


")
Review: DCNv2 — Deformable ConvNets v2 (Object Detection & Instance Segmentation)
Last Updated on July 20, 2023 by Editorial Team
Author(s): Sik-Ho Tsang
Originally published on Towards AI.
Enhanced DCN / DCNv1, More Deformable, Better Results
In this article, Deformable ConvNets v2 (DCNv2), by the University of Science and Technology of China and Microsoft Research Asia (MSRA), is reviewed. In this paper, DCNv2 enhanced DCNv1, which was published in 2017 ICCV, by introducing one more modulation module to modulate the input feature amplitudes from different spatial locations/bins. And it is published in 2019 CVPR with over 100 citations. (
Sik-Ho Tsang @ Medium)
Outline
- Brief Review of DCNv1
- Modulated Deformable Modules in DCNv2
- R-CNN Feature Mimicking
- Some Analyses
- Experimental Results
1. Brief Review of DCNv1
1.1. Deformable Convolution

- Regular convolution is operated on a regular grid R.
- Deformable convolution is operated on R but with each point augmented by a learnable offset ∆pn.
- Convolution is used to generate 2N number of feature maps corresponding to N 2D offsets ∆pn (x-direction and y-direction for each offset).

- As shown above, the deformable convolution will pick the values at different locations for convolutions conditioned on the input image or feature maps.
1.2. Deformable RoI Pooling

- Regular RoI pooling converts an input rectangular region of arbitrary size into fixed-size features.
- In Deformable RoI pooling, firstly, at the top path, we still need regular RoI pooling to generate the pooled feature map.
- Then, a fully connected (fc) layer generates the normalized offsets ∆p̂ij and then transformed to offset ∆pij (equation at the bottom right) where γ=0.1.
- The offset normalization is necessary to make the offset learning invariant to RoI size.
- Finally, at the bottom path, we perform deformable RoI pooling. The output feature map is pooled based on regions with augmented offsets.
2. Modulated Deformable Modules in DCNv2
2.1. Modulated Deformable Convolution in DCNv2
- In DCNv2, each sample not only undergoes a learned offset (DCNv1) but is also modulated by a learned feature amplitude. The network module is thus given the ability to vary both the spatial distribution and the relative influence of its samples.

- Δmk is the modulation scalar for the k-th location. (K is the number of locations within the convolution grid.)
- The modulation scalar Δmk lies in the range of [0,1].
- Both Δpk and Δmk are obtained via a separate convolution layer applied over the same input feature maps x.
- This convolutional layer is of the same spatial resolution and dilation as the current convolutional layer.
- The output is of 3K channels, where the first 2K channels correspond to the learned offsets Δpk, and the remaining K channels are further fed to a sigmoid layer to obtain the modulation scalars Δmk.
2.2. Modulated Deformable RoI Pooling in DCNv2

- Similarly, in RoI pooling, Δmk is added to modulate the amplitude of the input feature values at a learned offset position.
3. R-CNN Feature Mimicking
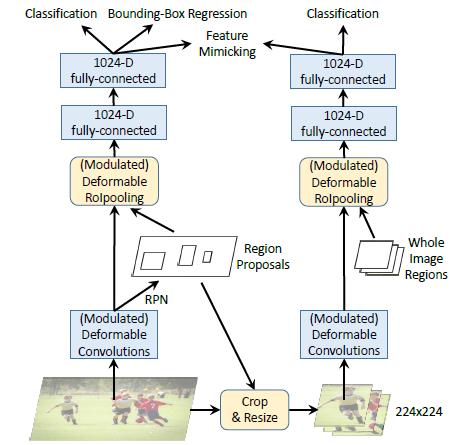
- A feature mimic loss is incorporated on the per-RoI feature of Deformable Faster R-CNN to force them to be similar to R-CNN features extracted from cropped images.
- This auxiliary training objective is intended to drive Deformable Faster R-CNN to learn more “focused” feature representations like R-CNN.
- The feature mimic loss is defined on the cosine similarity between the features of R-CNN and the features of Faster R-CNN:

- Network training is driven by the feature mimic loss and the R-CNN classification loss, together with the original loss terms in Faster R-CNN. The loss weights of the two newly introduced loss terms are 0.1 times those of the original Faster R-CNN loss terms.
- In inference, only the Faster R-CNN network is applied on the test images, without the auxiliary R-CNN branch. Thus, no additional computation is introduced by R-CNN feature mimicking in inference.
4. Some Analyses

- Effective sampling locations: The sampling locations by the convolution.
- Effective receptive field: Not all pixels within the receptive field of a network node contribute equally to its response. The differences in these contributions are represented by an effective receptive field, whose values are calculated as the gradient of the node response with respect to intensity perturbations of each image pixel.
- Error-bounded saliency regions: The response of a network node will not change if we remove image regions that do not influence it, as demonstrated in recent research on image saliency. Based on this property, we can determine a node’s support region as the smallest image region giving the same response as the full image, within a small error bound.
- The spatial support of the enriched deformable modeling in DCNv2 exhibits better adaptation to image content compared to that of DCNv1.
5. Experimental Results
5.1. Modulated Deformable Conv & Modulated Deformable RoI Pooling

- Faster R-CNN and Mask R-CNN with ResNet-50 are used as a baseline as shown above.
- With only regular conv, Faster R-CNN: 32.1% AP for the object detection task. And Mask R-CNN: 32.2% AP for instance segmentation task.
- With deformable conv in DCNv1 applied in conv5, and aligned RoI pooling used in Mask R-CNN, Faster R-CNN: 38.0% AP, and Mask R-CNN: 35.3% AP.
- With modulated deformable conv in DCNv2 applied in conv3 to conv5, and modulated deformable RoI pooling, Faster R-CNN: 41.7% AP, and Mask R-CNN: 37.3% AP.
5.2. R-CNN Feature Mimicking

- With only concerning the features of the foreground object for feature mimicking loss, it obtains the highest AP.
5.3. Backbone Variants

- With a deeper and better backbone such as ResNeXt, higher AP is obtained.
5.4. ImageNet Image Classification Task
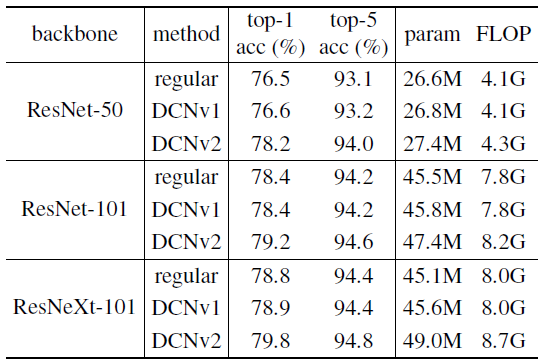
- The authors also tried the ImageNet image classification task.
- DCNv2 achieves noticeable improvements over both the regular and DCNv1 baselines, with minor additional computation overhead.
References
[2019 CVPR] [DCNv2]
Deformable ConvNets v2: More Deformable, Better Results
Object Detection
[OverFeat] [R-CNN] [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net] [CRAFT] [R-FCN] [ION] [MultiPathNet] [NoC] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [G-RMI] [TDM] [SSD] [DSSD] [YOLOv1] [YOLOv2 / YOLO9000] [YOLOv3] [FPN] [RetinaNet] [DCN / DCNv1] [DCNv2]
Instance Segmentation
[SDS] [Hypercolumn] [DeepMask] [SharpMask] [MultiPathNet] [MNC] [InstanceFCN] [FCIS] [Mask R-CNN] [DCNv2]
My Other Previous Reviews
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts






")