two pre-training steps in BERT:
- Masked Language Model (MLM)
a) Model masks 15% of the tokens at random with [MASK] token and then predict those masked tokens at the output layer. Loss is based only on the prediction of masked tokens not on all tokens’ prediction.
b) During fine-tuning of the model [MASK] token does not appear, creating a mismatch, in order to mitigate this, if i-th token is chosen for masking during pre-training, it is replaced with:
80% times [MASK] token: My dog is hairy → My dog is [MASK]
10% times Random word from the corpus: My dog is hairy → My dog is apple
10% times Unchanged: My dog is hairy → My dog is hairy

2. Next Sentence Prediction
a) In this pre-training approach, given the two sentences A and B, the model trains on binarized output whether the sentences are related or not.
b) While choosing the sentence A and B for pre-training examples, 50% of the time B is the actual next sentence that follows A (label: IsNext), and 50% of the time it is a random sentence from the corpus (label: NotNext).

The training loss is the sum of the mean masked LM likelihood and the mean next sentence prediction likelihood.
In prior works of NLP, only sentence embeddings are transferred to downstream tasks, whereas BERT transfers all parameters of pre-training to initialize models for different downstream tasks. The pre-trained BERT models are made available by Google and can be used directly for the fine-tuning downstream tasks.

BERT Architecture:
BERT’s model architecture is a multilayer bi-directional Transformer encoder based on Google’s Attention is all you need paper. It comes in two model forms:
BERT BASE: less transformer blocks and hidden layers size, have the same model size as OpenAI GPT. [12 Transformer blocks, 12 Attention heads, 768 hidden layer size]
BERT LARGE: huge network with twice the attention layers as BERT BASE, achieves a state of the art results on NLP tasks. [24 Transformer blocks, 16 Attention heads, 1024 hidden layer size]
During fine-tuning of the model, parameters of these layers (Transformer blocks, Attention heads, hidden layers) along with additional layers of the downstream task are fine-tuned end-to-end.
BERT Input Representations:
- The first token of every sequence is always a special classification token [CLS]. The final hidden state corresponding to this token is used for the classification task.
- The two sentences are separated using the [SEP] token.
- In the case of sentence pair, a segment embedding is added which indicates whether the token belongs to sentence A or sentence B.
- For a given token, its input representation is constructed by adding the corresponding token, segment and position embedding.

Fine-tuning BERT:
Fine-tuning BERT is simple and straightforward. The model is modified as per the task in-hand. For each task, we simply plug in the task-specific inputs and outputs into BERT and fine-tune all the parameters end-to-end.
At the input, sentence A and sentence B from pre-training are analogous to
- sentence pairs in paraphrasing
- hypothesis-premise pairs in entailment
- question-passage pairs in question answering
- a degenerate text-∅ pair in text classification or sequence tagging.
At the output, the token representations are fed into an output layer for token level tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as sentiment analysis.
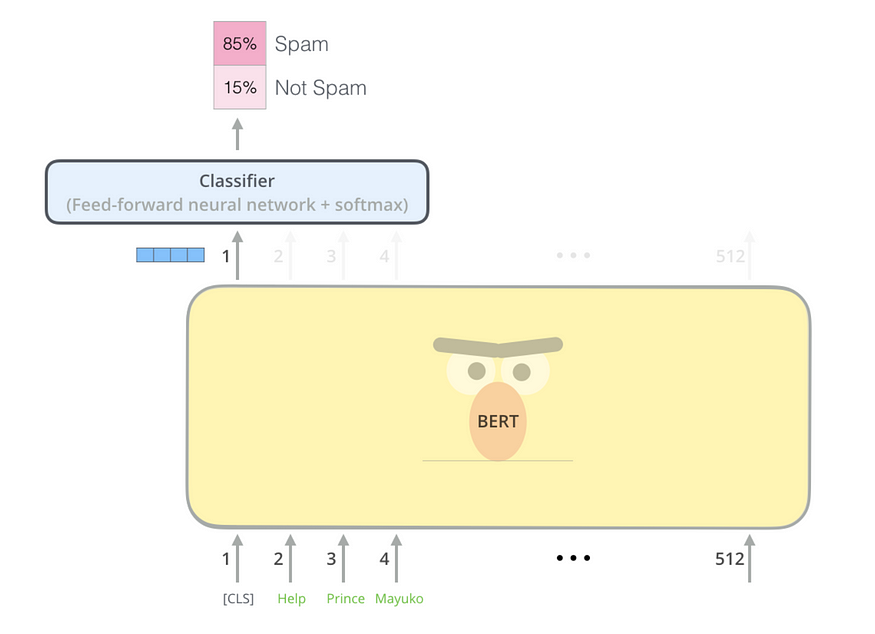
HuggingFace has provided a framework for fine-tuning task-specific models as well.

Model framework for MaskedLM, NextSentence Prediction, Sequence Classification, Multiple Choice, etc. are readily available along with pre-training parameters for BERT. These are simple and fun to implement.
BERT Tokenizer:

In the BERT input representations we have seen there are three types of embeddings we need (token, segment, position). The Transformers package by HuggingFace constructs the tokens for each of the embedding requirements (encode_plus). Here both pre-trained tokenizer, as well as tokenizer from a given vocab file, can be used.

BERT tokenizer uses WordPiece Model for tokenization. It breaks the words into sub-words to increase the coverage of vocabulary.
Word: Jet makers feud over seat width with big orders at stake
Wordpieces: _J et _makers _fe ud _over _seat _width _with _big _orders _at _stake
In the above example, the word “Jet” is broken into two wordpieces “_J” and “et”, and the word “feud” is broken into two wordpieces “_fe” and “ud”. The other words remain as single wordpieces. “_” is a special character added to mark the beginning of a word.
ShwetaBaranwal/BERT
Contribute to ShwetaBaranwal/BERT development by creating an account on GitHub.
github.com
References:
BERT – transformers 2.4.1 documentation
The BERT model was proposed in BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by…
huggingface.co
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations…
jalammar.github.io
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations…
arxiv.org
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Neural Machine Translation (NMT) is an end-to-end learning approach for automated translation, with the potential to…
arxiv.org
google-research/bert
This is a release of several new models which were the result of an improvement the pre-processing code. In the…
github.com
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")