
 Logo:
Logo:  Areas Served:
Areas Served: 
From Pixels to Words: How Model Understands? 🤝🤝
Last Updated on June 18, 2024 by Editorial Team
Author(s): JAIGANESAN
Originally published on Towards AI.
From Pixels to Words: How Model Understands? 🤝🤝
From the pixels of images to the words of language, explore how multimodal AI models bridge diverse data types through sophisticated embedding communication. 👾
In this article, we’ll dive into the world of multi-modal models, where numerical representations of different data types come together to achieve a common goal. Specifically, we’ll explore how image feature representations are understood through text descriptions. My main objective is to examine how embeddings from different modalities are used to achieve the objective of a model or use case.
As a bilingual person, I can understand and translate both Tamil and English. How can I do this? It’s because I’ve learned the words, meanings, semantic, and syntactic representations of both languages. For me, both languages are just a means of communication, and I can switch between them effortlessly.
Similarly, we use multimodal models to learn from modalities like image, text, audio, and video. Everything is represented as vectors or numerical representations. After all, AI is built on mathematical concepts.
AI is not a Magic, It’s a Math ✌️
If you’re unfamiliar with how transformer models work, I recommend checking out my previous article, “Large Language Model (LLM): In and Out,” to understand the topic completely.
Large Language Model (LLM)🤖: In and Out
Delving into the Architecture of LLM: Unraveling the Mechanics Behind Large Language Models like GPT, LLAMA, etc.
pub.towardsai.net
Let’s dive into the world of multi-modalities and explore how ML models represent and understand different modalities.
In this article, we’ll explore three key concepts in multi-modal models: 😁
👉 Joint embedding space,
👉 Cross-attention,
👉 Concatenation and fusion.
Let’s start with the joint embedding space 🐎
1. Joint Embedding Space: A Shared Space for Images and Text ✌️

Image 1: Left side → CLIP Architecture, where the Text encoder is transformer encoder architecture, and the Image Encoder is the Vision Transformer. The T_1, T_2, T_3, .., T_N represents the Text embeddings and I_1, I_2, I_3, … I_N represents the Image embeddings.
By Changing the last linear layer in the text and image encoder’s architecture, we get the same size of vector (e.g.: 1024 dimensions). This Image and Text vectors have the information of Image and text respectively.
You might be aware of OpenAI’s CLIP [1](Contrastive Language Image Pre-training) model (Image 1), which is built upon the idea of a shared embedding space where both images and their textual descriptions are projected. This means that each image and its corresponding textual description are mapped to the same embedding space.
By mapping images and text into the same space, CLIP enables direct comparison and combination of their representations. Images and their corresponding text are expected to have similar embeddings if they are semantically related (e.g., an image of a car and the text “a car”).

1.1 How CLIP Maps Images and Text to a Shared Embedding Space
CLIP uses a transformer architecture for both text and image modalities. Text descriptions are converted into embedding vectors using a transformer encoder architecture, while images are represented as embedding vectors using a Vision Transformer (ViT).
CLIP is trained using a contrastive learning objective, where the model learns to bring similar image-text pairs closer together in the embedding space while pushing dissimilar pairs farther apart.
For example, The text encoder and Vision Transformer convert text descriptions and images into numerical representations using their respective architectures. The shared embedding space requires that both textual description vectors and Vision Transformer output vectors have the same dimension.
You might be familiar with cosine similarity, which measures the similarity between two vectors. In CLIP, we use a similar approach, but in the opposite direction.
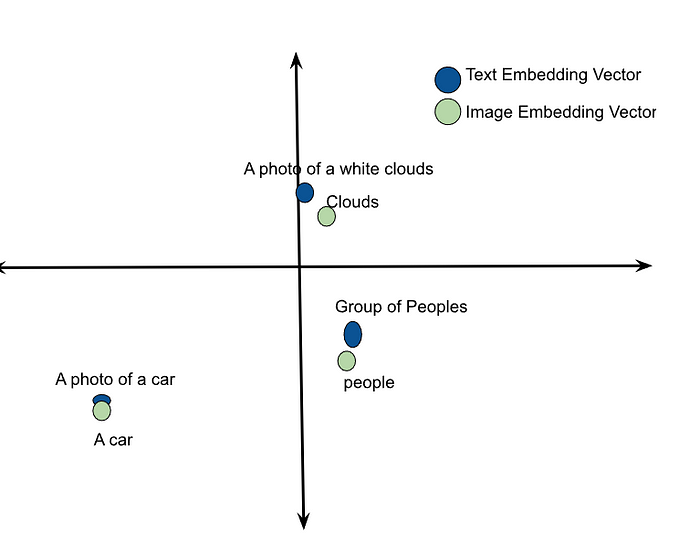
Before training CLIP, the text description vector and image feature vector may be in different locations in the joint multi-dimensional space, as shown in Image 2. Our training objective is to make the vectors of similar pairs come as close as possible and push dissimilar pairs apart.
We achieve this by assigning labels to similar pairs like (T_1, I_1), (T_2, I_2), … (T_N, I_N) 1, and dissimilar pairs like (I_1, T_2), (I_1, T_3), (T_1, I_3), … -1. By keeping this objective and loss function, we tweak both the text encoder and Vision encoder to generate the most similar vectors for similar image-text pairs as shown in Image 3. In this way, the model learns the representation of images and text.
This training encourages the model to understand the semantic relationships between images and their associated text. Although the different modalities’ vectors may not be the same, they will be very close in the joint embedding space.
Once trained, CLIP can perform tasks such as cross-modal retrieval, where it retrieves images based on textual queries or vice versa, and its ability to generalize the unseen data depends on how well the understanding of semantic relationships in joint embedding space.
2. Cross Attention: Relating Information between Different Modalities 🐊
2.1 Cross Attention in Vanilla Transformer
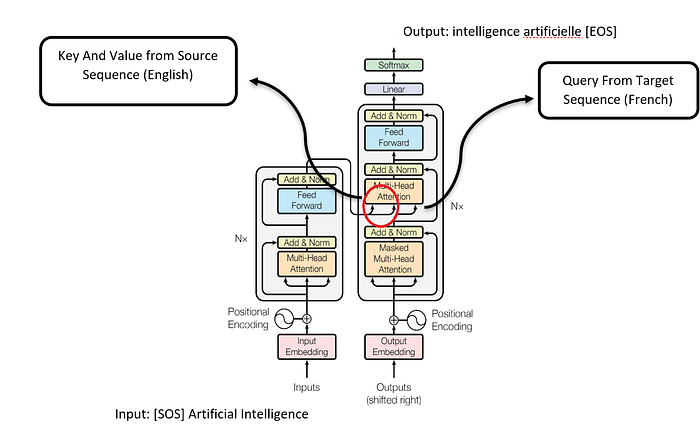
As we know, the Attention is All You Need [2] paper clearly explains the cross-attention mechanism (Image 4). In the vanilla transformer, there are two components: the encoder and the decoder. The encoder deals with one modality (English), while the decoder deals with another modality (French). This architecture is essentially a language translator, and we can build models to translate sentences from English to French or any language to any language.
Note: During training, the virtual tokens [SOS] and [EOS] in image 4 are not universally necessary for all types of training. This is because the model learns from the context of the training data and calculates its loss based on the sequence itself. It doesn’t need explicit markers to show where a sentence starts and ends. But, during inference, these tokens are helpful for indicating the start and end of the input sequence.
Even different languages are treated like different modalities. The cross-attention mechanism relates information between two different sets of embeddings, such as the source sequence (English) to the target sequence (French).

In cross-attention, the query comes from the target sequence (French), and the key and value come from the source sequence (English). This is where the two embeddings meet. You might be aware of how the self-attention mechanism happens, as shown in image 5.
In the same way, the cross-attention happens with different modalities’ embeddings; as you can see in image 5, the Query is French word Embeddings, and Key and Value are English word representations that give the decoder attention layer output. This helps us to generate the next French word.
If you don’t understand how transformer architecture works, I again recommend you check out my article LLM: in and out.
2.2 Stable Diffusion: A Text-to-Image Model

Before we dive into that, let’s give a brief explanation of diffusion functions. Diffusion is a generative model architecture where noise is added to the image. This is done by adding a small amount of noise at every step till the image becomes complete noise. It is a stochastic process called forward diffusion. There is no learning in the forward diffusion.
In Reverse Diffusion Noise is gradually removed to generate an input image. In stable diffusion, the dataset contains image-text pairs. Noise is added in the forward diffusion process. In reverse diffusion, the U-Net comes into play, acting as a noise predictor. It predicts the noise in each step and removes that noise from the distribution to generate the input image.
2.2.1 Cross Attention in U-Net Architecture 👻
In the U-Net architecture, cross-attention happens between the latent image/noise (query) and the text embedding (key and value). You may wonder how it helps. During inference, there is only reverse diffusion happening, an Image will be generated from the latent noise. The noise predictor U-Net was trained based on text and image embeddings cross-attention. So, the U-Net removes the noise based on the text description (key and value embeddings). The model Learns the Images and text, features and representations. This allows the model to generate the images using the text descriptions.
3. Concatenation and Fusion: Combining Multiple Modalities 🎃
3.1 Fusion Method (Addition)
Let’s discuss the fusion method, which is used to combine multiple modalities like text, image, and audio to create a unified representation. As we mentioned earlier, the Attention is All You Need [2] paper provides a great example of fusion. In this paper, we deal with two embeddings: word embeddings and positional embeddings. To create the input embedding, we simply add the word and positional embeddings element-wise.

The positional embeddings provide positional information in the sequence, while the word embeddings provide information about the word. By combining these two embeddings, we create an input embedding that contains both word and positional information.
Similarly, we can use different modalities like text, image, and audio to combine multiple information. For instance, average sentence embedding is a great example of how word embeddings can be added to create a combined representation.
3.2 Understanding Concatenation in Vision Language Models
I want to give examples from two research papers for the concatenation of different modality embeddings.
3.2.1 IMAGEBERT: A Model that Combines Image and Text Embeddings [4]

IMAGEBERT is a vision language model that takes both image and text embeddings as input. The model uses a faster-RCNN model to capture image features from regions of interest (ROI). For Text embeddings, it uses transformer architecture.
The model concatenates the image features embeddings, text embeddings, and special tokens like [CLS] and [SEP]. The image embedding and text embedding are separated by a [SEP] virtual token as shown in Image 8.
Another example of adding (Fusion method) different modalities’ embeddings can be seen in Image 8. In this image, three types of embeddings are added element-wise: Linguistic Embeddings, Segment Embeddings, and Sequence Position Embeddings.
This process involves adding corresponding elements of each embedding together to create a new, combined embedding. This combined embedding represents the fusion of information from different modalities, allowing the model to capture complex relationships between language, segments, and sequence positions.
This model can be applied to various tasks, including masked language modeling (MLM), masked object classification (MOC), masked region feature regression (MRFR), and image-text matching (ITM). It can even answer questions based on visual information (visual question answering).
3.2.2 What Matters When Building Vision-Language Models? [5]

Another vision language model that answers questions related to images is “What Matters When Building Vision-Language Models?” This model uses a vision transformer to capture image features. For text, it uses a Transformer encoder as shown in Image 9.
In this architecture, The Vision encoder captures features from the image. The encoder results in hidden states. The Pooling Layer is nothing but, there will be N number of hidden states coming from the input Image, All these hidden states pooled into a certain number of hidden states. This shorter sequence of hidden states will represent the features and variabilities in the input image.
The modality projection in the image encoder helps project the image feature’s hidden state into the same hidden dimension as the text.
This allows the model to concatenate the image features directly to the sequence of text embeddings, which is then passed as input to the Large language model. The objective of the model is to answer questions from images, so the output is only text.
We’ve reached the end of this article, where we’ve explored a little bit, of the fascinating world of multi-modal models. Throughout this article, we’ve learned how different modalities’ features are represented as vectors, and how these vectors are used together to achieve the objectives of various use cases.
By understanding how to combine and utilize embeddings from different modalities, we can unlock the potential of multi-modal models to solve complex problems and enable innovative applications.
Thank you for reading this article. If you found my article useful 👍, give it a clap👏! Feel free to follow for more insights.
Let’s also stay in touch on www.linkedin.com/in/jaiganesan-n/ 🌏❤️to keep the conversation going!
References :
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, CLIP Research Paper Learning Transferable Visual Models From Natural Language Supervision (2021)
[2] Ashish Vaswani, Noam Shazeer, Niki Parmar, Attention is All You Need Research Paper (2017)
[3] Robin Rombach, Andreas Blattmann, Latent Diffusion Research Paper, High-Resolution Image Synthesis with Latent Diffusion Models (2021)
[4] Di Qi, Lin Su, Jia Song, ImageBERT Research Paper, ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data (2020)
[5] Hugo Laurençon, Léo Tronchon, Matthieu Cord, Idefics 2 Research Paper, What matters when building vision-language models? (2024).
[6] Stable Diffusion Working Mechanism ( 2024 ), How does stable Diffusion work?
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts

