



Amazon Lex: Conversations in the Cloud
Last Updated on January 5, 2023 by Editorial Team
Author(s): ThinkPro Systems
Originally published on Towards AI the World’s Leading AI and Technology News and Media Company. If you are building an AI-related product or service, we invite you to consider becoming an AI sponsor. At Towards AI, we help scale AI and technology startups. Let us help you unleash your technology to the masses.
A conversational interface is the way of the future. Nothing can beat the user experience of a user talking to your application. Any amount of color optimization and responsive design on a website or mobile app is trivial when it is compared to the experience of a conversation.
Naturally, such a conversation is difficult to implement. However, it is not so difficult either. We have an array of tools and utilities to help us construct the chatbots as per our requirements. This blog introduces you to Amazon Lex, covering the following topics:
- Introduction — What is Lex?
- Core concepts
- Create a bot — a simple bot
- Improving the bot
- Lex vs. ChatGPT — Utility, customization, and integration
Introduction
Amazon Lex is a service provided by Amazon Web Services (AWS) that enables users to build and deploy chatbots for use in a variety of applications. These chatbots, also known as conversational interfaces, allow users to interact with a system or service through natural language input and output.
One of the key benefits of Amazon Lex is its integration with other AWS services. This allows users to leverage the power of the AWS ecosystem to build and deploy their chatbots. For example, Amazon Lex chatbots can be integrated with Amazon Connect, a cloud-based contact center service, to provide customer service through a chatbot interface.
In addition to its integration with other AWS services, Amazon Lex also offers a variety of features to help users build and deploy high-quality chatbots. These features include:
- Automatic speech recognition (ASR): Amazon Lex uses ASR to recognize spoken input from users and translate it into text. This allows users to speak to their chatbot as they would to a human, making the chatbot experience more natural and intuitive.
- Natural language understanding (NLU): Amazon Lex uses NLU to understand the meaning and context of user input. This allows the chatbot to respond appropriately to user requests and requests for information.
- Text-to-speech (TTS): Amazon Lex offers TTS capabilities, allowing chatbots to speak to users in a natural, human-like voice. This can be particularly useful for applications such as customer service or information kiosks.
- Customization: Amazon Lex allows users to customize their chatbots through the use of Amazon Lex ML models and AWS Lambda functions. This enables users to tailor their chatbots to their specific needs and build in custom logic and functionality.
Overall, Amazon Lex is a powerful tool for building and deploying chatbots for a variety of applications. Its integration with other AWS services and extensive customization options make it an ideal choice for users looking to build conversational interfaces for their business or service.
Core concepts
Before we get into implementation, we should understand a few important concepts involved in building chatbots.
Intents
An intent represents the intention of the end user — what does the user want? The primary task of the chatbot is to try and guess this intent and map it with the intents it is programmed to process.
Utterances
The chatbot tries to guess the intent based on the utterances of the user. These are spoken or typed phrases in the user input. The chatbot tries to relate them with the utterances configured for each of its known intents, to identify the current intent.
Slots
The intent alone is not enough. The chatbot needs specific details related to the intent so that it can work on it. These details should be identified from the user’s input. We call them slots. They are specific words and phrases that appear in the long sentences that the user utters.
Fulfillment
This is the actual mechanism for your intent. Once the intent and the slots are identified, the chatbot invokes the fulfillment mechanism that we have configured.
Note that the utterances, intents, and slots come in free-flowing text from the user. They do not have a fixed format or sequence. Here, we cannot use the traditional techniques of text matching or regular expressions. We need intense NLP using trained models to get these details. That is why we need Amazon Lex.
With Lex, we have readymade models that help us with these tedious tasks. We just configure the basics and it takes care of the rest.
Create a bot
With the basic theoretical understanding, let us now implement a simple bot using Amazon Lex. Let us create a chatbot that can tell us the latest news related to a given keyword. It is a simple process that involves a few core concepts. Let us check it out.
Jump to the Amazon Lex Console.
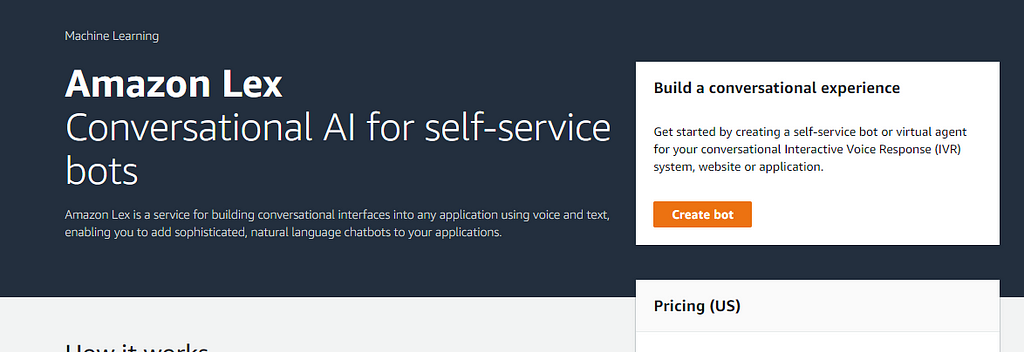
Click on “Create bot” to start the process. The configuration is straightforward.
- We will start with the blank bot
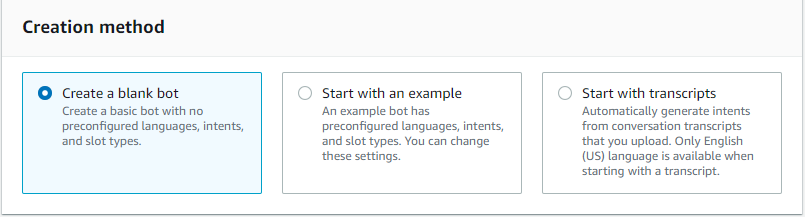
- Provide a name and optional description to identify the bot
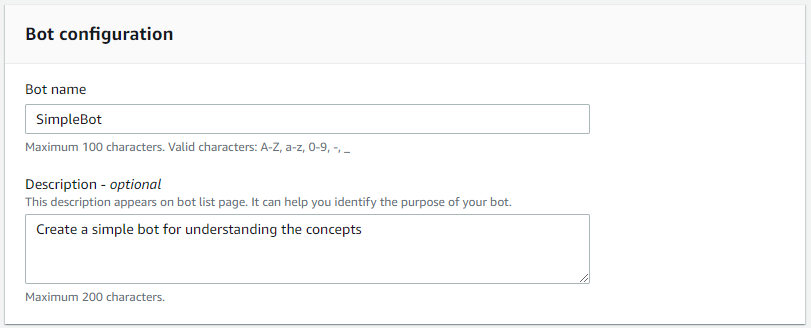
- Let AWS take care of creating the IAM Roles
- We need not worry about the COPPA in the tutorial
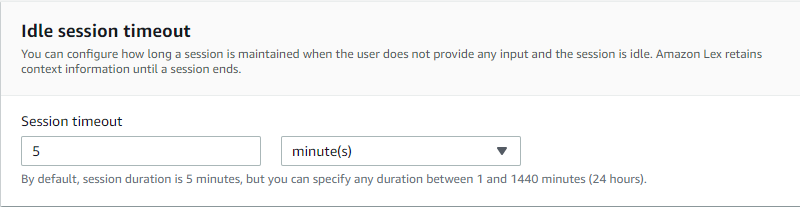
- We should be good with a 5-minute session timeout.
- To start with, let us focus on text interaction in US English.
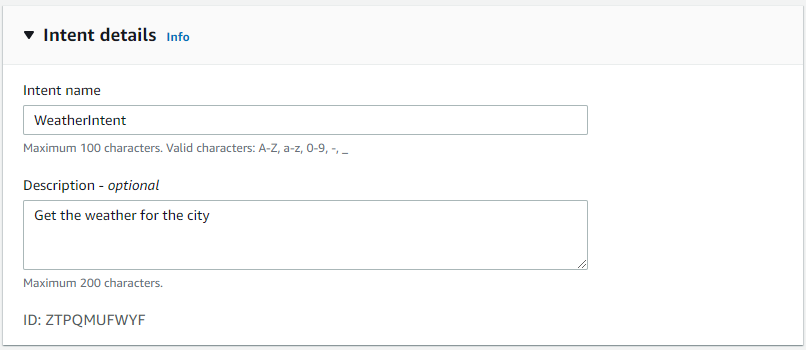
- Finally, click Done to create the bot. That brings us to the intended creation. Provide a name and description for the new intent.
- Scroll down, to slots, and click on “Add slot”
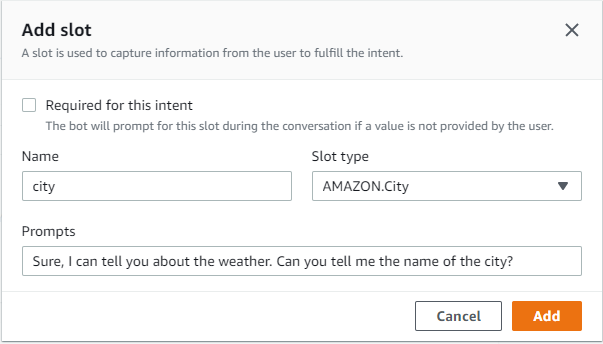
- Expand the “Prompt for slot: city” to provide more details. Click on “Additional options”.
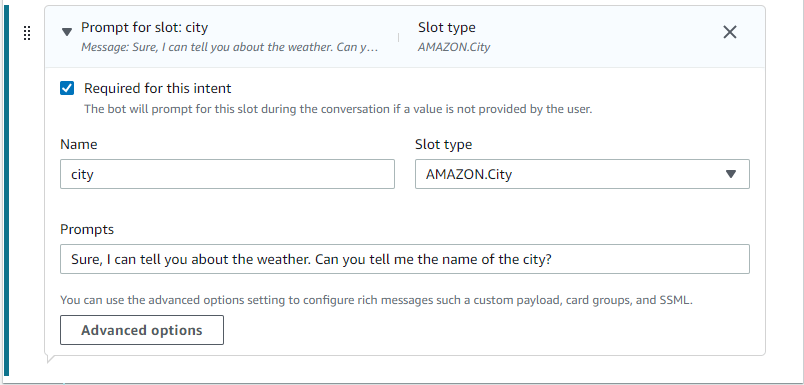
- Scroll down on the popup that opens on the right side of the screen, to provide the slot capture success response.
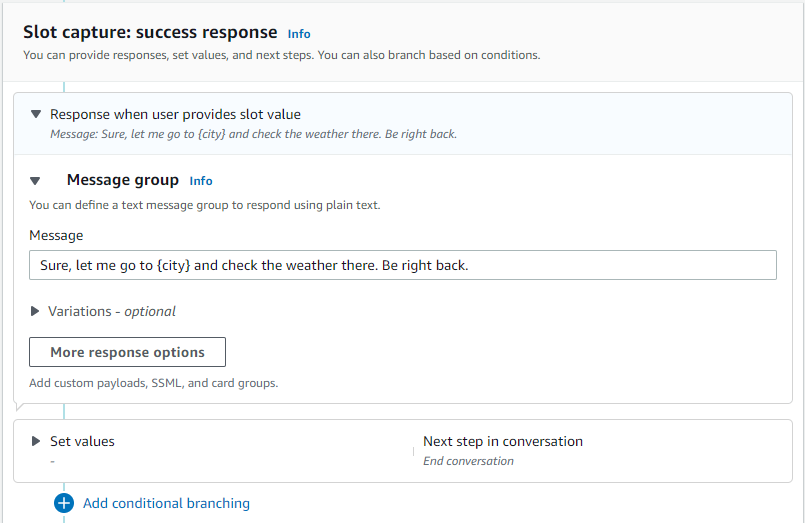
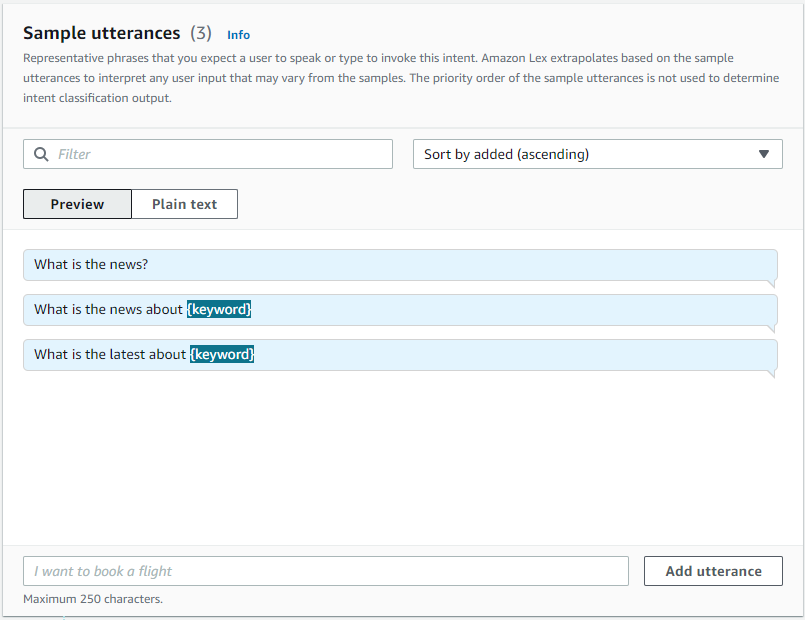
- Click on “Update Slot”. That will get you back to the intent configuration. Scroll up again, and add Sample utterances. Type in the text field and click on “Add utterance” to add individual utterances. Note that {city} in curly braces is related to the slot — city that we added above.

- Now scroll down further to enable fulfillment.

- Click on “Advanced options”. That opens a popup on the right half of the screen. Select the check box to “Use a lambda function for fulfillment”
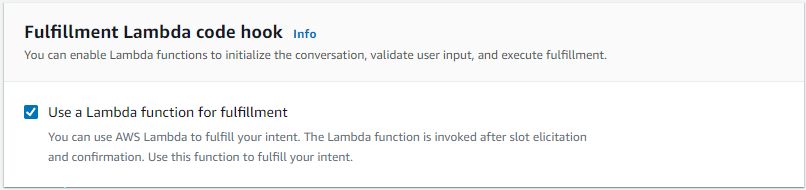
- Click on “Update options” to close the popup and get back to the intent configuration. Click on “Save Intent” and then click on “Build” to build the chatbot. The build takes some time. Once it is done, add another intent for getting news related to a keyword. The same steps as above, with minor differences. This time, the slot is “keyword,” and its type is alphanumeric.
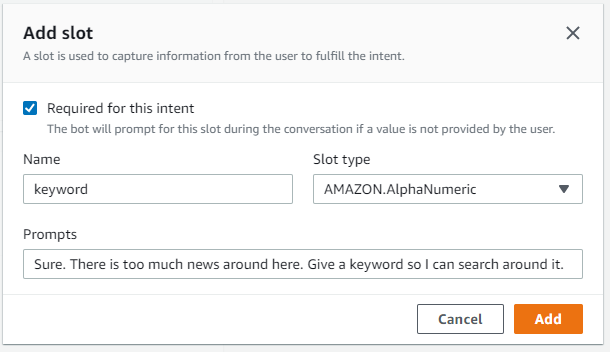
- The utterances should be related to the news.
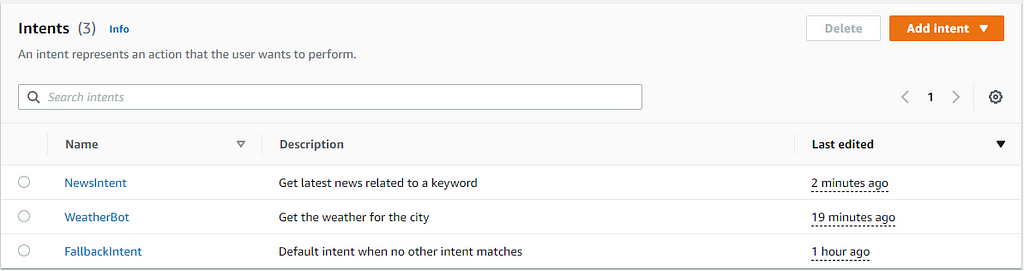
- Again, save the intent and build it. Confirm the list of intents in the bot. Note that there is a third intent that we did not create. This is the Fallback intent, which is triggered when the bot is not able to classify our request into any of the other intents. If our bot frequently lands here, it means we need to enrich the set of “Sample utterances”. Lex is capable of extending the set of utterances we provide into a more generic collection. However, it makes sense to apply minds here to do our best in providing the data set. That is one of the points that differentiate a well-crafted bot from a poorly developed one.
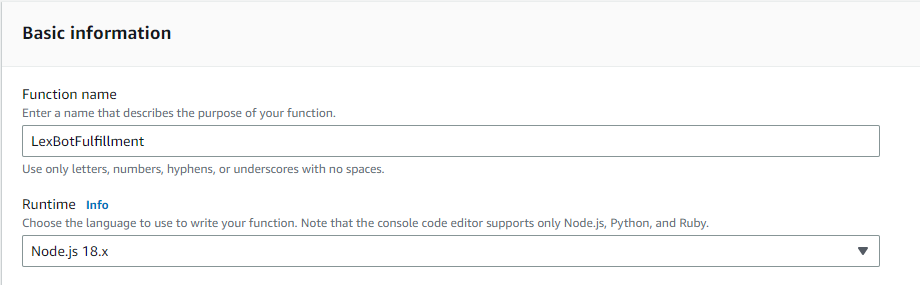
- Now, we have to work on the Lambda function that can fulfill our intent. So jump to the Lambda console and create a new Lambda function. Give it a name and choose Runtime as NodeJS. Leave everything else as default and click “Create function”.
- Check out this link for the required source code in the Lambda function. Clone or download the repository. There is a deploy.zip file that must be uploaded to the Lambda function. On the lambda code tab, click on “Update from” and upload this zip file into the lambda function. The Lambda function uses public APIs for the weather and news. You will have to visit those websites and get the API keys for them. It is simple and free. Once done, add those keys to the lambda environment. Note that the lambda environment variable is not the best place to save API keys. However, it is okay for a demo application like this.
- Deploy it, and we are ready to go. Now come back to the Lex console, where the bot is ready for us. Click on Test, and it will open a popup.
- Click on the gear icon to open the settings. It will open another popup for the settings. There, add the Lambda function that should process the fulfillment requests.
- Type into it to see how our bot works. Here is my conversation with the bot.
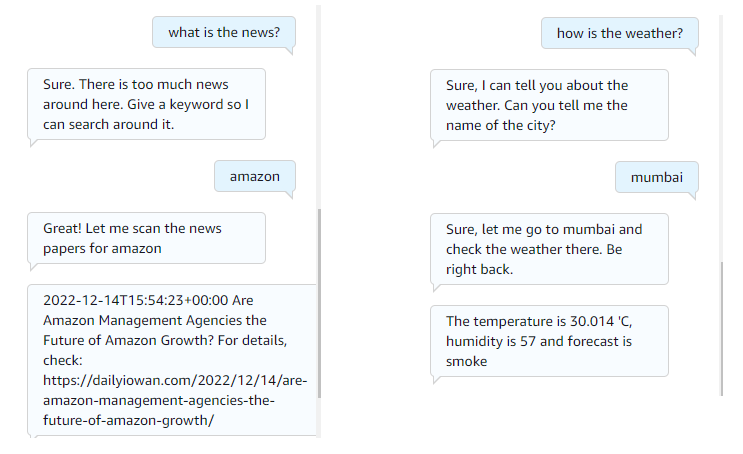
Wow! Try out different ways of asking the same question. If something fails, try to update the intent utterances and save the intent and build the bot again.
We can easily integrate this with our website or mobile app using AWS Amplify.
Improving the bot
That was good for a simple demo bot. It gives a glimpse of what we can do with Lex. Obviously, there is a lot more to Lex and chatbot development. For example, we can configure several other aspects of the intent. The confirmation, closing remarks, etc. We can build up the session context as the user chats with the bot. So, the user can refer to an object used in a few commands before. For example, the user can ask about the weather in a city. Then ask for news with a pronoun. The bot can “remember” the context and give the news about the same city. Or the user can ask about the weather after a few minutes — how is the weather now? The bot can remember the previous request and fulfill it without asking for the city again.
These are the interaction aspects of the bot. We can also enhance it functionally. For example, instead of invoking free APIs for the news and weather, we could have a bot that queries the real prices of the share market. The user can just query the share prices and instruct a buy or sell from the chat console.
And, of course, we can use a voice interface to make this even more interesting. In the above example, we have used the text-only interface. We can enable a voice to make it even more interesting.
The sky is the limit for the variety of use cases and possibilities we have with the Amazon Lex bots. It is an absolutely trivial task to configure and get the basic structure working. Once it is ready, we can add more and more features to it.
Lex vs. ChatGPT
ChatGPT has hit many headlines (and also many minds) in the last few weeks. However, there is a big difference between the two. ChatGPT no doubt has great features for generating awesome text content. However, when it comes to functionality, utility, and configurability, it is far behind Lex.
Functionality
Amazon Lex is a fully-featured chatbot platform that allows developers to build, test, and deploy chatbots for various applications. It includes natural language understanding (NLU) and automatic speech recognition (ASR) capabilities, as well as integration with other AWS services. ChatGPT, on the other hand, is an open-source chatbot toolkit based on the GPT-3 language model. It is designed for generating human-like text and can be used to build chatbots that can hold conversations with users.
Customization
Amazon Lex offers a high level of customization, allowing developers to fine-tune the chatbot’s behavior and responses based on their specific needs. ChatGPT, on the other hand, is more limited in terms of customization. It generates text based on the input it receives, but developers have less control over the specific responses the chatbot provides.
Integration
Amazon Lex integrates seamlessly with other AWS services, such as Lambda and Amazon Connect. This allows developers to build chatbots that can access data from other AWS services and perform various actions. ChatGPT, on the other hand, does not have this level of integration with other tools and services.
Overall, Amazon Lex is a more comprehensive chatbot platform, while ChatGPT is a more specialized tool that is primarily focused on generating human-like text. Both can be useful for building chatbots, but the best choice will depend on the specific needs and goals of the project.
Amazon Lex: Conversations in the Cloud was originally published in Towards AI on Medium, where people are continuing the conversation by highlighting and responding to this story.
Join thousands of data leaders on the AI newsletter. It’s free, we don’t spam, and we never share your email address. Keep up to date with the latest work in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.
Related posts
Recent Posts
")



")


