



Disentangled Representation Learning for Non-Parallel Text Style Transfer
Last Updated on July 20, 2023 by Editorial Team
Author(s): Anchit Bhattacharya
Originally published on Towards AI.
Paper Summary
Vineet John, Lili Mou, Hareesh Bahuleyan, Olga Vechtomova
Disentangling hidden layers of a neural network give us more control and understanding of a neural network
In this article, I am going to explain the work done in the paper Disentangled Representation Learning for Non-Parallel Text Style Transfer[1] and explain some core ideas from that paper, in an easy to understand manner. This paper was presented in ACL 2019, which is one of the leading conferences in the field of Machine Learning.
There are two critical components in the title of the paper, and I will explain each of them intuitively before I proceed to the actual contents of the paper. The two components are Disentanglement Representation Learning and Non-Parallel Text Style Transfer.
Disentanglement Representation Learning
Imagine an autoencoder, where you pass in some data and reconstruct the data back with some lower-dimensional hidden layer in between. This lower-dimensional representation is often called a latent vector, which learns the data representation in a lower-dimensional space, and can be used to generate back the original input data. Now, in a normal autoencoder, the latent vector consists of all the information required to generate the original data, but what if we want to separate specific properties of the input data in certain parts of the latent vector representation. E.g. , If the latent representation is a vector of size 128, we want the first 120 components of the vector to store information about the content of the input data and the last eight components to store information about the style. Note that the content and style of the data can be anything and is determined by how we define them. We will talk about the definition of both these things in later sections of the paper. At this point, what is most important is to understand what disentanglement means, and to get a better understanding, let’s look at a visual representation of what I just explained.

In the figure above, we see a Vanilla Autoencoder, which takes in an input sentence, compressed it to a latent space, and tries to reconstruct the original sentence. But we can also see, that the latent vector is divided into two space:- the style space denoted by s, which is supposed to capture the style information of the sentence(one possible style can be the sentiment of the sentence), and the content space denoted by c, which is supposed to capture the content information of the sentence.
Key Question:- The question we want to answer at this point is how can we train the autoencoder, to be able to separate the style space and the content space in the latent vector representation?
But before we go into the solution, let’s talk about our second component(Non-Parallel Text Style Transfer) quickly, and get an understanding of how disentangling the latent space will help in Text Style Transfer.
Non-Parallel Text Style Transfer
In this section, we see there are two sub-components:- Text Style Transfer and Non-parallel. We will look at each of them separately.
Text Style Transfer
Text Style transfer refers to generating text from a certain input text, having the same content as the input text(basically talking about the same thing as the input text) but having a different style. An obvious example treating the sentiment of the text as the style would be generating negative reviews about a restaurant given a positive review as input text, as shown below.
Input text — the food is excellent and the service is exceptional(positive)
Output text — the food was a bit bad but the staff was exceptional(negative)
Non-parallel data
This component refers to the type of data accessible to the text style transfer system and can be categorized as parallel data and non-parallel data.
Parallel data is when we have access to paired data, where the input text of a certain style is directly mapped to the text of a different style and is accessible to the style transfer system. One classic example is a Machine Translation system, which has access to text from two different languages mapped to each other.
Non-parallel data is when we just have an input text but no mapping from this text to a possible text of a different style.
In our scenario, we don’t have access to parallel data, and that’s the primary reason we are even looking to disentangle the latent space in terms of properties.
How does disentanglement help in Non-parallel text style transfer?
As we don’t have access to paired data mapping from one style to another, we need disentanglement to separate the latent space into the content and style. If we can achieve that, then from an input text, now we have a latent vector representation separated into a content vector and a style vector. To generate a style transferred text the only thing we need to do is to create a new latent vector having the same content vector of the input text, and a new style vector based on our target style, and then use this latent vector to generate our output text.
Now that we have established the different components related to the problem let’s proceed to the actual task of obtaining the disentangled latent vector representation.
Method
Finally, we are here. Ready to dive into the solution, but let’s take a moment to quickly look at the key question again, which is — how can we train the autoencoder, to be able to separate the style space and the content space in the latent vector representation?
Taking the example of the style space and content space, there are two components that we want at the end of this, and each of them has two identical steps with minor changes.
1. Style Information in style space s — Enforce style information in style space s(Step 1), and remove any style information from content space c. (Step 2)
2. Content Information in content space c — Enforce content information in content space c (Step 1) and remove any content information from style space s. (Step 2)
I will describe each of these steps in terms of the first component, and then talk about the changes to perform the steps for component 2.
Step 1 — Multitask Training for Style Information
Goal:- To ensure the style information is contained in style space s.
In this step, we design a neural network(say network A)that takes the style space s of the latent representation and tries to predict the style of the text. So, mathematically it looks like
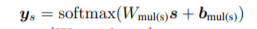
While training this network, we train the encoder parameters along with it, so that it learns the style space of the latent representation in a way which helps network A to be able to predict the style correctly. This entire concept can be encapsulated in the given loss fn:-

So, in essence, we train the encoder parameters to minimize Equation 2, along with the normal reconstruction loss of the autoencoder given by:-

So as we are training the autoencoder and network A simultaneously, it is a form of Multitask training paradigm.
Step 2 — Adversarial Training for Style Information
Goal:- To ensure that the content space c doesn’t have any style information.
Similar to step 1, we design a new neural network(we will call it discriminator), which now predicts the style information, but not from the style space s, but the content space c as the input. Mathematically, the neural network looks like:-

Note:- Contrary to step 1; we don’t train the neural network and the encoder parameters together.
Once, the discriminator is trained, the encoder treats the discriminator as its adversary(as it doesn’t want the discriminator to be able to infer style information from content space), and trains the encoder parameters to make it harder for the discriminator, as denoted by the following loss function:-

In the loss function above, the encoder parameters are trained so that the learned content space maximizes the entropy of the learned discriminator in predicting the style information from the content space.
So at this point, we have a latent representation that has style information stored in space s, and content space c doesn’t have any style information.
Similarly, we need a content space c that stores the content information and a style space s which doesn’t have any content information.
We follow the earlier two-step process, but now we change the input as the content space(c) instead of the style space, and the network tries to predict content information instead of style information. The changes result in the following loss functions for Step 1 and 2:-




Overall Training Process
Putting everything together from above, what we have is a single loss function consisting of the autoencoder reconstruction loss, multitask loss for style space, the adversarial loss for style space, multitask loss for content space, the adversarial loss for content space. Mathematically, which translates to:-
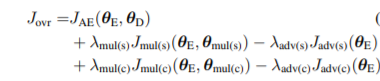
How to decide Style and Content?
Now that we have put forward the training process, which is the core of the methodology, let’s look at how we can define style and content. Actually, it’s entirely up to you how you define these problems, but let me show you how the author of the paper defines these two things.
Style
In this paper, style is defined as the sentiment of the text, which is already labeled in the input data.
Content
This is a trickier part, as there is no clear definition of what content really means. To this end, the author proposes a Bag of Words Feature for each sentence, which calculates the ratio of the number of content words in the sentence to the total number of words in that sentence. The content words are all words, excluding stopwords and style-specific words.
Visualizing the style space and content space
Once we train the system and learn the content space and style space, one way to be sure whether the latent representation is disentangled properly is to plot the tSNE of the content space and style space. The tSNE plot provided in the paper is shown below.

From the figure, we see that positive and negative sentiment data is clearly separated in the style space but not so in the content space, which is what we aimed for.
Another, important observation from the figure is that if we use traditional neural network-based deterministic autoencoder the latent space is not so smooth and continuous as evident from lots of empty space between data points of the plot, whereas if we use Variational Autoencoder we see that the latent space is smooth and continuous.
Conclusion
I hope in this article. I can provide good insights on what disentanglement means in terms of the latent representation and how it can be used for text style transfer. I also discussed a methodology proposed to obtain this in one of the many papers in the field of Text Style Transfer. To find more papers on Text Style transfer, you can follow this link.
References
[1] Vineet John, Lili Mou, Hareesh Bahuleyan, and Olga Vechtomova. 2018. Disentangled representation learning for text style transfer. arXiv preprint arXiv:1808.04339.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts




")

