



Market Basket Analysis for Retail Growth
Last Updated on July 21, 2023 by Editorial Team
Author(s): Saif Ali Kheraj
Originally published on Towards AI.
Data Analytics
These statistics reveal that by 2023 e-commerce sales will reach 6.5 trillion dollars. Not only E-Commerce but also we see a rise in retail transactions at Point of Sale terminals. Given this market size, it is vital to utilize retail transactional data to innovate in new areas. Based on retail trends, we expect different innovations, such as personalization in improving customer experience. Onsite personalization is one of the goals for most retailers throughout the world.
This article will discuss “Market Basket Analysis” used by large retailers to understand associations between items.

You may have seen in different e-commerce sites “Customers who bought this item also bought.” This approach quantifies complementary and supplementary relationships between items.
IF { bread, biscuit} THEN {milk}
Retail transactional data is a rich source of information generated at the Point of Sale Terminal. This information, when used intelligently, can help the company increase its revenue through cross-promotion and pricing. Not only this point, but retailers can also improve Customer Experience using different promotional strategies to convince their customers to spend more time in their store. Now the question is how we could use market basket analysis to increase the time within the store. We could use this and optimization techniques to maximize the walking distance of a customer. This strategy would enable the customer to keep buying products together. Usually, in stores, products are placed according to function, but if we harness the data intelligently based on the historical transaction, we can layout products in a manner that can increase the overall distance of a customer. This move will lead to a better customer experience and shopping behavior.
This article will focus on Market Basket Analysis where we will create association rules between products. For example, using historical data, we can identify that milk and bread are purchased together. But whether the store should use milk to promote bread or bread to promote milk.
Overview
It is vital to know concepts before we implement them. Retailer, of course, needs to know that we have enough evidence of a rule.
Support: It is the popularity of an item. For example, out of 500 transactional records, milk appeared 200 times. Then the popularity of milk would be calculated as 200/500=0.4. In simple words, it is the ratio of transactions containing milk to the total number of transactions. We can calculate the support of multiple products similarly.


Using support metric, we can build frequent itemsets meaning itemsets frequently occurring together, but it does not tell us about the association rules(IF Y then Z)
2. Confidence: This metric is for finding out the relationship between itemsets and indicates the confidence level of a relationship. For example, from the support, we know that milk and coffee are frequently purchased together, but whether the store should use milk to promote coffee or coffee to promote milk. This is where confidence comes in.
In the mathematical term:

Here we are calculating the confidence of IF A then C.
We will refer item on the left side (A) as antecedent and the item on the right side(C) as consequent.
This simple formula indicates the probability of seeing a consequent in a transaction given that it also contains an antecedent.
Lift: It measures how much more often A and C occur together than we would expect at random. Therefore lift value checks if this relationship is better than the random or not.

Interpretation

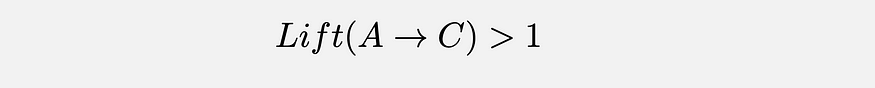
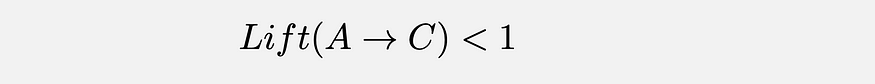
Leverage: This metric is similar to the lift, but it is easier to interpret. The threshold for determining good rules is 0. If you check the formula here, we can see that the formula takes the difference between A and C occurring together and the probability of A and C were independent.

These concepts are important to perform market basket analysis, but there are even more concepts like Conviction and Zhang Metric. Zhang is an important metric that tells us about disassociation and the association of items. It lies between -1(perfect disassociation) and 1(perfect association). We won’t discuss all of this in detail.
Overview of Apriori Algorithm
Now that we know all the concepts, you might be thinking about how would we calculate association rules of thousands of items. For example, if you have 10000 items, the total possible combinations would be 2¹⁰⁰⁰⁰ > 10⁸² (# of atoms in the universe). It would be impossible to calculate given the machine capacity. This is where the Apriori Algorithm comes in.
Apriori algorithm prunes the number of rules by checking minimum support. For example, if item A is infrequent(using minimum support threshold), all item A combinations are ignored. This algorithm will, therefore, save time and effort.
Implementation:
Retail Dataset: https://www.kaggle.com/heeraldedhia/groceries-dataset
We will use mlxtend library to implement market basket analysis.
Import the data
import pandas as pd
df = pd.read_csv("Groceries_dataset.csv",error_bad_lines=False)
df.head()
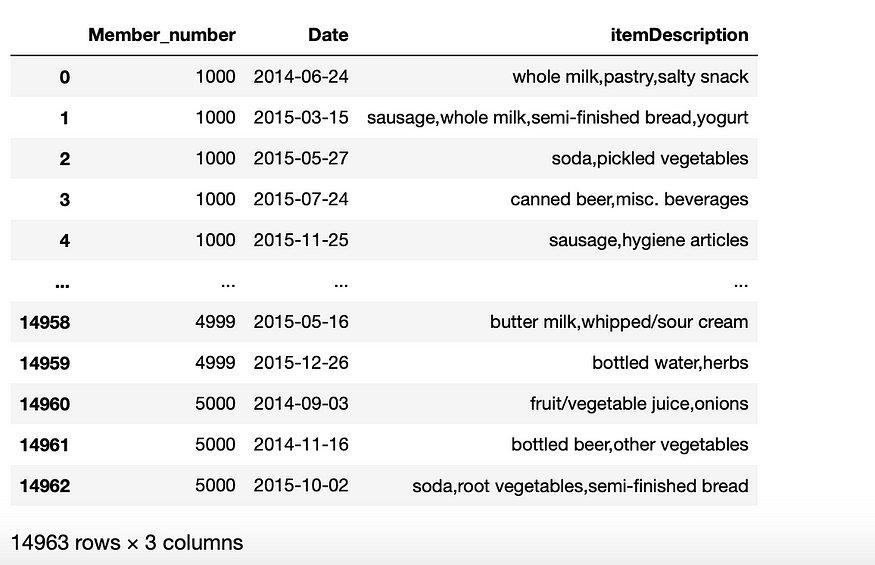
We can see right over here that the data contains retail transactions.
Exploratory Data Analysis
- Plot Absolute Frequency
import matplotlib.pyplot as plt
%matplotlib inlineplt.figure(figsize=(25,10))
grouped = df[['itemDescription']].groupby('itemDescription').size()
grouped.sort_values(ascending=False).plot(kind='bar')
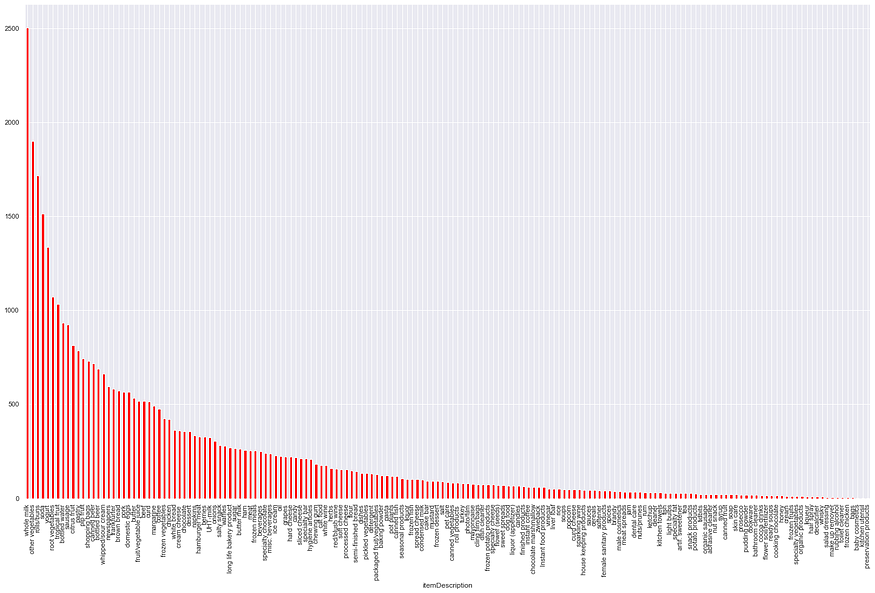
As we can see right over here that whole milk is the most popular item in the store while processed product is the least favorite item. Similarly, we can find out the top and least favorite using simple EDA.
- Plot Relative Frequency
rel_freq=df['itemDescription'].value_counts() / len(df)
rel_freq.sort_values(ascending=False).plot(kind='bar',color='red')

- TreeMap and Word Cloud
Treemap visualizes a very large amount of data in a hierarchically structured diagram where the size of the rectangles organized from largest to smallest.
import squarify
plt.figure(figsize = (100, 70))
squarify.plot(sizes = df.itemDescription.value_counts().values, alpha = 0.7,
label = df.itemDescription.unique(), text_kwargs={'fontsize':50})
plt.title('Item Description', fontsize = 20)
plt.axis('off')
plt.show()
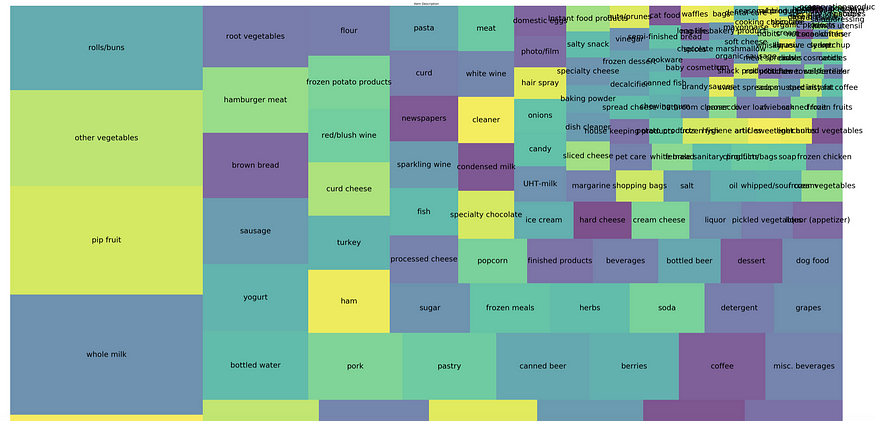
This really looks interesting and we can see that items like whole milk, pip fruit, other vegetables, rolls/buns outweigh other products.
from wordcloud import WordCloud
plt.subplots(figsize=(100,70))
wordcloud = WordCloud(background_color = 'white',
width=500,
height=300).generate(','.join(df['itemDescription']))plt.imshow(wordcloud)
plt.axis('off')

- Transactions per month
df['Date']=df['Date'].astype('datetime64[ns]')df["Year_Months"]=pd.to_datetime(df['Date'].dt.year.astype('str')+"-"+df['Date'].dt.month.astype('str')).dt.to_period('M')df[["Year_Months"]].groupby("Year_Months").size().plot(kind='bar',color='green')

The highest # of transactions happened during January and August 2015. We can explore it further as well.
You can perform different analysis as well on this dataset including Top sellers, Distribution of # of items per member to get an idea. I will leave this for you.
Data Preparation for Market Basket Analysis
- Group items bought together by the same customer on the same date
df_dataprep_st1=df.groupby(['Member_number','Date'])['itemDescription'].apply(','.join).reset_index()
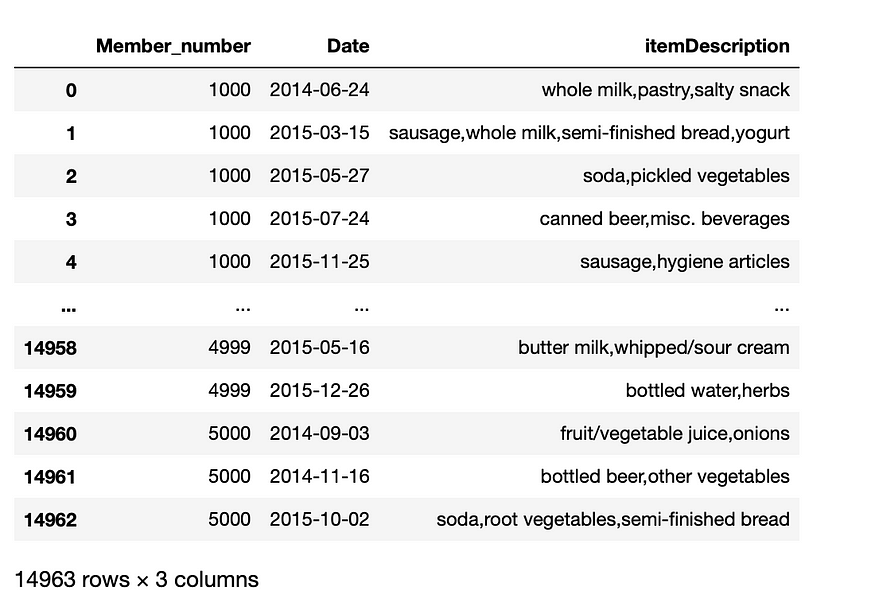
Now we can see that we have a list of items for the same customers on the same date.
- Convert itemsets to 2D Array (Needed as an input to the algorithm for preprocessing)
itemsets=df_dataprep_st1[['itemDescription']].values
itemsets=[(''.join(i).split(",")) for i in itemsets]

3. Convert to one-hot using Mlxtend Transaction Encoder
Mlxtend expects one-hot data as an input so we need to convert data into a one-hot format.
from mlxtend.preprocessing import TransactionEncoderte = TransactionEncoder()
te_ary = te.fit(itemsets).transform(itemsets)
df_onehot = pd.DataFrame(te_ary, columns=te.columns_)
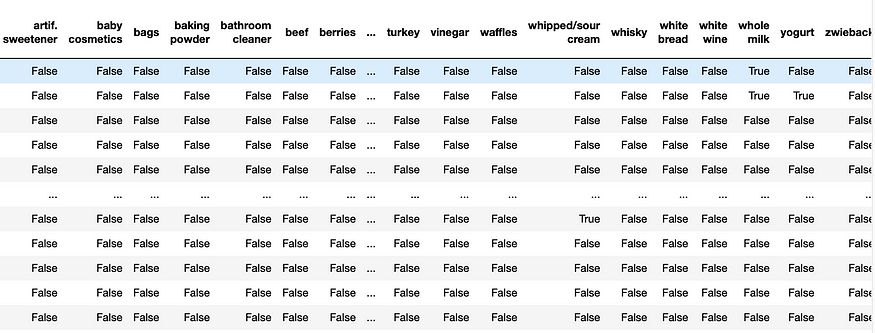
Mining Frequent Itemsets and Association Rules
Let us first analyze for different support and confidence levels.
supportLevels =[0.01,0.009,0.007,0.005,0.003,0.001]
confidenceLevels=[1,0.9,0.8,0.7,0.6,0.5, 0.4, 0.3, 0.2, 0.1,0.05,0.03,0.01,0.001]dict_lengths={}
for min_support in supportLevels:
frequent_itemsets = apriori(df_onehot, min_support=min_support, use_colnames=True)
#length_frequent_itemsets.append(len(frequent_itemsets))
#print(min_support)
conf_len_rules=[]
for min_confidence in confidenceLevels:
rules = association_rules(frequent_itemsets, metric = "confidence",min_threshold = min_confidence)
print(min_confidence,len(rules))
conf_len_rules.append( (min_confidence, len(rules)) )
#print(conf_len_rules)
plt.plot([i[0] for i in conf_len_rules],[i[1] for i in conf_len_rules],label="Support"+str(min_support))
plt.legend(loc="upper right")
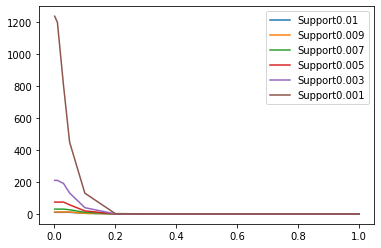

Support level of 1%: We can only find few rules with low confidence levels. We cannot really choose this support value.
Similarly, for lower supports as you can see on the graph, we have many rules to analyze.
Frequent Itemsets
frequent_itemsets = apriori(df_onehot, min_support=0.001, use_colnames=True)
frequent_itemsets['length'] = frequent_itemsets['itemsets'].apply(lambda x: len(x))

We now have 750 frequent itemsets using minimum support of 0.001. In this way, we applied Apriori Algorithm with the use of mlxtend library.
Association Rules
rules = association_rules(frequent_itemsets, metric="confidence", min_threshold=0.02)
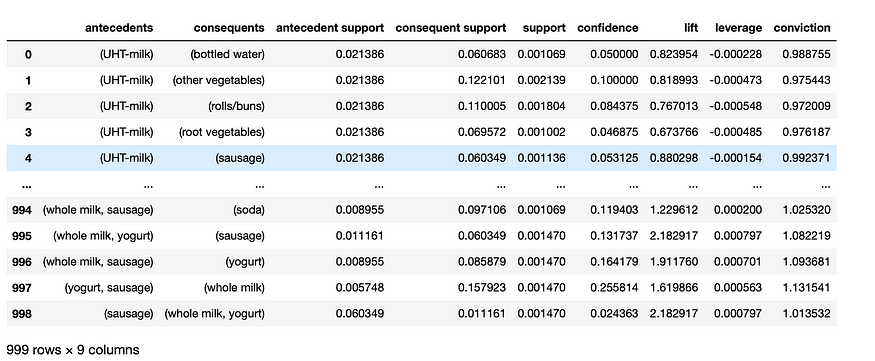
We applied a confidence threshold of 0.02 to get 999 rules from our frequent sets. You can now see all the metrics we discussed along with the rules.
Further Filtering
rules=rules[rules['lift']>1].reset_index(drop=True)

Now we are only left with 189 rules for further analysis.
We can also spot the most correlated rule which is if {sausage} then {whole milk, yogurt}. Let's check using heatmap visualization and validate our results.
Post Analysis
- Heatmap
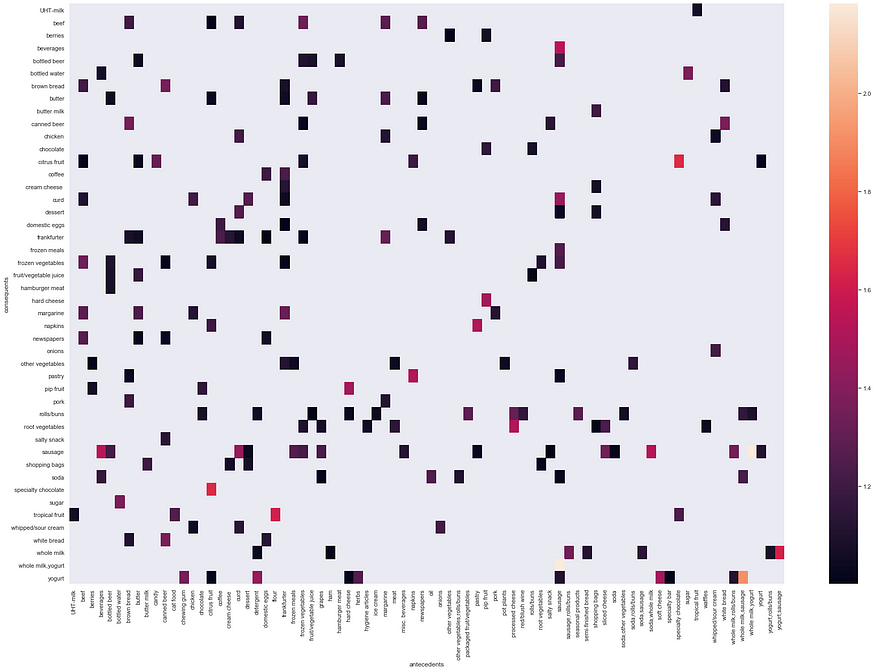
As you can see right over here different correlation of rules. From this Exploratory analysis, we can easily find that if {sausage} then {whole milk, yogurt} is a good rule to start with. Please also find other such rules as an exercise.
- Confidence/Support Scatterplot
rules = association_rules(frequent_itemsets, metric = "confidence",min_threshold = 0.0)
sns.set(rc={'figure.figsize':(10,10)})
sns.scatterplot(x = "support", y = "confidence",
size = "lift", data = rules)
plt.show()
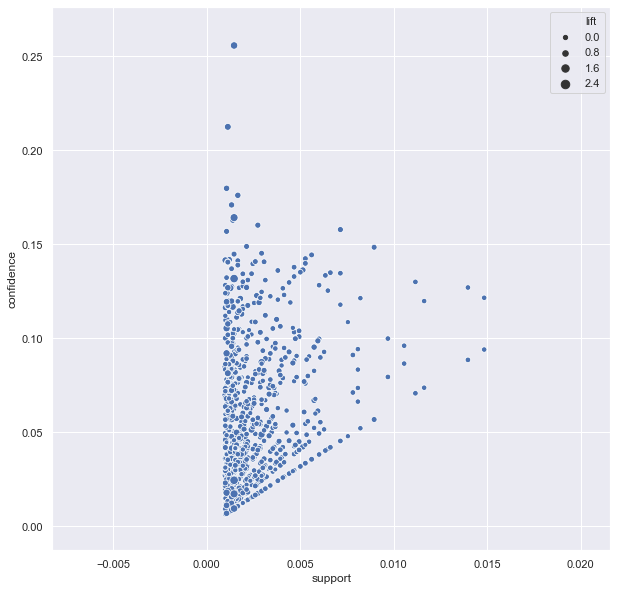
Research shows that optimal rules lie on support/confidence boundary. If you look at this plot, you will notice that lift is always high at the support/confidence border.
Conclusion
In this article, we discussed the importance of market basket analysis given the huge market size. We discussed important metrics like support, confidence, lift, leverage for identifying the relationship between itemsets. Then we moved on to the implementation part to see how easy it is to implement all this.
References
[1] http://www.laccei.org/LACCEI2016-SanJose/RefereedPapers/RP307.pdf
[2] http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/association_rules/
[3] https://github.com/datacamp/Market-Basket-Analysis-in-python-live-training
[4] http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/apriori/
[5] https://www.kaggle.com/herozerp/viz-rule-mining-for-groceries-dataset
[6] https://select-statistics.co.uk/blog/market-basket-analysis-understanding-customer-behaviour/
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

