


: Zomato Web Scraping with Selenium")
Web Scraping with Selenium — Foods Around Jakarta (Part 1): Zomato
Last Updated on January 7, 2021 by Editorial Team
Author(s): Rizqi Eka Maulana
Wondering what kind of foods (and drinks) The Big Durian has to offer? Let’s scrape it with Selenium!
Disclaimer: This article is only for educational purposes. We do not encourage anyone to scrape websites, especially those web properties that may have terms and conditions against such actions.
Jakarta is now entering the 8th month of the COVID-19 pandemic, and from the way things stand right now, it’s not getting any better. Our government is imposing on-and-off social restrictions in the city.
People are suggested to stay-at-home and work-from-home, non-essentials industry are recommended to be closed temporarily, and yes, that’s including the restaurants or dessert parlors that you love!
I used to hang out at the mall near my place and explore the restaurants there every weekend last year, and now I can’t. Fun fact, Indonesian people love to flock to restaurants, eating out with their family, friends, or date. It’s a part of our culture. Now, the pandemic has drastically changed our eating out culture.
To cook, or not to cook, that is the question.
When the social restriction regulation is turned on, ‘eating out’ is thrown out the window. We can buy the ingredients, then cook by ourselves. Therefore the ‘to cook’ option.
The ‘not to cook’ option: buy takeaway food, or even safer, order food online. As a Jakartan who tries his hard not to contribute to new COVID cases in this city, I sometimes order my food online, thanks to the rise of food-delivery tech in Indonesia, GoFood or GrabFood (similar to Uber Eats)
I found myself keep ordering the same foods from the same restaurants through GoFood over and over again. When I craved chicken, I found myself ordering food from KFC and McDonald’s (YES, McD serves chicken in Indonesia). When I craved for Soto, I found myself ordering food from Soto Kudus Blok M Tebet, etc.
There are literally thousands of restaurants in Jakarta, and over the course of 8 months of the pandemic, I only ordered from less than 20 restaurants in Jakarta.
Realizing that, and also reading Regita H. Zakia’s “Foods Around Me: Google Maps Data Scraping with Python & Google Colab,” I am attracted to expand what she’s done to a bigger scale.
How many kinds of foods this city has to offer actually? How many restaurants are there that provide my Indonesian favorite foods, Soto and Rendang? So many questions.
So this time, I am not going to scrape food services industry data from Google, but from Zomato. Why? That’s where Jakartan Foodies place their rating and write their reviews. It’s a credible source for food references.
In order to do so, I am gonna write a Python script with the Selenium library to automate the scraping process through thousand of restaurant pages, then build our dataset with Pandas.
What Data Are We Going To Scrape?
First thing first, though, since there is a lot of data in Zomato, we have to list the data that we need in our little research. After checking the Zomato page, I decided that I will scrape:
From The Search Page:
- Web Address of All Restaurants in Jakarta Area
- Web Address of Restaurants that serve Delivery Service in Jakarta Area
From The (Individual) Restaurant Page:
- Restaurant Name
- Restaurant Type
- Restaurant Area
- Restaurant Rating
- Restaurant Review
- Restaurant’s Average Price for 2
- Restaurant Address
- Restaurant’s Additional Info/Facilities
- Restaurant Latitude & Longitude
Basic Preparation
Since we’re gonna use Selenium, of course, the first step is to make sure we have the necessary library, Selenium. Since Selenium is originally a library to automate the process in web browsers, we’re gonna need a real browser installed on your computer and a browser driver to control it.
I will use Google Chrome this time, and you can download the browser driver here.
Inspect the Search Page
List of Web Address of All Restaurants in Jakarta Area
Selenium is a very handy library to find HTML elements using various means, like id, class name, tag name, link text, XPath, or CSS Selector. With this guide, I’ll also cover various issues that I found when I scraped Zomato Page, then explain how to tackle them.
Let’s look at the search page below. If we pin our location to Jakarta, currently there are 1002 pages, containing around 15 restaurants on each page. That may mean Jakarta has around 15.000 restaurants! Wow, that’s incredible!
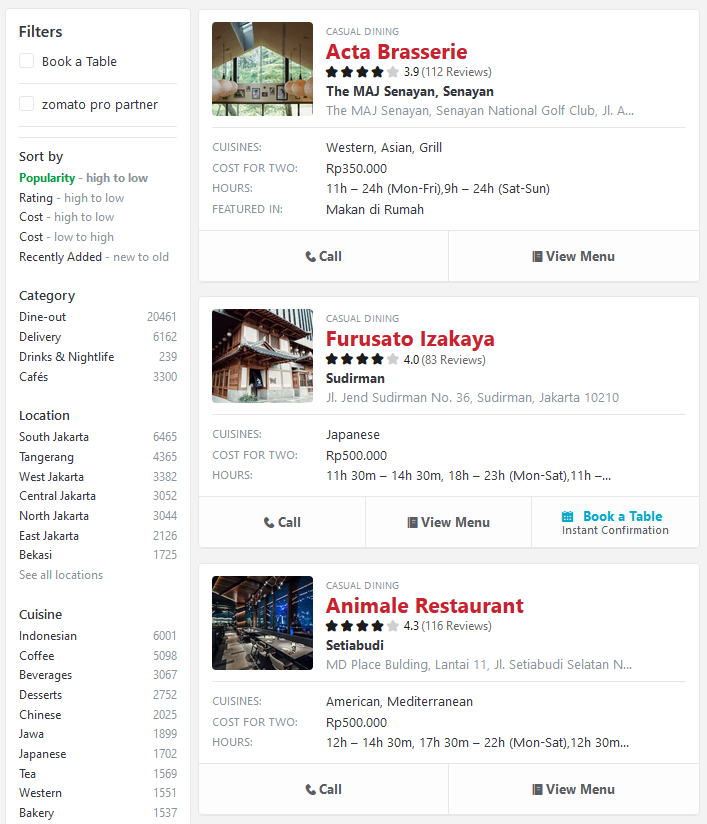
Now, what we want to scrape is only the web address on each search page, so we can open it individually later. Imagine opening more than 1000 pages manually, surely that will be pretty exhausting (and boring, to be honest). Selenium to the rescue!
Before writing the Python code, we have to know the difference between 2 Selenium “Find Element” Tools:
- Find Element: Find a single element located by stating a specific HTML element locator.
- Find Elements: Find a list of elements located by stating a common HTML element locator among the elements that you want to find.
In our case, since we want to scrape all the website addresses on each search page, we will use the find elements tool. Okay, cool, then how to identify the website addresses in each of those restaurant lists?
We have to inspect the page’s HTML, then find the common HTML element among all web addresses on each search page.
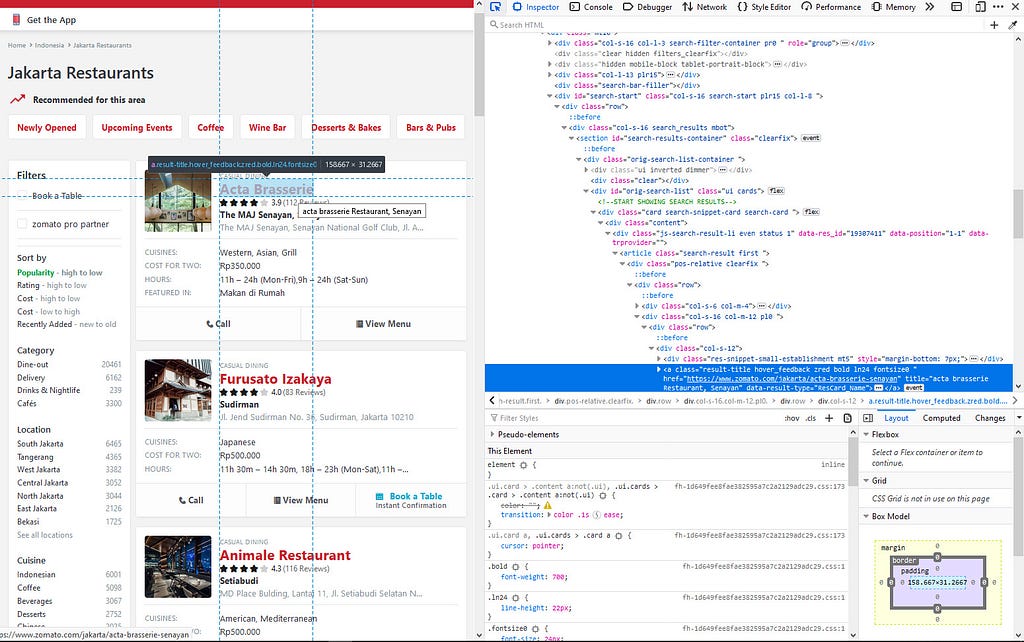
After I checked all the web addresses on this search page, I concluded that one of the common HTML elements of the web address is their class name.
Now, we can get the list of Selenium Web Elements by writing code like this:
url_elt = driver.find_elements_by_class_name("result-title")
Seems easy enough, but our target is the website address, right? Well, we just need to write additional code to extract the URL page’s attribute (href) from each Web Elements by looping through the list.
With the above code, we’ll be able to create a list of web addresses. Now, let’s combine it with codes to loop through search pages in Zomato, all 1002 pages.
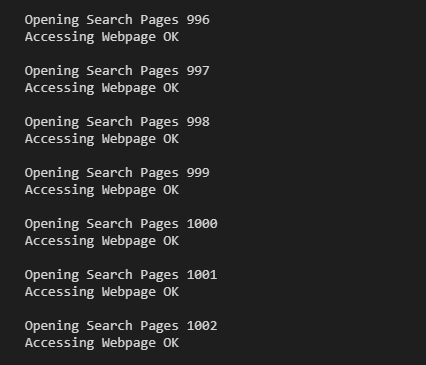
We’ve written the basic code to scrape the web address, but we can improve it further by writing the code to show the progress of web scraping, like this.
By adding 2 simple print codes, we can get informative notifications each time we successfully loop through search pages.
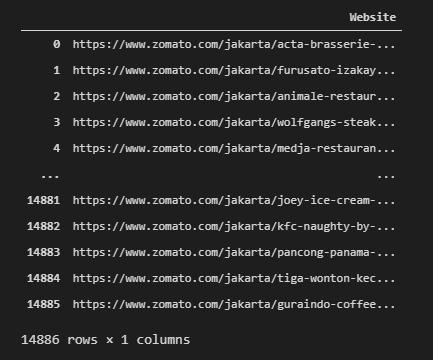
Don’t forget to convert the list to Pandas DataFrame so we can make the data arranged neatly.
out_df = pd.DataFrame(out_lst, columns=['Website'])
Outcome:
List of Web Address of All Restaurants that serve Delivery in Jakarta Area
Next, we’re gonna do exactly the same thing to get the list of restaurants that service delivery in the Jakarta Area. The only difference is the search page’s URL and the number of search pages that we want to loop through.
Outcome:
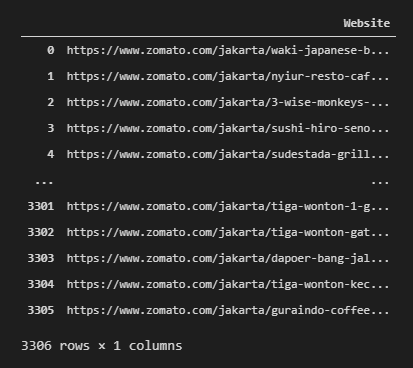
Remove Duplicate Web Adress
Now, we got 14886 Restaurants in the Jakarta Area, and 3306 of them serve delivery service. Before delving deeper into web scraping, we have to make sure we don’t have duplicate entries because the search page result sometimes contains repeating entries.
We can easily detect that using a very simple pandas method, duplicated.
# Observe whether we have duplicate websites or not
out_df[out_df.duplicated(['Website'], keep='first')]
Using the above code, we will see the list of web addresses that are duplicated in the DataFrame, except for the first entry of the duplicated ones.
Let’s make a new DataFrame without duplicated values, both for DataFrame for all restaurants and DataFrame for with-delivery restaurants.
# Make A New DataFrame - without duplicated values
out_df_nd = out_df[~out_df.duplicated(['Website'], keep='first')] outdlv_df_nd = outdlv_df[~outdlv_df.duplicated(['Website'], keep='first')]
Inspect the Individual Restaurant Page
We now have unique web addresses of ~14500 restaurants all over Jakarta. By using this, we can loop through each web address and scrape the information that we need. Let’s continue writing more code!
Restaurant Name
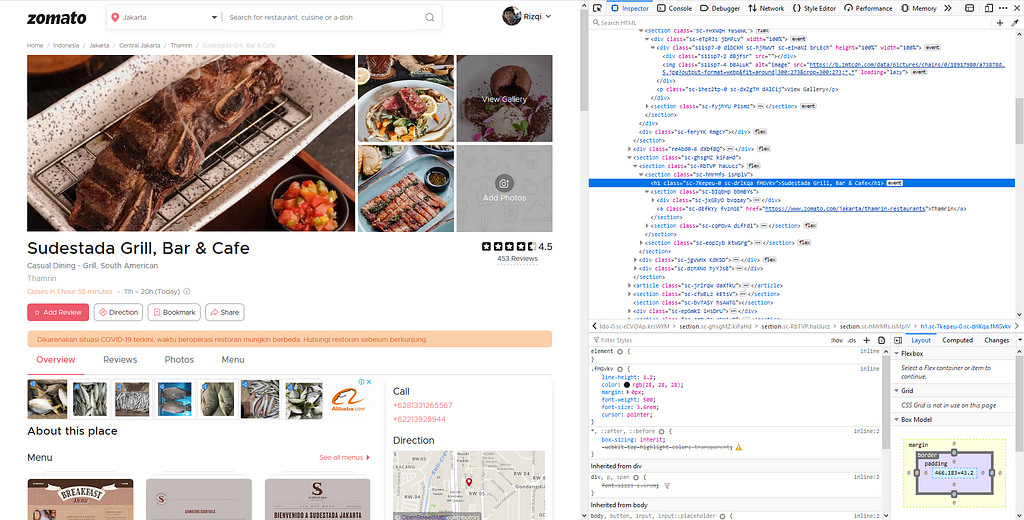
It’s pretty obvious from the picture above that Restaurant Name is tagged with h1 in HTML code. Previously, we find elements in HTML code using the class name. Now we’re gonna find it using tag name.
name_anchor = driver.find_element_by_tag_name('h1')
Never forget that find element return a Selenium Web Element, so we have to extract it further to get the data that we need. In our case, we can do so by using this code.
name = name_anchor.text
Here is the complete code to scrape the Restaurant Name:
After scraping restaurant pages for a few moments, or a few hours, perhaps your program will stop, showing an error message because some page’s h1 element couldn’t be scraped. In Zomato case, there are pages like these:
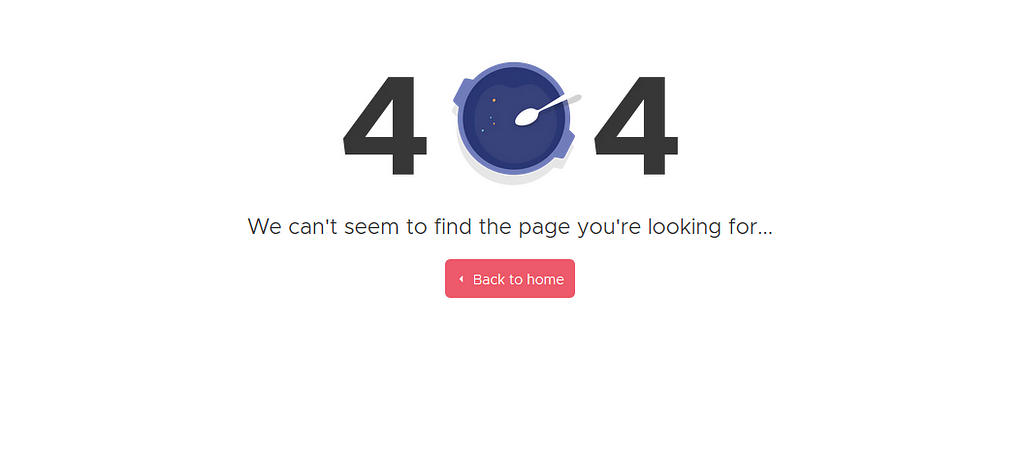
If our browser hit this page, the program will stop because it couldn’t scrape its h1. We can easily tackle this by using another function from the Selenium library: NoSuchElementException. If we don’t find the web element that we want, combined with the if statement, we can reroute the program to just pass it. Firstly, we must import this function at the beginning of the code.
from selenium.common.exceptions import NoSuchElementException
After that, we will use a try-except statement to implement our logic to the program. If we don’t find any h1 element, just write “404 Error” to Restaurant Name, then pass to the next page.
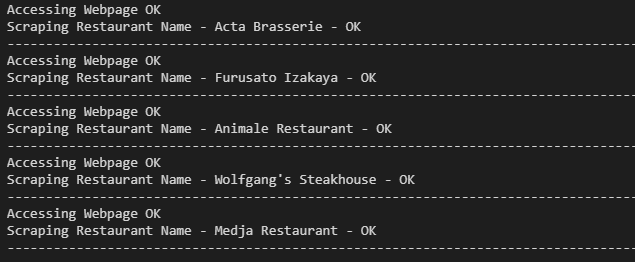
Furthermore, like what we did before, let’s write some print codes to show the progress of web scraping.
Outcome:
Restaurant Type
Next step, we want to scrape the type of each restaurant in Jakarta.
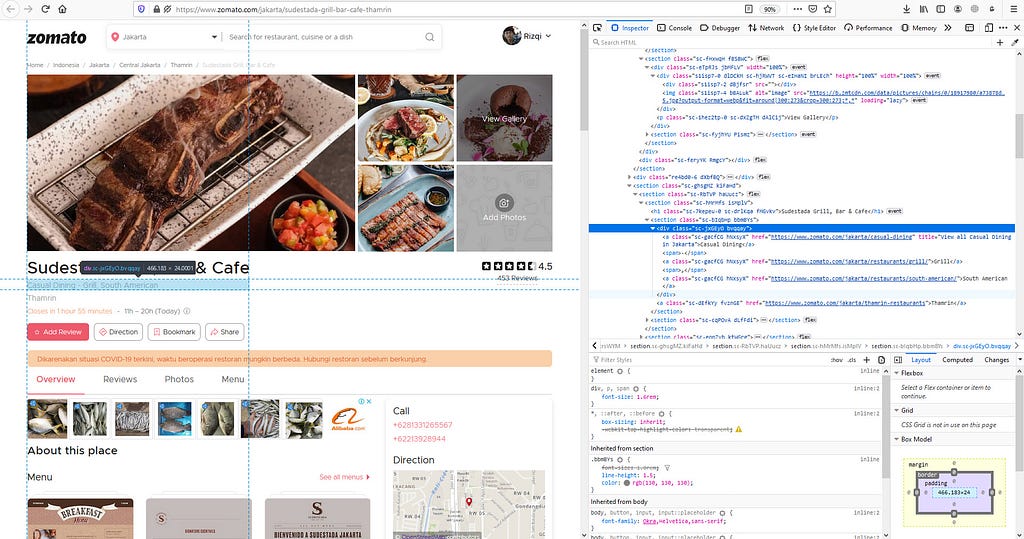
Like Web Address, we’re gonna use find elements because there are multiple elements that we want to scrape. The question is, what locator we better use to find this element? If we look closely, the tag name (div) isn’t unique enough, while the class name (sc-jxGEy0) can be different in some restaurant pages. That’s why we couldn’t find these two locators.
This is where XPath becomes very handy. What is XPath, though? It stands for XML Path Language, which we can use to locate the element we want to scrape because the structure of Zomato’s Restaurant Page is mostly the same.
How do we get this helpful XPath? Simply right-click the HTML code that you want, then click Copy -> XPath.
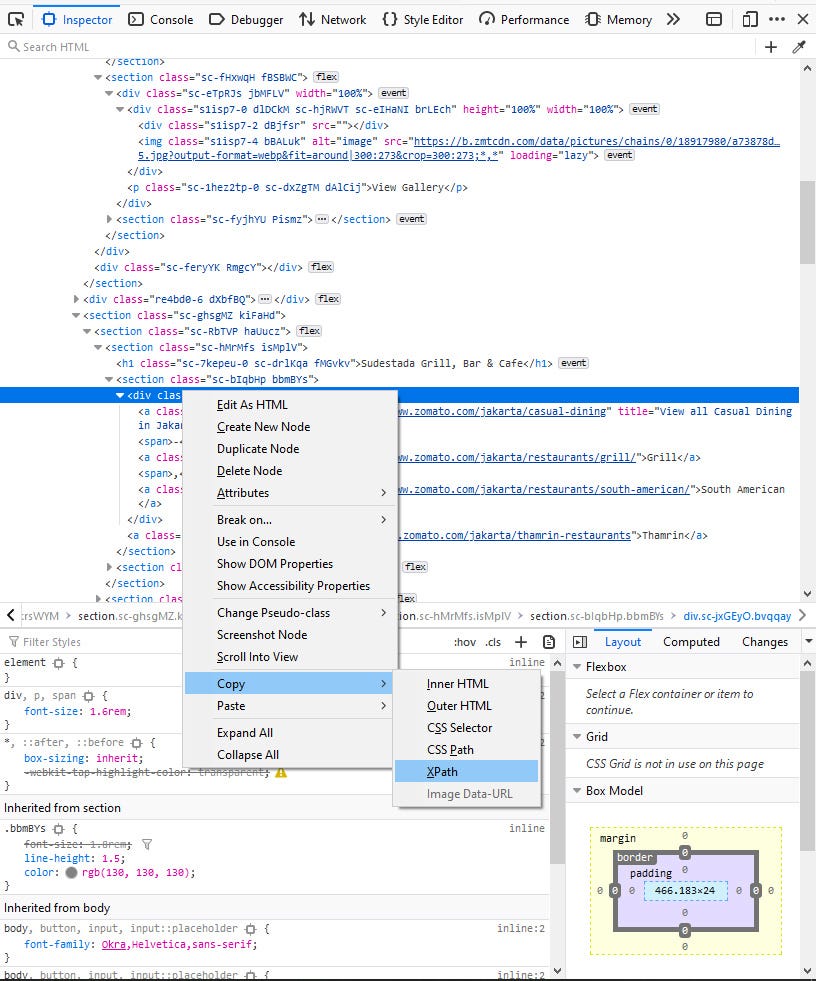
Now that we have the XPath, just paste it into your coding program, and add this code. Please note that just like rest_name, we have to make an empty list: rest_type in the top.
Restaurant Area and Address
Next, we need to scrape Restaurant Area and Address. This is easier because we only need to scrape 1 element, and just like before, we’re gonna scrape this by XPath.
Restaurant Review and Rating
After we’re done with Name, Area, and Address, let’s move to slightly trickier information to scrape: Review and Rating. As you scrape on, you’ll see that not all restaurants have this information. Just like the restaurant name, we’ll utilize NoSuchElementException.
Restaurant’s Average Price for 2
Up until now, the XPath method is quite handy to scrape the data that we need. Now, for this data, we have to modify our “find element by XPath” with a couple of if-else statements. The reason why, for this specific data, the location in each restaurant page varies.
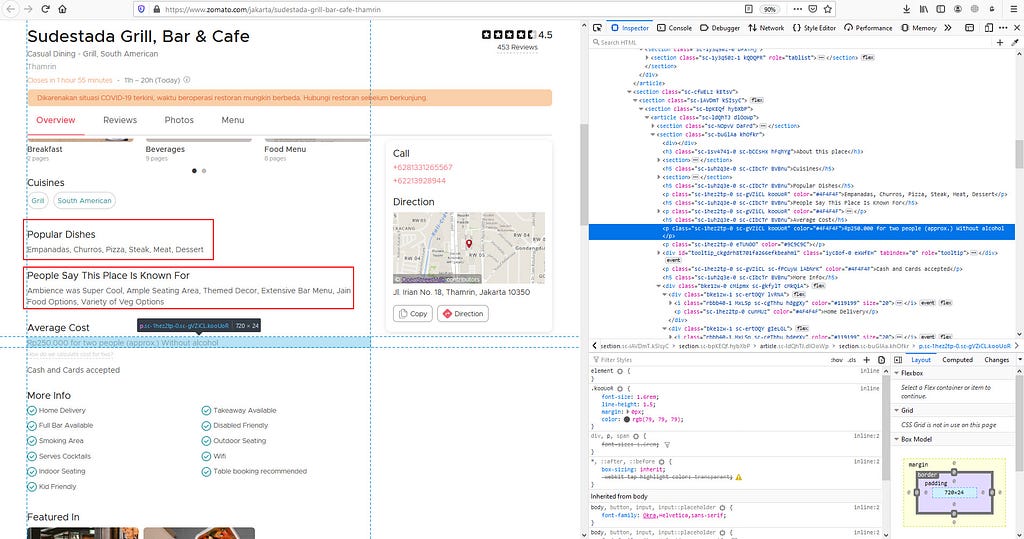
In the picture above, “Average Cost” is located below “Popular Dishes” and “People Say This Place is Known For.” In most Zomato pages, these two pieces of information are not shown. That’s why the location of Average Cost different in the pages that have these two.
We will use a string slice function to check whether the data that we scrape starts with “Rp” / “No” or not. If it doesn’t start with these two strings, we will scrape another XPath.
Let’s implement that logic to our code.
Restaurant Additional Info
We’ve scraped single web elements by various locators, multiple web elements with the same class name, multiple web elements within an XPath. Now we’re gonna learn to scrape an even more unique thing!
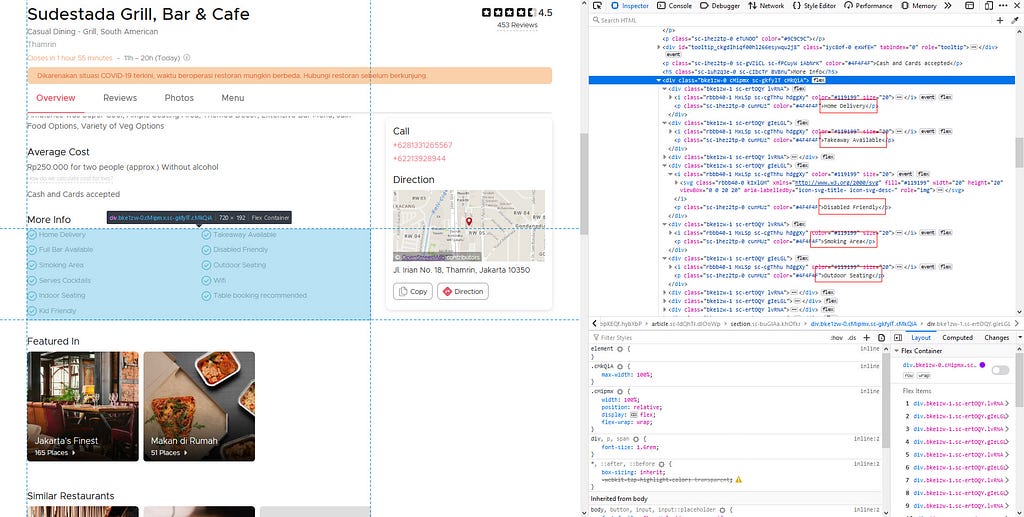
As you can see in the picture above, we want to scrape all the text information that’s included in the blue box. If we see the HTML code on the left, the information is kinda scattered in different codes.
What we will do to scrape efficiently is: find the element of the blue box by XPath, then by using the result, we find multiple elements of the text by tag name p. Here’s the code version of that logic.
Restaurant Latitude & Longitude
This information scraping is no less tricky than before. In order to know why, let’s take a look.
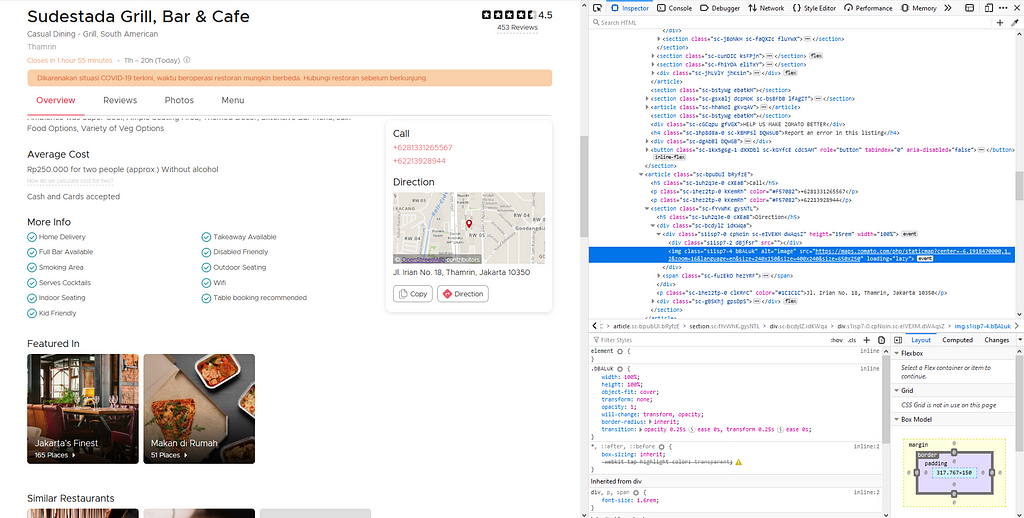
As you see, the latitude and longitude of each restaurant are located in the map’s web address. We don’t need to open the map’s web address to scrape the latitude and longitude.
We can simply extract the web address from the web element, then using the string function available in python, slice it. Voila!
Another Sidenote
Now that we write codes for each data that we want to scrape, we can combine it together to scrape all those information from each page.
But before we do that, we better import another important library that we will use to pause the execution of the program.
Why? Because, depending on the speed of your internet connection and the amount/type of information that we want to scrape, we may have to wait for the browser to completely load the page.
import time
# To delay the execution of next coding line time.sleep(8)
Scrape All Restaurant Data
Knitting all the above codes, we would get this when we run the codes. We can clearly see the progress of the web scraping process with this (and you can also see if there’s some mistake in the scraping process!).
Don’t forget that the results of our scraping are a collection of lists. We need to combine them together to create a compact, tidy dataset.
rdf = pd.DataFrame({"Restaurant Name" : rest_name[:], "Restaurant Type" : rest_type[:], "Restaurant Area" : rest_area[:], "Restaurant Rating" : rest_rating[:], "Restaurant Review" : rest_review[:], "Price for 2" : price_for_2[:], "Restaurant Address" : rest_address[:], "Additional Info" : rest_info[:], "Latitude" : rest_lat[:], "Longitude" : rest_long[:]})
Outcome:
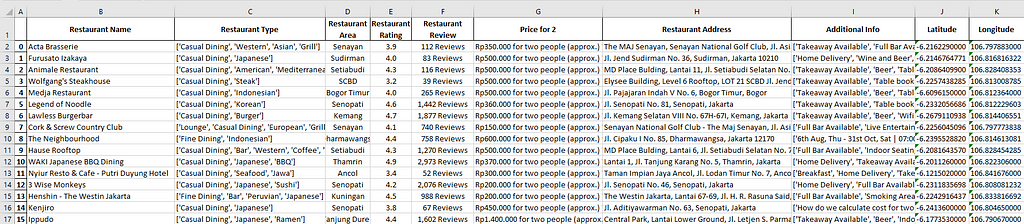
You can see the complete code to scrape the individual restaurant page on Github.
Conclusion
Well, that spreadsheet wraps it up! We now have Jakarta Food Services Industry data that we need from Zomato. In Part 2, I will walk you through the next step, to complete those data with Reverse Geocoding!
Also, for you, I want to say congratulations! You’ve just learned how to scrape Restaurant Data from Zomato. In the process, you’ve also learned to use various techniques to face different kinds of HTML codes.
Moreover, also note that Zomato may also change its HTML structure, so you may have to adapt further if there are such changes. Every website is different. That’s why it’s important to adapt the technique/code to scrape it.
Stay healthy during the pandemic, happy web scraping!
Foods Around Jakarta (Part 1): Zomato Web Scraping with Selenium was originally published in Towards AI — Multidisciplinary Science Journal on Medium, where people are continuing the conversation by highlighting and responding to this story.
Published via Towards AI
Towards AI Academy
We Build Enterprise-Grade AI. We'll Teach You to Master It Too.
15 engineers. 100,000+ students. Towards AI Academy teaches what actually survives production.
Start free — no commitment:
→ 6-Day Agentic AI Engineering Email Guide — one practical lesson per day
→ Agents Architecture Cheatsheet — 3 years of architecture decisions in 6 pages
Our courses:
→ AI Engineering Certification — 90+ lessons from project selection to deployed product. The most comprehensive practical LLM course out there.
→ Agent Engineering Course — Hands on with production agent architectures, memory, routing, and eval frameworks — built from real enterprise engagements.
→ AI for Work — Understand, evaluate, and apply AI for complex work tasks.
Note: Article content contains the views of the contributing authors and not Towards AI.




Recent Posts




")

