



Chest X-Ray Based Pneumonia Classification
Last Updated on July 24, 2023 by Editorial Team
Author(s): Akula Hemanth Kumar
Originally published on Towards AI.
Making computer vision easy with Monk, low code Deep Learning tool and a unified wrapper for Computer Vision.
Monk Library
U+1F4CCMonk is an opensource low-code tool for computer vision and deep learning.
Monk features
U+1F4CC Low-code.
U+1F4CC Unified wrapper over major deep learning framework-Keras, PyTorch, Gluoncv.
U+1F4CC Syntax invariant wrapper.
Enables
U+1F4CC Users to create, manage and version control deep learning experiments.
U+1F4CC Users to compare experiments across training metrics.
U+1F4CC Users to quickly find the best hyperparameters.
Table of Contents
U+2611 Installation
U+2611 Download dataset
U+2611 Details on dataset
U+2611 Quick Prototyping-Training, Validation, and Inference
U+2611 Train a classifier using Resnet50
U+2611 Train a classifier using Densenet121
U+2611 Compare Experiments
Installation
$ !git clone https://github.com/Tessellate-Imaging/monk_v1.git# If using Colab install using the commands below
$ !cd monk_v1/installation/Misc && pip install -r requirements_colab.txt
Download dataset
Dataset — Chest X-Ray Images (Pneumonia)
$ ! wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1li6ctqAvGFgIGMSt-mYrLoM_tbYkzqdO' -O- U+007C sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1li6ctqAvGFgIGMSt-mYrLoM_tbYkzqdO" -O chest_xray.zip && rm -rf /tmp/cookies.txt
Unzip the data
$ ! unzip -qq chest_xray.zip
Details on the dataset
What is Pneumonia?
- It is an infection in one or both lungs.
- It is caused by bacteria, viruses, and fungi.
- Pneumonia is an infection, which causes inflammation in the air sacs in your lungs, called alveoli.
General Symptoms
- Fever
- Chills
- Cough
- Shortness of breath
- Fatigue
What are the different types of Bacterial pneumonia?
- Bacteria cause most cases of community-acquired pneumonia in adults.
- A person can catch pneumonia when someone who is infected coughs or sneezes.
- The bacteria-filled droplets get into the air, where you can breathe them into your nose or mouth.
- It typically exhibits a focal lobar consolidation.
Bacterial Pneumonia as seen on a chest X-ray.

What are the different types of Viral pneumonia
- Viruses are the second most common cause of pneumonia.
- Many different ones cause the disease, including some of the same viruses that bring on colds and flu.
- Fever, Chills, Dry cough, which may get worse and make mucus, Stuffy nose.
- Viral pneumonia (right) manifests with a more diffuse “interstitial” pattern in both lungs.
Viral Pneumonia as seen on chest X-ray

What are the different types of Walking pneumonia
- A less severe form of bacterial pneumonia. Sometimes doctors call it “atypical” pneumonia.
- Symptoms can be so mild that you don’t know you have it. You may feel well enough that you’re able to go about your regular activities, which is where the “walking” in the name comes from.
What are the different types of Fungal pneumonia
- Fungi are a less common cause of pneumonia. You’re not likely to get fungal pneumonia if you’re healthy.
- But you have a higher chance of catching it if your immune system is weakened from a major operation, organ transplant, HIV.
- You get fungal pneumonia by breathing in tiny particles called fungal spores.
Need for such an application
- Bacterial pneumonia requires an urgent referral for immediate antibiotic treatment.
- Viral pneumonia is treated with supportive care. Therefore, an accurate and timely diagnosis is imperative.
- Rapid radiologic interpretation of images is not always available, particularly in the low-resource settings where childhood pneumonia has the highest incidence and highest rates of mortality.
- Thus using transfer learning in classifying pediatric chest X-rays.
Dataset
- Labeled a total of 5,232 chest X-ray images from children.
- Training set includes 3,883 characterized as depicting pneumonia (2,538 bacterial and 1,345 viral) and 1,349 normal, from a total of 5,856 patients.
- The test set includes 234 normal images and 390 pneumonia images (242 bacterial and 148 viral) from 624 patients.
Labels
- Normal x-ray
- Pneumonia x-ray
Quick Prototyping — Training, Validation, and Inferencing
Transfer Learning
Base Network
- A convolutional neural network is first trained on large datasets such as coco or Imagenet.
- These datasets have many classes, like around 1000, 1500 classes.
- Thus the final layer in the neural network has a similar number of neurons.
Finetuning on custom dataset
- A custom dataset usually has a different number of classes.
- You take the network and load the pre-trained weights on the network.
- Then remove the final layer that has the extra(or less) number of neurons.
- You add a new layer with a number of neurons = number of classes in your custom dataset.
- Optionally you can add more layers in between this newly added final layer and the old network.
What is quick prototyping?
- Every image classification projects start with the basic step of trying out a transfer learning.
In transfer learning, you take a deep learning model trained on a very large dataset
- Then train it further on your custom dataset.
While doing this you need to select a lot of hyper-parameters
- First the model itself, like ResNet or DenseNet, you can never be sure what to use.
- Then dataset parameters such as batch size, input shape, etc.
- Then model parameters such as freezing layers, not using pre-trained models, etc.
- Then setting up which optimizer, loss function, a learning rate scheduler, etc to select.
- And finally, the number of epochs to train on.
Note: Not everything can be done at the very first step, thus the quick prototyping mode.
Which allows you to
- Set the model.
- Whether to use a pre-trained network or train from scratch.
- The number of epochs.
All the other parameters are set to default as per their original research papers.
- Then can be changed in Monk’s intermediate and expert modes.
Creating and managing experiments
- Provide a project name.
- Provide an experiment name.
- For specific data create a single project.
- In each project, multiple experiments can be created.
- Every experiment can we have different hyper-parameters attached to it.
$ gtf = prototype(verbose=1);
$ gtf.Prototype("Pneumonia_Classification", "Quick_Prototype");
Output
Mxnet Version: 1.5.0
Experiment Details
Project: Pneumonia_Classification
Experiment: Quick_Prototype
Dir: /home/abhi/Downloads/webinar_2/workspace/Pneumonia_Classification/Quick_Prototype/
This creates files and directories as per the following structure
workspace
U+007C
U+007C----Pneumonia_Classification
U+007C
U+007C
U+007C---Quick_Prototype
U+007C
U+007C--experiment-state.json
U+007C
U+007C--output
U+007C
U+007C------logs
U+007C
U+007C------models
Quick mode training
- Using Default Function
- dataset_path
- model_name
- num_epochs
Dataset folder structure
parent_directory
U+007C
U+007C
U+007C
U+007C----training
U+007C------Infected
U+007C
U+007C------img1.jpg
U+007C------img2.jpg
U+007C------.... (and so on)
U+007C------Normal
U+007C
U+007C------img1.jpg
U+007C------img2.jpg
U+007C------.... (and so on)
U+007C
U+007C
U+007C----validation
U+007C------Infected
U+007C
U+007C------img1.jpg
U+007C------img2.jpg
U+007C------.... (and so on)
U+007C------Normal
U+007C
U+007C------img1.jpg
U+007C------img2.jpg
U+007C------.... (and so on)
Modifiable params
- dataset_path: the path to data
- model_name: which pre-trained model to use
- freeze_base_network: Retrain already trained network or not
- num_epochs: Number of epochs to train for
$ gtf.Default(dataset_path="chest_xray/train",
model_name="resnet18_v1",
num_epochs=5)#Start Training
$ gtf.Train();
Train vs Val vs Test Dataset
Train
- The model sees and learns from this data.
- 80% of the original training data in our case.
Validation
- The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning model hyperparameters.
- 20% of the original training data in our case.
Test
- The test dataset is a dataset used to provide an unbiased evaluation of a final model fit on the training dataset.
- External set.
Running inference on test images
Load the experiment in inference mode
- Set flag eval_infer as True.
$ gtf = prototype(verbose=1);
$ gtf.Prototype("Pneumonia_Classification", "Quick_Prototype", eval_infer=True);
Output
Mxnet Version: 1.5.0
Model Details
Loading model - workspace/Pneumonia_Classification/Quick_Prototype/output/models/final-symbol.json
Model loaded!
Experiment Details
Project: Pneumonia_Classification
Experiment: Quick_Prototype
Dir: /home/abhi/Downloads/webinar_2/workspace/Pneumonia_Classification/Quick_Prototype/
Select image and Run inference
$ img_name = "chest_xray/infer/normal-1.jpeg";
$ predictions = gtf.Infer(img_name=img_name);
#Display
$ from IPython.display import Image
$ Image(filename=img_name)
Output
Prediction
Image name: chest_xray/infer/normal-1.jpeg
Predicted class: NORMAL
Predicted score: 7.098179340362549

$ img_name = "chest_xray/infer/pneumonia-1.jpeg";
$ predictions = gtf.Infer(img_name=img_name);
#Display
$ from IPython.display import Image
$ Image(filename=img_name)
Output
Prediction
Image name: chest_xray/infer/pneumonia-1.jpeg Predicted class: PNEUMONIA
Predicted score: 3.6506881713867188

Train a classifier using Resnet50

Readings on ResNet
Points from Towards Data Science
- The core idea of ResNet is introducing a so-called “identity shortcut connection” that skips one or more layers.
- The deeper model should not produce a training error higher than its shallower counterparts.
- Solves the problem of vanishing gradients as network depth increased.
Points from Medium
- Won 1st place in the ILSVRC 2015 classification competition with a top-5 error rate of 3.57% (An ensemble model).
- Efficiently trained networks with 100 layers and 1000 layers also.
- Replacing VGG-16 layers in Faster R-CNN with ResNet-101. They observed relative improvements of 28%.
Read more here
- https://arxiv.org/abs/1512.03385
- https://d2l.ai/chapter_convolutional-modern/resnet.html
- https://cv-tricks.com/keras/understand-implement-resnets/
- https://mc.ai/resnet-architecture-explained/
ResNet Block — 1

Properties
This block has 2 branches
- The first branch is the identity branch, it takes the input and pushes it as the output, the Residual.
- The second branch has these layers
- batchnorm -> relu -> conv_1x1 -> batchnorm -> relu -> conv_3x3 -> batchnorm -> relu -> conv_1x1.
The branches are added elementwise, so both the branches need to have same sized output.
The final layer of this block is Relu.
The bottleneck
- The num features in first and middle convolutions are input_features/4
- The final convolution has features = input_features.
ResNet Block — 2

Properties
The block has two starting elements
- batchnorm -> Relu
Post the starting elements this block has 2 branches
The first branch has these layers
- conv_1x1
Second branch has these layers
- conv_1x1 -> batchnorm -> Relu -> conv_3x3 -> batchnorm -> Relu -> conv_1x1.
The branches are added elementwise, so both the branches need to have same sized output.
#Set project and experiment
$ gtf = prototype(verbose=1)
$ gtf.Prototype("Pneumonia_Classification", "Experiment_1")#Load data and model
$ gtf.Default(dataset_path="chest_xray/train", model_name="resnet50_v2",freeze_base_network=False, num_epochs=5)# Train
$ gtf.Train()
Train a classifier using Densenet121

Readings on Densenet
Points from Medium
- “This architecture resulted from the desire to improve higher layer architectures that were being developed. Specifically, improving the problem that many of the layers in high-layer networks were in a sense redundant.”
Points from Towards Data Science
- Each layer is receiving a “collective knowledge” from all preceding layers. (See image above).
#Set project and experiment
$ gtf = prototype(verbose=1)
$ gtf.Prototype("Pneumonia_Classification", "Experiment_2")#Load data and model
$ gtf.Default(dataset_path="chest_xray/train", model_name="densenet121",freeze_base_network=False, num_epochs=5)# Train
$ gtf.Train()
Compare Experiments
# Invoke the comparison class
$ from compare_prototype import compare
Creating and managing comparison experiments
- Provide a project name
# Create a project
$ gtf = compare(verbose=1);
$ gtf.Comparison("Exp_1_vs_2")
Output
Comparison: - Exp_1_vs_2
Add the experiments
- First argument — Project name
- Second argument — Experiment name
$ gtf.Add_Experiment("Pneumonia_Classification", "Experiment_1")
$ gtf.Add_Experiment("Pneumonia_Classification", "Experiment_2")
Output
Project - Pneumonia_Classification, Experiment - Experiment_1 added Project - Pneumonia_Classification, Experiment - Experiment_2 added
Run Analysis
$ gtf.Generate_Statistics()
This creates files and directories as per the following structure
workspace
U+007C
U+007C--------comparison
U+007C
U+007C
U+007C-----Exp_1_vs_2
U+007C
U+007C------stats_best_val_acc.png
U+007C------stats_max_gpu_usage.png
U+007C------stats_training_time.png
U+007C------train_accuracy.png
U+007C------train_loss.png
U+007C------val_accuracy.png
U+007C------val_loss.png U+007C
U+007C-----comparison.csv (Contains necessary details of all experiments)
Training Accuracy Curves

Training Loss Curves

Validation Accuracy Curves

Validation loss curves

Training time curves

Max GPU usages

Best Validation accuracies
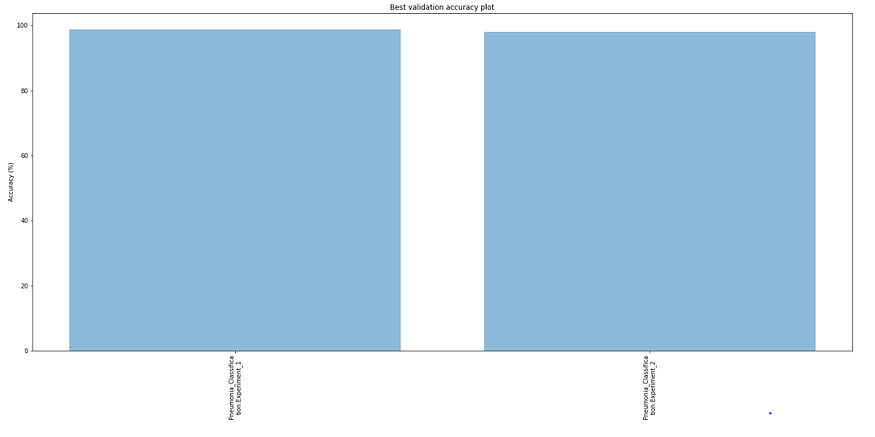
Both worked equally well on the validation data
Let’s check the performance on the test set
ResNet
gtf = prototype(verbose=1);
gtf.Prototype("Pneumonia_Classification", "Experiment_1", eval_infer=True);
# Load test data
gtf.Dataset_Params(dataset_path="chest_xray/test");
gtf.Dataset();
# Test for accuracy
accuracy, class_based_accuracy = gtf.Evaluate();
Output
Mxnet Version: 1.5.0
Model Details
Loading model - workspace/Pneumonia_Classification/Experiment_1/output/models/final-symbol.json
Model loaded!
Experiment Details
Project: Pneumonia_Classification
Experiment: Experiment_1
Dir: /home/abhi/Downloads/webinar_2/workspace/Pneumonia_Classification/Experiment_1/
Dataset Details
Test path: chest_xray/test
CSV test path: None
Dataset Params
Input Size: 224
Processors: 4
Pre-Composed Test Transforms
[{'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]
Dataset Numbers
Num test images: 624
Num classes: 2
TestingHBox(children=(IntProgress(value=0, max=624), HTML(value='')))Result
class based accuracies
0. NORMAL - 55.55555555555556 %
1. PNEUMONIA - 98.2051282051282 %
total images: 624
num correct predictions: 513
Average accuracy (%): 82.21153846153845
DenseNet
$ gtf = prototype(verbose=1);
$ gtf.Prototype("Pneumonia_Classification", "Experiment_2", eval_infer=True);
# Load test data
$ gtf.Dataset_Params(dataset_path="chest_xray/test");
$ gtf.Dataset();
# Test for accuracy
$ accuracy, class_based_accuracy = gtf.Evaluate()
Output
Mxnet Version: 1.5.0
Model Details
Loading model - workspace/Pneumonia_Classification/Experiment_2/output/models/final-symbol.json
Model loaded!
Experiment Details
Project: Pneumonia_Classification
Experiment: Experiment_2
Dir: /home/abhi/Downloads/webinar_2/workspace/Pneumonia_Classification/Experiment_2/
Dataset Details
Test path: chest_xray/test
CSV test path: None
Dataset Params
Input Size: 224
Processors: 4
Pre-Composed Test Transforms
[{'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]
Dataset Numbers
Num test images: 624
Num classes: 2
TestingHBox(children=(IntProgress(value=0, max=624), HTML(value='')))Result
class based accuracies
0. NORMAL - 62.39316239316239 %
1. PNEUMONIA - 98.71794871794873 %
total images: 624
num correct predictions: 531
Average accuracy (%): 85.09615384615384
Densenet performed better in this case on test set
You can find the complete jupyter notebook on Github. Give us ⭐️ on our GitHub repo if you like Monk.
If you have any questions, you can reach Abhishek and Akash. Feel free to reach out to them.
I am extremely passionate about computer vision and deep learning in general. I am an open-source contributor to Monk Libraries.
You can also see my other writings at:
Akula Hemanth Kumar – Medium
Read writing from Akula Hemanth Kumar on Medium. Computer vision enthusiast U+007CLinkedin…
medium.com

Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts

")





